@liyuj
2018-01-27T10:09:50.000000Z
字数 17775
阅读 5280
Apache-Ignite-2.3.0-中文开发手册
7.流计算集成
7.1.摘要
Ignite可以和主要的流处理技术和框架进行集成,比如Kafka、Camel、Storm或者JMS,为基于Ignite的架构带来了更强大的功能。
7.2.Kafka流处理器
7.2.1.摘要
Apache Ignite的Kafka流处理器模块提供了从Kafka到Ignite缓存的流处理功能。
下面两个方法中的任何一个都可以用于获得这样的流处理功能:
- 使用和Ignite sink的Kafka连接器功能;
- 在Maven工程中导入Kafka的流处理器模块然后实例化KafkaStreamer用于数据流处理。
7.2.2.通过Kafka连接器的数据流
通过从Kafka的主题拉取数据然后将其写入特定的Ignite缓存,IgniteSinkConnector可以用于将数据从Kafka导入Ignite缓存。
连接器位于optional/ignite-kafka,它和它的依赖需要位于一个Kafka运行实例的类路径中,下面会详细描述。
关于Kafka连接器的更多信息,可以参考Kafka文档。
设置和运行
- 将下面的jar包放入Kafka的类路径;
ignite-kafka-x.x.x.jar <-- with IgniteSinkConnectorignite-core-x.x.x.jarcache-api-1.0.0.jarignite-spring-1.5.0-SNAPSHOT.jarspring-aop-4.1.0.RELEASE.jarspring-beans-4.1.0.RELEASE.jarspring-context-4.1.0.RELEASE.jarspring-core-4.1.0.RELEASE.jarspring-expression-4.1.0.RELEASE.jarcommons-logging-1.1.1.jar
- 准备worker的配置,比如;
bootstrap.servers=localhost:9092key.converter=org.apache.kafka.connect.storage.StringConvertervalue.converter=org.apache.kafka.connect.storage.StringConverterkey.converter.schemas.enable=falsevalue.converter.schemas.enable=falseinternal.key.converter=org.apache.kafka.connect.storage.StringConverterinternal.value.converter=org.apache.kafka.connect.storage.StringConverterinternal.key.converter.schemas.enable=falseinternal.value.converter.schemas.enable=falseoffset.storage.file.filename=/tmp/connect.offsetsoffset.flush.interval.ms=10000
- 准备连接器的配置,比如:
# connectorname=my-ignite-connectorconnector.class=org.apache.ignite.stream.kafka.connect.IgniteSinkConnectortasks.max=2topics=someTopic1,someTopic2# cachecacheName=myCachecacheAllowOverwrite=trueigniteCfg=/some-path/ignite.xmlsingleTupleExtractorCls=my.company.MyExtractor
这里cacheName等于some-path/ignite.xml中指定的缓存名,之后someTopic1,someTopic2主题的数据就会被拉取和存储。如果希望覆盖缓存中的已有值,可以将cacheAllowOverwrite设置为true。如果需要解析输入的数据然后形成新的键和值,则需要实现一个StreamSingleTupleExtractor然后像上面那样指定singleTupleExtractorCls。
还可以设置cachePerNodeDataSize和cachePerNodeParOps,用于调整每个节点的缓冲区以及每个节点中并行流操作的最大值。
可以将test中的example-ignite.xml文件作为一个简单缓存配置文件的示例。
- 启动连接器,作为一个示例,像下面这样在独立模式中:
bin/connect-standalone.sh myconfig/connect-standalone.properties myconfig/ignite-connector.properties
流程检查
要执行一个非常基本的功能检查,可以这样做:
- 启动Zookeeper;
bin/zookeeper-server-start.sh config/zookeeper.properties
- 启动Kafka服务:
bin/kafka-server-start.sh config/server.properties
- 为Kafka服务提供一些数据:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test --property parse.key=true --property key.separator=,k1,v1
- 启动连接器:
bin/connect-standalone.sh myconfig/connect-standalone.properties myconfig/ignite-connector.properties
- 检查缓存中的值,比如,通过REST API:
http://node1:8080/ignite?cmd=size&cacheName=cache1
7.2.3.使用Ignite的Kafka流处理器模块的数据流
如果使用Maven来管理项目的依赖,首先要像下面这样添加Kafka流处理器的模块依赖(将'${ignite.version}'替换为实际的版本号):
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd">...<dependencies>...<dependency><groupId>org.apache.ignite</groupId><artifactId>ignite-kafka</artifactId><version>${ignite.version}</version></dependency>...</dependencies>...</project>
假定有一个缓存,键和值都是String类型,可以像下面这样启动流处理器:
KafkaStreamer<String, String, String> kafkaStreamer = new KafkaStreamer<>();try (IgniteDataStreamer<String, String> stmr = ignite.dataStreamer(null)) {// allow overwriting cache datastmr.allowOverwrite(true);kafkaStreamer.setIgnite(ignite);kafkaStreamer.setStreamer(stmr);// set the topickafkaStreamer.setTopic(someKafkaTopic);// set the number of threads to process Kafka streamskafkaStreamer.setThreads(4);// set Kafka consumer configurationskafkaStreamer.setConsumerConfig(kafkaConsumerConfig);// set extractorkafkaStreamer.setSingleTupleExtractor(strExtractor);kafkaStreamer.start();}finally {kafkaStreamer.stop();}
要了解有关Kafka消费者属性的详细信息,可以参照Kafka文档。
7.3.Camel流处理器
7.3.1.摘要
本章节聚焦于Apache Camel流处理器,它也可以被视为一个统一的流处理器,因为他可以从Camel支持的任何技术或者协议中消费消息然后注入一个Ignite缓存。
Apache Camel是什么?
