@changedi
2019-02-11T07:26:41.000000Z
字数 3996
阅读 3073
阿里云机器学习平台使用——协同过滤推荐算法快速应用
数加
概述
PAI机器学习平台是构建在阿里云ODPS计算平台之上,集数据处理、建模、离线预测、在线预测为一体的机器学习平台。 该平台为算法开发者提供了丰富的MPI、PS、BSP等编程框架和数据存取接口,同时为算法使用者提供了基于Web的IDE+可视化实验搭建控制台。平台目前整合了阿里集团内最先进的算法,为用户提供算法服务。
今天做了一件事情来体验PAI,就是拿最经典的电影推荐场景来做协同过滤算法的测试。
数据准备
电影数据来源于http://grouplens.org/datasets/movielens/,本文的例子采用最小的数据集——MovieLens 100k,总共有100,000个评分,每个评分都是在 (1-5)范围内,供有943个用户对1682部电影进行评分。movielens最新的数据已经扩大了好多,有兴趣的同学可以去实验。
工作流开发
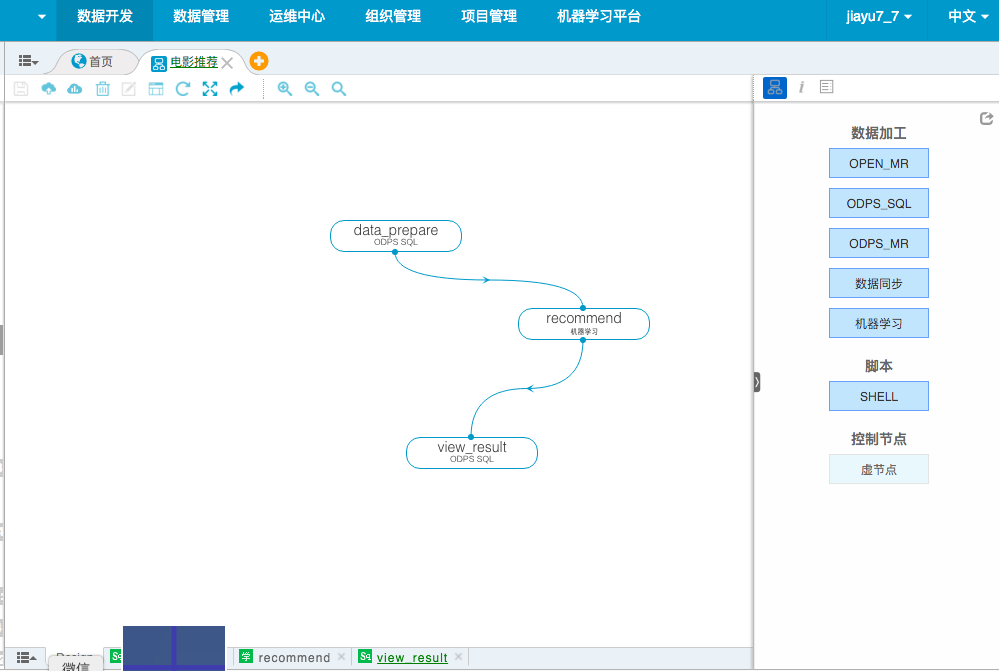
- 在数加DataIDE里建立一个工作流:
电影预测。我们为这个工作流来搭建一个框架。 - 添加第一个节点,一个ODPS SQL节点,命名为
data_prepare,准备预测的输入输出数据。 - 添加第二个节点,一个机器学习节点,命名为
recommend,这个节点用来关联PAI平台的算法工作流。 - 添加最后一个节点,另一个ODPS SQL节点,命名为
view_result,用来查看推荐结果数据。
工作流组成如下:
data_prepare节点的代码如下:
