@liyuj
2017-12-17T16:41:44.000000Z
字数 10526
阅读 5796
Apache-Ignite-2.3.0-中文开发手册
1.介绍
1.1.摘要
Apache Ignite是一个兼容ANSI-99、水平可扩展以及容错的分布式SQL数据库,这个分布式是以数据在集群范围的复制或者分区的形式提供的,具体的形式取决于使用场景。
作为一个SQL数据库,Ignite支持所有的DML指令,包括SELECT、UPDATE、INSERT和DELETE,它还实现了一个与分布式系统有关的DDL指令的子集。
Ignite的一个突出特性是完全支持分布式的SQL关联,Ignite支持并置和非并置的数据关联。并置时,关联是在每个节点的可用数据集上执行的,而不需要在网络上移动大量的数据,这种方式在分布式数据库中提供了最好的扩展性和性能。
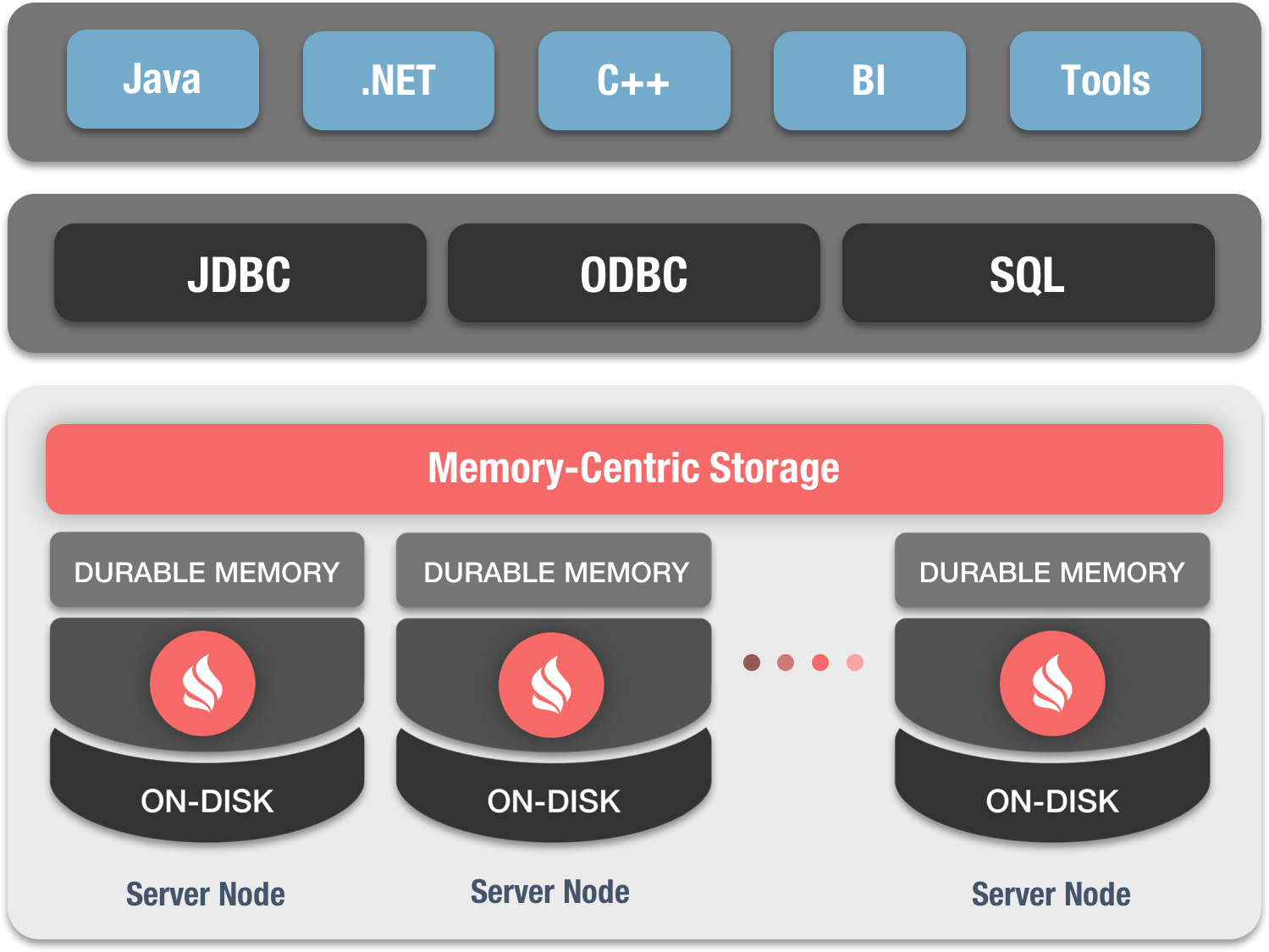
和很多的分布式SQL数据库不同,对于数据和索引,Ignite将内存和磁盘都视为完整有效的存储层,但是磁盘是可选的,如果禁用的话,Ignite就变为纯内存数据库。
可以像其他的SQL存储一样,根据需要与Ignite进行交互,比如通过外部的工具或者应用使用JDBC或者ODBC驱动进行连接。在这之上,Java、.NET和C++开发者也可以使用Ignite的原生SQL API。
1.2.入门
1.2.1.摘要
Ignite支持数据定义语言(DDL)语句,可以在运行时创建和删除表和索引,还可以支持数据操作语言(DML)来执行查询,这些不管是Ignite的原生SQL API还是ODBC和JDBC驱动,都是支持的。
在下面的示例中,会使用一个包含两个表的模式,这些表会用于保存城市以及居住在那里的人的信息,假定一个城市有很多的人,并且人只会居住于一个城市,这是一个一对多(1:m)的关系。
1.2.2.连接
作为入门来说,可以使用一个SQL工具,在后面的SQL工具章节中会有一个示例来演示如何配置SQL工具。还可以使用SQLLine接入集群然后在命令行执行SQL语句。
如果希望从源代码入手,下面的示例代码会演示如果通过JDBC以及ODBC驱动来获得一个连接:
JDBC:
// Register JDBC driverClass.forName("org.apache.ignite.IgniteJdbcThinDriver");// Open JDBC connectionConnection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");
ODBC:
// Combining connect stringstd::string connectStr = "DRIVER={Apache Ignite};SERVER=localhost;PORT=10800;SCHEMA=PUBLIC;";SQLCHAR outstr[ODBC_BUFFER_SIZE];SQLSMALLINT outstrlen;// Connecting to ODBC serverSQLRETURN ret = SQLDriverConnect(dbc, NULL, reinterpret_cast<SQLCHAR*>(&connectStr[0]), static_cast<SQLSMALLINT>(connectStr.size()),outstr, sizeof(outstr), &outstrlen, SQL_DRIVER_COMPLETE);
JDBC连接会使用thin模式驱动然后接入本地主机(127.0.0.1),一定要确保ignite-core.jar位于应用或者工具的类路径中,具体信息可以查看JDBC驱动相关的章节。
ODBC连接也是接入本地localhost,端口是10800,具体可以查看ODBC驱动相关的文档。
不管选择哪种方式,都需要打开一个命令行工具,然后转到{apache-ignite-version}/bin,然后执行ignite.sh或者ignite.bat脚本,这样可以启动一个或者多个节点,如果使用了Ignite.NET或者Ignite.C++,那么也可以使用对应的可执行文件启动一个节点。
Unix:
./ignite.sh
Windows:
ignite.bat
.NET:
platforms\dotnet\bin\Apache.Ignite.exe
C++ Windows
modules\platforms\cpp\project\vs\x64\Release\ignite.exe
C++ Unix:
./modules/platforms/cpp/ignite/ignite
如果节点是通过Java应用启动,要保证在Maven的pom.xml文件中包含ignite-indexing模块依赖:
<dependency><groupId>org.apache.ignite</groupId><artifactId>ignite-indexing</artifactId><version>${ignite.version}</version></dependency>
1.2.3.创建表
当前,创建的每个表都会位于PUBLIC模式,在模式和索引章节会有更详细的信息。
下面的示例代码会创建City和Person表:
SQL:
CREATE TABLE City (id LONG PRIMARY KEY, name VARCHAR)WITH "template=replicated";CREATE TABLE Person (id LONG, name VARCHAR, city_id LONG, PRIMARY KEY (id, city_id))WITH "backups=1, affinityKey=city_id";
JDBC:
// Create database tablestry (Statement stmt = conn.createStatement()) {// Create table based on REPLICATED templatestmt.executeUpdate("CREATE TABLE City (" +" id LONG PRIMARY KEY, name VARCHAR) " +" WITH \"template=replicated\"");// Create table based on PARTITIONED template with one backupstmt.executeUpdate("CREATE TABLE Person (" +" id LONG, name VARCHAR, city_id LONG, " +" PRIMARY KEY (id, city_id)) " +" WITH \"backups=1, affinityKey=city_id\"");}
ODBC:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);// Create table based on REPLICATED templateSQLCHAR query1[] = "CREATE TABLE City (""id LONG PRIMARY KEY, name VARCHAR) ""WITH \"template=replicated\"";SQLSMALLINT queryLen1 = static_cast<SQLSMALLINT>(sizeof(query1));SQLExecDirect(stmt, query, queryLen);// Create table based on PARTITIONED template with one backupSQLCHAR query2[] = "CREATE TABLE Person ( ""id LONG, name VARCHAR, city_id LONG ""PRIMARY KEY (id, city_id)) ""WITH \"backups=1, affinityKey=city_id\"";SQLSMALLINT queryLen2 = static_cast<SQLSMALLINT>(sizeof(query2));SQLExecDirect(stmt, query, queryLen);
CREATE TABLE命令执行之后,会做如下的工作:
- 会自动使用表名创建一个分布式缓存,它会用于存储City和Person类型的对象,这个缓存存储的City和Person对象可以与特定的Java、.NET和C++类或者二进制对象相对应;
- 会定义一个带有所有参数的SQL表;
- 数据以键-值记录的形式存储,主键列会用作存储对象的键,剩下的字段属于值,这就意味着可以使用键值API来处理数据。
和分布式缓存相关的参数是通过WITH子句传递的,如果忽略了WITH子句,那么缓存会使用CacheConfiguration对象的默认参数来创建。
在上面的示例中,对于Person表,Ignite创建了一个有一份备份数据的分布式缓存,city_id作为关系键,这些扩展参数是Ignite特有的,通过WITH进行传递,要为表配置其他的缓存参数,需要使用template参数,并且使用之前注册的缓存配置的名字(通过代码或者XML),具体可以参照扩展参数相关章节。
很多时候将不同的缓存键并置在一起非常有用,通常,业务逻辑需要访问不止一个缓存键,将他们并置在一起会确保具有相同affinityKey的所有键会被缓存在同一个节点上,这样就不需要从远程获取数据以避免耗时的网络开销。
在本示例中,有City和Person对象,并且希望并置Person对象及其居住的City对象,要做到这一点,就像上例所示,使用了WITH子句并且指定了affinityKey=city_id。
1.2.4.创建索引
定义索引可以加快查询的速度,下面是创建索引的示例:
SQL:
CREATE INDEX idx_city_name ON City (name)CREATE INDEX idx_person_name ON Person (name)
JDBC:
// Create indexestry (Statement stmt = conn.createStatement()) {// Create an index on the City tablestmt.executeUpdate("CREATE INDEX idx_city_name ON City (name)");// Create an index on the Person tablestmt.executeUpdate("CREATE INDEX idx_person_name ON Person (name)");}