如果不知道Apache Camel是什么,本章节的后面会做一个简介。
使用这个流处理器,基于如下技术可以将数据条目注入一个Ignite缓存:
- 通过提取消息头和消息体,调用一个Web服务(SOAP或者REST);
- 为消息监听一个TCP或者UDP通道;
- 通过FTP接收文件的内容或者写入本地文件系统;
- 通过POP3或者IMAP发送接收到的消息;
- 一个MongoDB Tailable游标;
- 一个AWS SQS队列;
- 其他的;
这个流处理器支持两种摄取模式,直接摄取和间接摄取。
一个Ignite Camel组件
还有一个camel-ignite组件,通过该组件,可以与Ignite缓存、计算、事件、消息等进行交互。
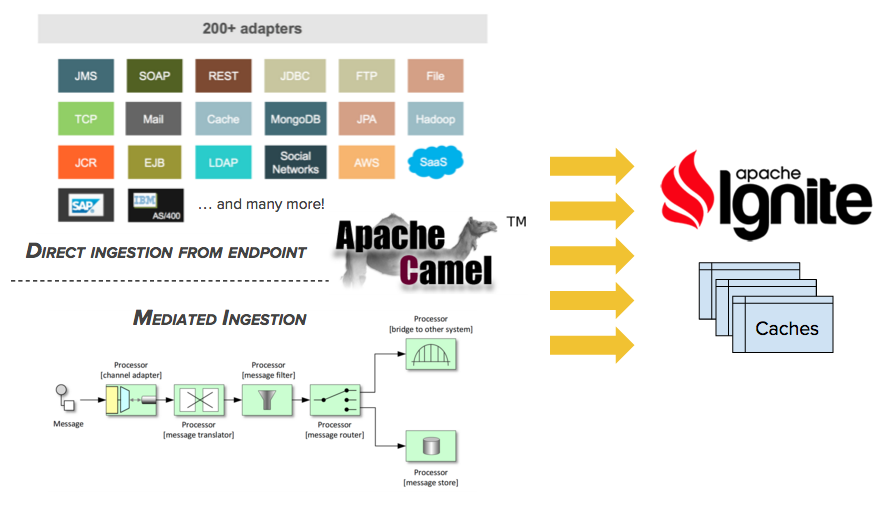
7.3.2.直接摄取
直接摄取使得通过一个提取器元组的帮助可以从任意Camel端点获得消息然后直接进入Ignite,这个被称为直接摄取。
下面是一个代码示例:
// Start Apache Ignite.Ignite ignite = Ignition.start();// Create an streamer pipe which ingests into the 'mycache' cache.IgniteDataStreamer<String, String> pipe = ignite.dataStreamer("mycache");// Create a Camel streamer and connect it.CamelStreamer<String, String> streamer = new CamelStreamer<>();streamer.setIgnite(ignite);streamer.setStreamer(pipe);// This endpoint starts a Jetty server and consumes from all network interfaces on port 8080 and context path /ignite.streamer.setEndpointUri("jetty:http://0.0.0.0:8080/ignite?httpMethodRestrict=POST");// This is the tuple extractor. We'll assume each message contains only one tuple.// If your message contains multiple tuples, use a StreamMultipleTupleExtractor.// The Tuple Extractor receives the Camel Exchange and returns a Map.Entry<?,?> with the key and value.streamer.setSingleTupleExtractor(new StreamSingleTupleExtractor<Exchange, String, String>() {@Override public Map.Entry<String, String> extract(Exchange exchange) {String stationId = exchange.getIn().getHeader("X-StationId", String.class);String temperature = exchange.getIn().getBody(String.class);return new GridMapEntry<>(stationId, temperature);}});// Start the streamer.streamer.start();
7.3.3.间接摄取
多于更多的复杂场景,也可以创建一个Camel route在输入的消息上执行复杂的处理,比如转换、验证、拆分、聚合、幂等、重新排序、富集等,然后只是将结果注入Ignite缓存,这个被称为间接摄取。
// Create a CamelContext with a custom route that will:// (1) consume from our Jetty endpoint.// (2) transform incoming JSON into a Java object with Jackson.// (3) uses JSR 303 Bean Validation to validate the object.// (4) dispatches to the direct:ignite.ingest endpoint, where the streamer is consuming from.CamelContext context = new DefaultCamelContext();context.addRoutes(new RouteBuilder() {@Overridepublic void configure() throws Exception {from("jetty:http://0.0.0.0:8080/ignite?httpMethodRestrict=POST").unmarshal().json(JsonLibrary.Jackson).to("bean-validator:validate").to("direct:ignite.ingest");}});// Remember our Streamer is now consuming from the Direct endpoint above.streamer.setEndpointUri("direct:ignite.ingest");
7.3.4.设置一个响应
响应默认只是简单地将一个原来的请求的副本反馈给调用者(如果是一个同步端点)。如果希望定制这个响应,需要设置一个Camel的Processor作为一个responseProcessor。