CREATE TABLE IF NOT EXISTS movie_data (user_id STRING COMMENT 'user id',item_id STRING COMMENT 'movie id',rating BIGINT COMMENT 'rating',rating_timestamp STRING COMMENT 'rating timestamp')LIFECYCLE 33;CREATE TABLE IF NOT EXISTS movie_recommend_output (item_id STRING COMMENT 'movie id',recommend_list STRING COMMENT 'recommend list')LIFECYCLE 33;
这里说明一下,movie_data是输入数据表,就是movielens的100k数据集。movie_recommend_output是协同过滤算法的输出数据表。
建完表后很重要的一步是把数据添加到ODPS里,当然方法有上千种,最简单的一种就是直接通过DataIDE提供的数据上传功能。
点击这个红圈里的小图标就能看到了。
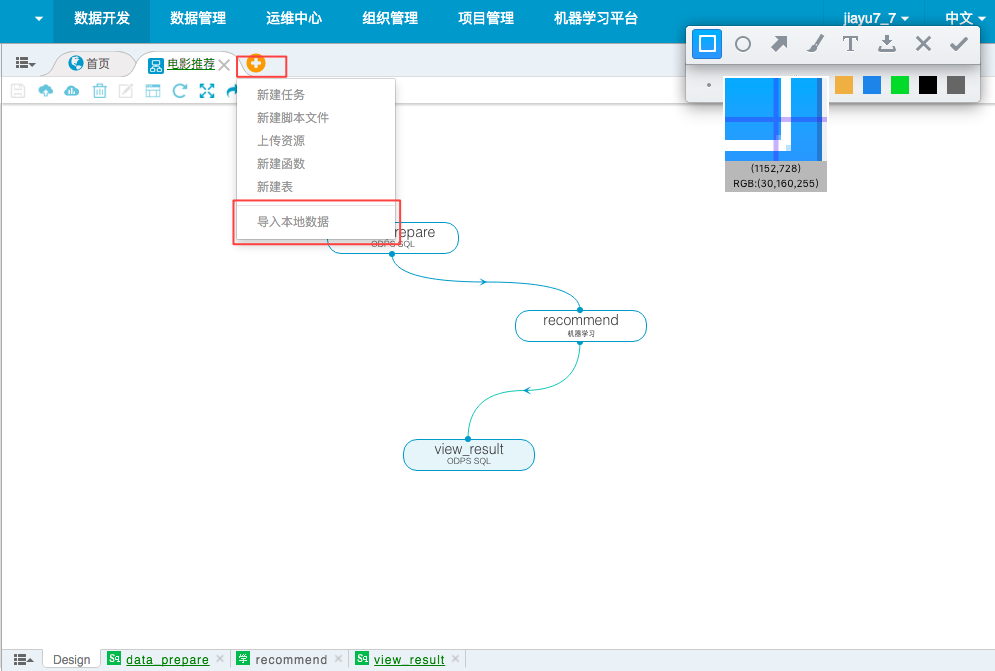
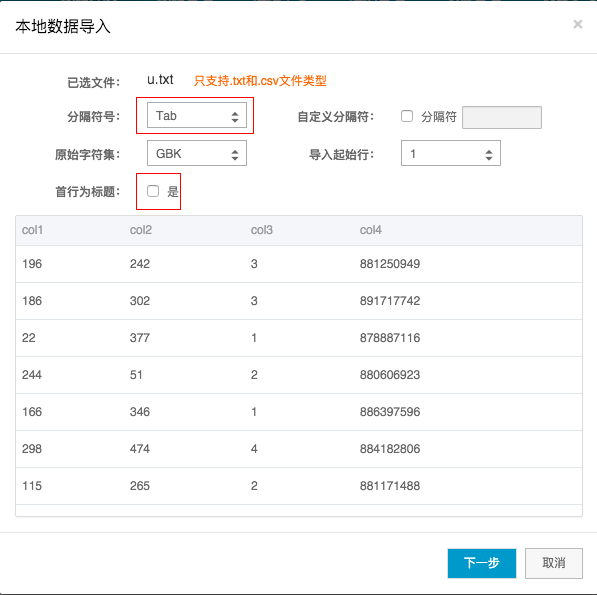
选择导入本地数据,将之前下载好的movielens 100k的目录里的u.data文件上传(这里需要注意的是DataIDE不识别.data后缀的文件,需要将文件rename到u.txt就ok了)。后面选择tab分隔,首行不导入,点击下一步就可以导入到对应的表了。
view_result的代码如下:
SELECT *FROM movie_recommend_outputLIMIT 10;
算法workflow
框架搭好了,数据也准备好了。最关键的体验时刻到了,我们来看看PAI究竟是如何玩算法的。