ODBC:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);// Create an index on the City tableSQLCHAR query[] = "CREATE INDEX idx_city_name ON City (name)";SQLSMALLINT queryLen = static_cast<SQLSMALLINT>(sizeof(query));SQLRETURN ret = SQLExecDirect(stmt, query, queryLen);// Create an index on the Person tableSQLCHAR query2[] = "CREATE INDEX idx_person_name ON Person (name)";SQLSMALLINT queryLen2 = static_cast<SQLSMALLINT>(sizeof(query2));ret = SQLExecDirect(stmt, query2, queryLen2);
1.2.5.插入数据
对数据进行查询之前,需要在两个表中加载部分数据,下面是如何往表中插入数据的示例:
SQL:
INSERT INTO City (id, name) VALUES (1, 'Forest Hill');INSERT INTO City (id, name) VALUES (2, 'Denver');INSERT INTO City (id, name) VALUES (3, 'St. Petersburg');INSERT INTO Person (id, name, city_id) VALUES (1, 'John Doe', 3);INSERT INTO Person (id, name, city_id) VALUES (2, 'Jane Roe', 2);INSERT INTO Person (id, name, city_id) VALUES (3, 'Mary Major', 1);INSERT INTO Person (id, name, city_id) VALUES (4, 'Richard Miles', 2);
JDBC:
// Populate City table
try (PreparedStatement stmt =
conn.prepareStatement("INSERT INTO City (id, name) VALUES (?, ?)")) {
stmt.setLong(1, 1L);
stmt.setString(2, "Forest Hill");
stmt.executeUpdate();
stmt.setLong(1, 2L);
stmt.setString(2, "Denver");
stmt.executeUpdate();
stmt.setLong(1, 3L);
stmt.setString(2, "St. Petersburg");
stmt.executeUpdate();
}
// Populate Person table
try (PreparedStatement stmt =
conn.prepareStatement("INSERT INTO Person (id, name, city_id) VALUES (?, ?, ?)")) {
stmt.setLong(1, 1L);
stmt.setString(2, "John Doe");
stmt.setLong(3, 3L);
stmt.executeUpdate();
stmt.setLong(1, 2L);
stmt.setString(2, "Jane Roe");
stmt.setLong(3, 2L);
stmt.executeUpdate();
stmt.setLong(1, 3L);
stmt.setString(2, "Mary Major");
stmt.setLong(3, 1L);
stmt.executeUpdate();
stmt.setLong(1, 4L);
stmt.setString(2, "Richard Miles");
stmt.setLong(3, 2L);
stmt.executeUpdate();
}