streamer.setResponseProcessor(new Processor() {@Override public void process(Exchange exchange) throws Exception {exchange.getOut().setHeader(Exchange.HTTP_RESPONSE_CODE, 200);exchange.getOut().setBody("OK");}});
7.3.5.Maven依赖
要使用ignite-camel流处理器,需要添加如下的依赖:
<dependency><groupId>org.apache.ignite</groupId><artifactId>ignite-camel</artifactId><version>${ignite.version}</version></dependency>
也可以加入camel-core作为一个过度依赖。
不要忘记添加Camel组件依赖
还要确保添加流处理器中要用到的Camel组件的依赖。
7.3.6.Apache Camel
Apache Camel是一个企业级集成框架,围绕Gregor Hohpe和Bobby Woolf推广的企业集成模式思想,比如通道、管道、过滤器、拆分器、聚合器、路由器、重新排序器等等,他可以像一个乐高玩具一样连接彼此来创建一个将系统连接在一起的集成路径。
到目前为止,Camel有超过200个组件,很多都是针对不同技术的适配器,比如JMS、SOAP、HTTP、文件、FTP、POP3、SMTP、SSH;包括云服务,比如AWS,GCE、Salesforce;社交网络,比如Twitter、Facebook;甚至包括新一代的数据库,比如MongoDB、Cassandra;以及数据处理技术,比如Hadoop(HDFS,HBase)以及Spark。
Camel可以运行在各种环境中,同时也被Ignite支持:独立的Java程序、OSGi、Servlet容器、Spring Boot、JEE应用服务器等等。他是完全模块化的,因此只需要部署实际需要的组件,其他都不需要。
要了解更多的信息,可以参照Camel是什么?。
7.4.JMS流处理器
7.4.1.摘要
Ignite提供了一个JMS数据流处理器,他会从JMS代理中消费消息,将消息转换为缓存数据格式然后插入Ignite缓存。
7.4.2.特性
这个数据流处理器支持如下的特性:
- 从队列或者主题中消费消息;
- 支持从主题长期订阅;
- 通过
threads参数支持并发的消费者;
- 当从队列中消费消息时,这个组件会启动尽可能多的
会话对象,每个都持有单独的MessageListener实例,因此实现了自然的并发; - 当从主题消费消息时,显然无法启动多个线程,因为这样会导致消费重复的消息,因此,通过一个内部的线程池来实现虚拟的并发。
- 当从队列中消费消息时,这个组件会启动尽可能多的
- 通过
transacted参数支持事务级的会话; - 通过
batched参数支持批量的消费,他会对在一个本地JMS事务的范围内接受的消息进行分组(不需要支持XA)。依赖于代理,这个技术提供了一个很高的吞吐量,因为它减少了必要的消息往返确认的量,虽然存在复制消息的开销(特别是在事务的中间发生了一个事件)。
- 当达到
batchClosureMillis时间或者会话收到了至少batchClosureSize消息后批次会被提交; - 基于时间的闭包按照设定的频率触发,然后并行地应用到所有的
会话; - 基于大小的闭包会应用到所有单独的
会话(因为事务在JMS中是会话绑定的),因此当该会话消费了那么多消息后就会被触发。 - 两个选项是互相兼容的,可以禁用任何一个,但是当批次启用之后不能两个都启用。
- 当达到
- 支持通过实现特定的
Destination对象或者名字来指定目的地。
本实现已经在Apache ActiveMQ中进行了测试,但是只要客户端库实现了JMS 1.1 规范的所有JMS代理都是支持的。
7.4.3.实例化JMS流处理器
实例化JMS流处理器时,需要具体化下面的泛型:
T extends Message:流处理器会接收到的JMSMessage的类型,如果他可以接收多个,可以使用通用的Message类型;K:缓存键的类型;V:缓存值的类型;
要配置JMS流处理器,还需要提供如下的必要属性:
connectionFactory:ConnectionFactory的实例,通过代理进行必要的配置,他也可以是一个ConnectionFactory池;destination或者(destinationName和destinationType):一个Destination对象(通常是一个代理指定的JMSQueue或者Topic接口的实现),或者是目的地名字的组合(队列或者主题名)和到或者Queue或者Topic的Class引用的类型, 在后一种情况下,流处理器通过Session.createQueue(String)或者Session.createTopic(String)来获得一个目的地;transformer:一个MessageTransformer<T, K, V>的实现,他会消化一个类型为T的JMS消息然后产生一个要添加的缓存条目Map<K, V>,他也可以返回null或者空的Map来忽略传入的消息。
7.4.4.示例
下面的示例通过String类型的键和String类型的值来填充一个缓存,要消费的TextMessage格式如下:
raulk,Raul Kripalanidsetrakyan,Dmitriy Setrakyansv,Sergi Vladykingm,Gianfranco Murador
下面是代码:
// create a data streamerIgniteDataStreamer<String, String> dataStreamer = ignite.dataStreamer("mycache"));dataStreamer.allowOverwrite(true);// create a JMS streamer and plug the data streamer into itJmsStreamer<TextMessage, String, String> jmsStreamer = new JmsStreamer<>();jmsStreamer.setIgnite(ignite);jmsStreamer.setStreamer(dataStreamer);jmsStreamer.setConnectionFactory(connectionFactory);jmsStreamer.setDestination(destination);jmsStreamer.setTransacted(true);jmsStreamer.setTransformer(new MessageTransformer<TextMessage, String, String>() {@Overridepublic Map<String, String> apply(TextMessage message) {final Map<String, String> answer = new HashMap<>();String text;try {text = message.getText();}catch (JMSException e) {LOG.warn("Could not parse message.", e);return Collections.emptyMap();}for (String s : text.split("\n")) {String[] tokens = s.split(",");answer.put(tokens[0], tokens[1]);}return answer;}});jmsStreamer.start();// on application shutdownjmsStreamer.stop();dataStreamer.close();
要使用这个组件,必须通过构建系统(Maven, Ivy, Gradle,sbt等)导入如下的模块:
<dependency><groupId>org.apache.ignite</groupId><artifactId>ignite-jms11</artifactId><version>${ignite.version}</version></dependency>
7.5.MQTT流处理器
7.5.1.摘要
该流处理器使用Eclipse Paho作为MQTT客户端,从一个MQTT主题消费消息,然后将键值对提供给IgniteDataStreamer实例。
必须提供一个流的元组提取器(不管是单条目的,还是多条目的提取器)来处理传入的消息,然后提取元组以插入缓存。
7.5.2.特性
这个流处理器支持:
- 一次订阅一个或者多个主题;
- 为一个主题或者多个主题指定订阅者的QoS;
- 设置MqttConnectOptions以开启比如会话持久化这样的特性;
- 指定客户端ID。如果未指定会生成以及维护一个随机的ID,指导重新连接;
- (重新)连接重试可以通过guava-retrying库实现,重试等待和重试停止是可以配置的;
- 直到客户端第一次连接,都会阻塞start()方法。
7.5.3.示例
下面的代码显示了如何使用这个流处理器:
// Start Ignite.Ignite ignite = Ignition.start();// Get a data streamer reference.IgniteDataStreamer<Integer, String> dataStreamer = grid().dataStreamer("mycache");// Create an MQTT data streamerMqttStreamer<Integer, String> streamer = new MqttStreamer<>();streamer.setIgnite(ignite);streamer.setStreamer(dataStreamer);streamer.setBrokerUrl(brokerUrl);streamer.setBlockUntilConnected(true);// Set a single tuple extractor to extract items in the format 'key,value' where key => Int, and value => String// (using Guava here).streamer.setSingleTupleExtractor(new StreamSingleTupleExtractor<MqttMessage, Integer, String>() {@Override public Map.Entry<Integer, String> extract(MqttMessage msg) {List<String> s = Splitter.on(",").splitToList(new String(msg.getPayload()));return new GridMapEntry<>(Integer.parseInt(s.get(0)), s.get(1));}});// Consume from multiple topics at once.streamer.setTopics(Arrays.asList("def", "ghi", "jkl", "mno"));// Start the MQTT Streamer.streamer.start();
要了解有关选项的更多信息,可以参考ignite-mqtt模块的javadoc。
7.6.Storm流处理器
Apache Ignite的Storm流处理器模块提供了从Storm到Ignite缓存的流处理功能。
通过如下步骤可以将数据注入Ignite缓存:
- 在Maven工程中导入Ignite的Storm流处理器模块。如果使用Maven来管理项目的依赖,可以像下面这样添加Storm模块依赖(将
${ignite.version}替换为实际使用的版本):