点击DataIDE上方的“机器学习平台”打开平台,进去时候需要选择租户。浏览一下,一个基于画布组件拖拽的界面展示在眼前。
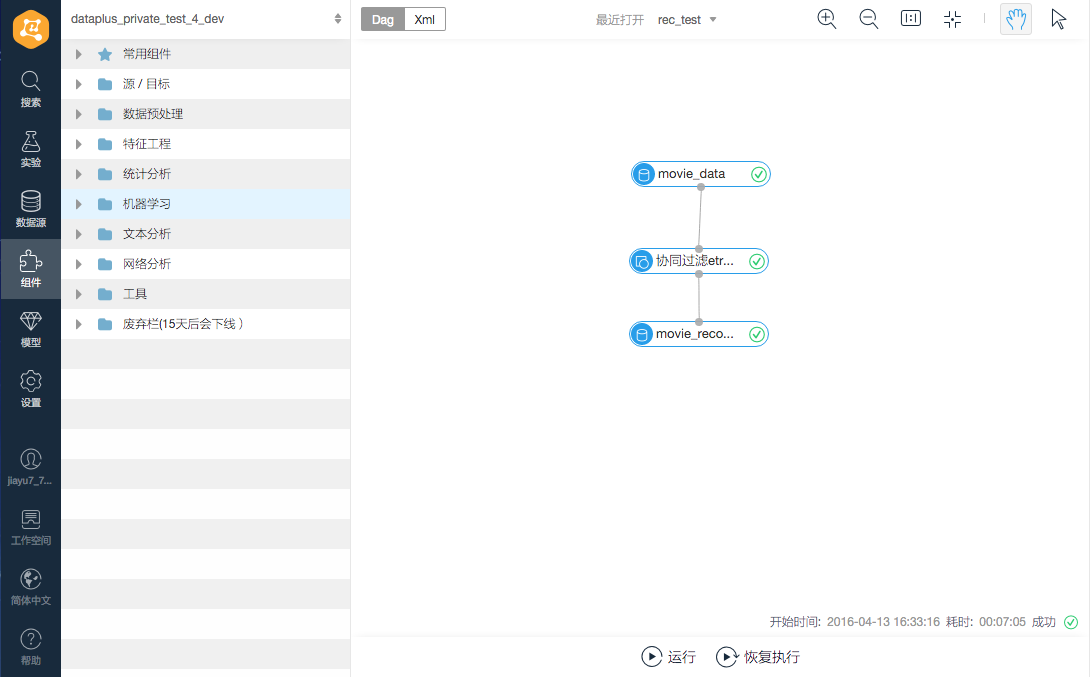
第一步要建立一个实验,本文建立一个实验叫做rec_test。
一个最简单的算法工作流也要包含几个步骤:
1. 数据输入
2. 算法运行
3. 数据输出
数据输入我们先从左侧导航栏里拖一个“源/目标”组件——“读ODPS表”到画布中,点击组件,在右侧配置表名——刚才已经在DataIDE加工好的movie_data。
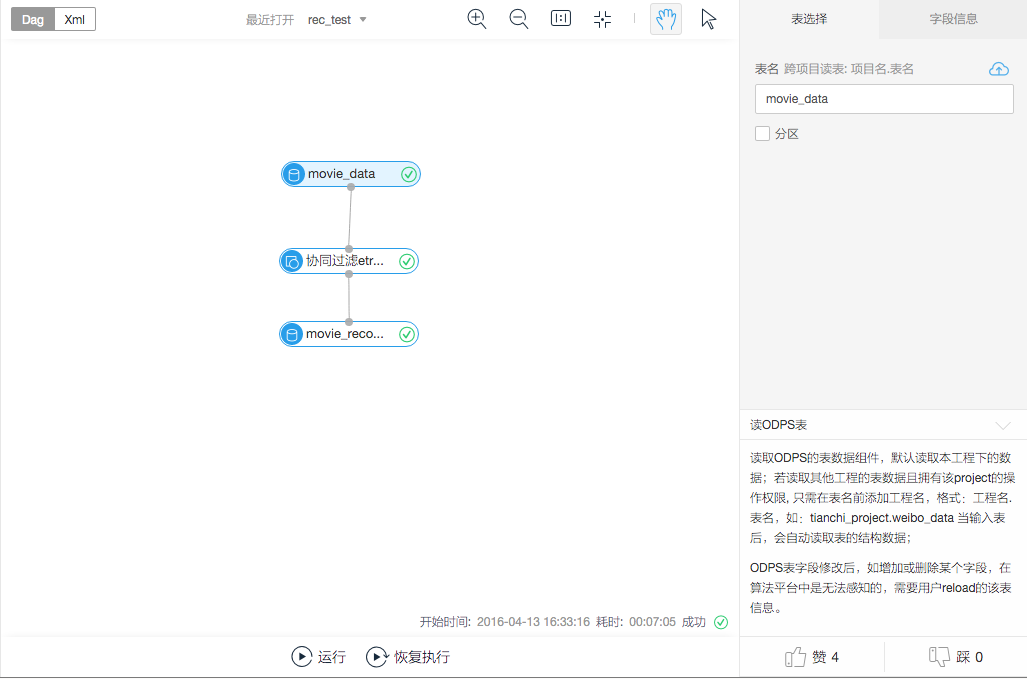
接下来从左侧“机器学习”-“关联推荐”里拉一个“协同过滤etrec”组件到画布中。点击后在右侧配置协同过滤算法需要的参数。
etrec是阿里巴巴集团搜索算法团队开发的运行于ODPS上的基于商品的协同过滤算法。
etrec接受一个两列或者三列的表输入,也就是inputTableName为两列或者三列,对应inputColNames为两列或者三列也可。如果是三列的情况下,要求第三列为数值类型。
第一列对应user,第二列对应item,第三列对应payload。输出表第一列对应main item, 后续的列对应main item的topN个推荐item list。这个list以kv形式存储。两个kv之间用','分割,k-v之间用':'分割。对etrec有兴趣的同学,我们可以后续邀请etrec的作者将更多的内容输出到云栖社区。
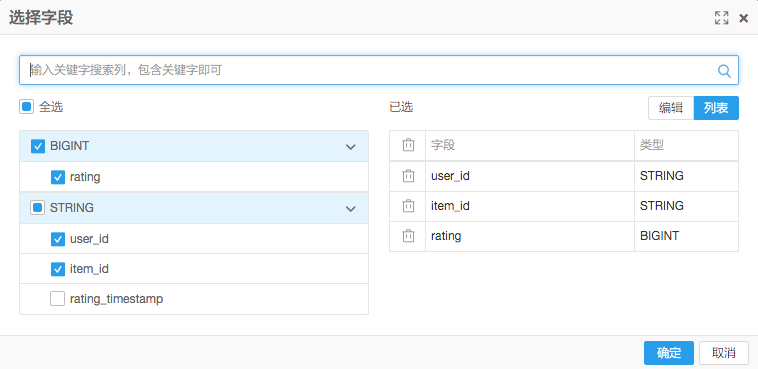
首先要配置etrec算法的输入,要选择user-item-payload形式的字段。