ODBC:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);// Populate City tableSQLCHAR query1[] = "INSERT INTO City (id, name) VALUES (?, ?)";SQLRETURN ret = SQLPrepare(stmt, query1, static_cast<SQLSMALLINT>(sizeof(query1)));char name[1024];int32_t key = 1;strncpy(name, "Forest Hill", sizeof(name));ret = SQLExecute(stmt);key = 2;strncpy(name, "Denver", sizeof(name));ret = SQLExecute(stmt);key = 3;strncpy(name, "Denver", sizeof(name));ret = SQLExecute(stmt);// Populate Person tableSQLCHAR query2[] = "INSERT INTO Person (id, name, city_id) VALUES (?, ?, ?)";ret = SQLPrepare(stmt, query2, static_cast<SQLSMALLINT>(sizeof(query2)));key = 1;strncpy(name, "John Doe", sizeof(name));int32_t city_id = 3;ret = SQLExecute(stmt);key = 2;strncpy(name, "Jane Roe", sizeof(name));city_id = 2;ret = SQLExecute(stmt);key = 3;strncpy(name, "Mary Major", sizeof(name));city_id = 1;ret = SQLExecute(stmt);key = 4;strncpy(name, "Richard Miles", sizeof(name));city_id = 2;ret = SQLExecute(stmt);
Java API
// Connecting to the cluster.Ignite ignite = Ignition.start();// Getting a reference to an underlying cache created for City table above.IgniteCache<Long, City> cityCache = ignite.cache("SQL_PUBLIC_CITY");// Getting a reference to an underlying cache created for Person table above.IgniteCache<PersonKey, Person> personCache = ignite.cache("SQL_PUBLIC_PERSON");// Inserting entries into City.SqlFieldsQuery query = new SqlFieldsQuery("INSERT INTO City (id, name) VALUES (?, ?)");cityCache.query(query.setArgs(1, "Forest Hill")).getAll();cityCache.query(query.setArgs(2, "Denver")).getAll();cityCache.query(query.setArgs(3, "St. Petersburg")).getAll();// Inserting entries into Person.query = new SqlFieldsQuery("INSERT INTO Person (id, name, city_id) VALUES (?, ?, ?)");personCache.query(query.setArgs(1, "John Doe", 3)).getAll();personCache.query(query.setArgs(2, "Jane Roe", 2)).getAll();personCache.query(query.setArgs(3, "Mary Major", 1)).getAll();personCache.query(query.setArgs(4, "Richard Miles", 2)).getAll();
1.2.6.查询数据
数据加载之后,就可以执行查询了。下面就是如何查询数据的示例,其中包括两个表之间的关联:
SQL:
SELECT *FROM City;SELECT nameFROM CityWHERE id = 1;SELECT p.name, c.nameFROM Person p, City cWHERE p.city_id = c.id;
JDBC:
// Get data using an SQL join sample.try (Statement stmt = conn.createStatement()) {try (ResultSet rs =stmt.executeQuery("SELECT p.name, c.name " +" FROM Person p, City c " +" WHERE p.city_id = c.id")) {System.out.println("Query result:");while (rs.next())System.out.println(">>> " + rs.getString(1) +", " + rs.getString(2));}}