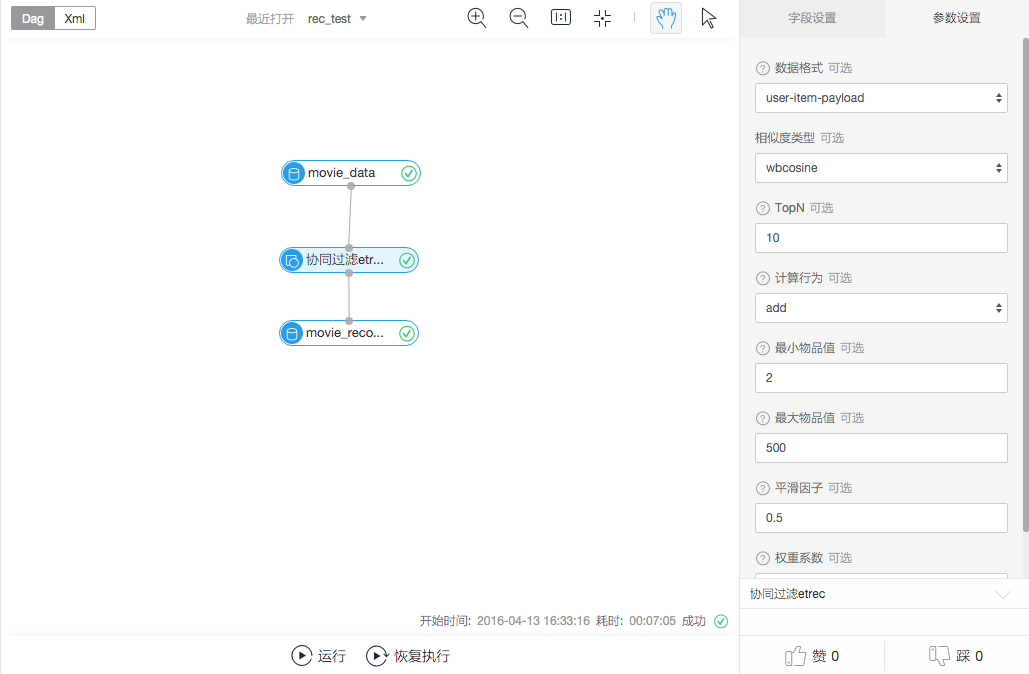
然后配置参数,为了简单,我修改了默认top 2000的输出,修改为10。
最后拉一个“写ODPS表”的组件到画布中,用来将推荐的结果写到表里。这里表名就配置刚才提到的输出表:movie_recommend_output。
把他们都串起来后,点击屏幕下方的运行,一个算法的workflow就开始运行了。
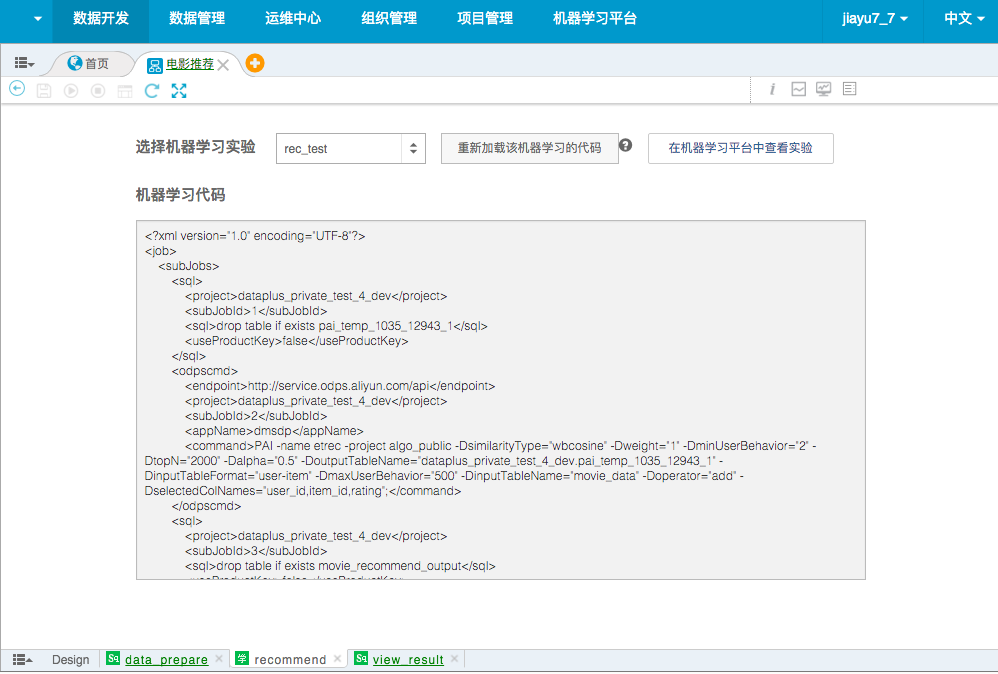
运行ok后,回到DataIDE,在recommend节点里将rec_test的实验配置进来,同时运行view_result查看数据,发现数据已经算好。
配置IDE里的机器学习节点:
最后view_result查询结果如下:
| itemid | similarity |
|---|---|
| 1000 | 304:0.01676046424 327:0.01661129281 690:0.01619649974 319:0.01618656974 307:0.016030702 678:0.01547486618 271:0.01490306017 276:0.01390136223 333:0.01321877343 286:0.009970226923 |
| 1015 | 689:0.02147827862 509:0.02132089743 747:0.02105407976 123:0.01873051453 895:0.0181759286 264:0.01773048459 306:0.01717658334 213:0.01688013218 682:0.01660011464 346:0.01654541667 |
| 1020 | 342:0.01762586756 975:0.01750440284 741:0.01731691169 849:0.01708816675 450:0.0169587199 27:0.01662833382 984:0.01603857983 790:0.01568657541 827:0.0149666991 831:0.01402610377 |
| 1035 | 844:0.0131411652 1142:0.01274707491 303:0.01223879381 813:0.0119001581 896:0.01187640877 261:0.01167792925 297:0.01132058693 872:0.01108132397 887:0.008978056052 311:0.008082707542 |
| 1042 | 59:0.01745097118 1039:0.01701451066 287:0.01673068855 682:0.01636340226 529:0.01608632908 312:0.01556095522 242:0.01312685541 324:0.0129800464 346:0.01170868453 259:0.01088178974 |
| 1053 | 306:0.01704915755 299:0.01701705749 898:0.01668891986 663:0.01602924228 324:0.01514042712 520:0.01390312532 331:0.01200231813 199:0.01197333239 242:0.01171316064 515:0.00992645675 |
| 1058 | 205:0.01937102341 170:0.0188263176 311:0.01861660626 312:0.01841353941 340:0.01808220486 169:0.01800534012 484:0.01735791837 511:0.01731592491 514:0.01635809654 242:0.01478030056 |
| 1086 | 754:0.01912158729 625:0.0191098618 513:0.01883058854 683:0.01878339802 661:0.01875523767 163:0.0177114301 346:0.01755236764 152:0.0172481773 311:0.01680141135 751:0.01342726574 |
| 1089 | 674:0.01703218764 1021:0.01694030231 606:0.01666525177 844:0.01589848019 513:0.01585807491 1065:0.01561581563 499:0.01425892501 131:0.01420383872 647:0.01406376859 19:0.01396364253 |
| 1097 | 280:0.01702140979 157:0.01615647037 660:0.01551820464 225:0.01546419268 38:0.01537917448 316:0.01535439113 66:0.01529470015 449:0.01507021427 1028:0.01295717842 315:0.0115311557 |
一切结束。
总结
通过这个例子,我们看到,通过阿里云数加大数据平台做机器学习是个非常容易的事情。欢迎大家多体验PAI平台给算法应用带来的便捷。