ODBC:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);// Get data using an SQL join sample.SQLCHAR query[] = "SELECT p.name, c.name ""FROM Person p, City c ""WHERE p.city_id = c.id";SQLSMALLINT queryLen = static_cast<SQLSMALLINT>(sizeof(query));SQLRETURN ret = SQLExecDirect(stmt, query, queryLen);
Java API
// Connecting to the cluster.Ignite ignite = Ignition.start();// Getting a reference to an underlying cache created for City table above.IgniteCache<Long, City> cityCache = ignite.cache("SQL_PUBLIC_CITY");// Querying data from the cluster using a distributed JOIN.SqlFieldsQuery query = new SqlFieldsQuery("SELECT p.name, c.name " +" FROM Person p, City c WHERE p.city_id = c.id");FieldsQueryCursor<List<?>> cursor = cityCache.query(query);Iterator<List<?>> iterator = cursor.iterator();System.out.println("Query result:");while (iterator.hasNext()) {List<?> row = iterator.next();System.out.println(">>> " + row.get(0) + ", " + row.get(1));}
1.2.7.修改数据
有时数据是需要修改的,这时就可以执行修改操作来修改已有的数据,下面是如何修改数据的示例:
SQL:
UPDATE CitySET name = 'Foster City'WHERE id = 2;
JDBC:
// Updatetry (Statement stmt = conn.createStatement()) {// Update Citystmt.executeUpdate("UPDATE City SET name = 'Foster City' WHERE id = 2");}
ODBC:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);// Update CitySQLCHAR query[] = "UPDATE City SET name = 'Foster City' WHERE id = 2"SQLSMALLINT queryLen = static_cast<SQLSMALLINT>(sizeof(query));SQLRETURN ret = SQLExecDirect(stmt, query, queryLen);
Java API
// Updating a city entry.SqlFieldsQuery query = new SqlFieldsQuery("UPDATE City SET name = 'Foster City' WHERE id = 2");cityCache.query(query).getAll();
1.2.8.删除数据
可能还需要从数据库中删除数据,下面是删除数据的示例:
SQL:
DELETE FROM PersonWHERE name = 'John Doe'
JDBC:
// Deletetry (Statement stmt = conn.createStatement()) {// Delete from Personstmt.executeUpdate("DELETE FROM Person WHERE name = 'John Doe'");}
ODBC:
SQLHSTMT stmt;// Allocate a statement handleSQLAllocHandle(SQL_HANDLE_STMT, dbc, &stmt);// Delete from PersonSQLCHAR query[] = "DELETE FROM Person WHERE name = 'John Doe'"SQLSMALLINT queryLen = static_cast<SQLSMALLINT>(sizeof(query));SQLRETURN ret = SQLExecDirect(stmt, query, queryLen);
Java API
// Removing a person.SqlFieldsQuery query = new SqlFieldsQuery("DELETE FROM Person WHERE name = 'John Doe'");personCache.query(query).getAll();
1.2.9.示例
GitHub上有和这个入门文档有关的完整代码。