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd">...<dependencies>...<dependency><groupId>org.apache.ignite</groupId><artifactId>ignite-storm</artifactId><version>${ignite.version}</version></dependency>...</dependencies>...</project>
- 创建一个Ignite配置文件(可以以modules/storm/src/test/resources/example-ignite.xml文件作为示例)并且确保他可以被流处理器访问;
- 确保输入流处理器的键值数据通过名为
ignite的属性指定(或者通过StormStreamer.setIgniteTupleField(...)也可以指定一个不同的)。作为一个示例可以看TestStormSpout.declareOutputFields(...)。 - 为流处理器创建一个网络,带有所有依赖制作一个jar文件然后运行如下的命令:
storm jar ignite-storm-streaming-jar-with-dependencies.jar my.company.ignite.MyStormTopology
7.7.Flink流处理器
Apache Ignite Flink Sink模块是一个流处理连接器,他可以将Flink数据注入Ignite缓存,该Sink会将输入的数据注入Ignite缓存。每当创建一个Sink,都需要提供一个Ignite缓存名和Ignite网格配置文件。
通过如下步骤,可以开启到Ignite缓存的数据注入:
- 在Maven工程中导入Ignite的Flink Sink模块。如果使用Maven来管理项目的依赖的话,可以像下面这样添加Flink模块依赖(将
${ignite.version}替换为实际使用的版本);
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd">...<dependencies>...<dependency><groupId>org.apache.ignite</groupId><artifactId>ignite-flink</artifactId><version>${ignite.version}</version></dependency>...</dependencies>...</project>
- 创建一个Ignite配置文件,并且确保它可以被Sink访问;
- 确保输入Sink的数据被指定然后启动Sink;
IgniteSink igniteSink = new IgniteSink("myCache", "ignite.xml");igniteSink.setAllowOverwrite(true);igniteSink.setAutoFlushFrequency(10);igniteSink.start();DataStream<Map> stream = ...;// Sink data into the grid.stream.addSink(igniteSink);try {env.execute();} catch (Exception e){// Exception handling.}finally {igniteSink.stop();}
可以参考ignite-flink模块的javadoc来了解可用选项的详细信息。
7.8.Twitter流处理器
Ignite的Twitter流处理器模块会从Twitter消费微博然后将转换后的键值对注入Ignite缓存。
要将来自Twitter的数据流注入Ignite缓存,需要:
- 在Maven工程里导入Ignite的twitter模块;
如果使用maven来管理项目的依赖,那么可以像下面这样添加依赖:
<dependency><groupId>org.apache.ignite</groupId><artifactId>ignite-twitter</artifactId><version>${ignite.version}</version></dependency>
将${ignite.version}替换为实际使用的Ignite版本。
- 在代码中配置必要的参数,然后启动流处理器,比如:
IgniteDataStreamer dataStreamer = ignite.dataStreamer("myCache");dataStreamer.allowOverwrite(true);dataStreamer.autoFlushFrequency(10);OAuthSettings oAuthSettings = new OAuthSettings("setting1", "setting2", "setting3", "setting4");TwitterStreamer<Integer, String> streamer = new TwitterStreamer<>(oAuthSettings);streamer.setIgnite(ignite);streamer.setStreamer(dataStreamer);Map<String, String> params = new HashMap<>();params.put("track", "apache, twitter");params.put("follow", "3004445758");streamer.setApiParams(params);// Twitter Streaming API params.streamer.setEndpointUrl(endpointUrl);// Twitter streaming API endpoint.streamer.setThreadsCount(8);streamer.start();
可以参考Twitter流API文档来了解各种参数的详细信息。
7.9.Flume流处理器
7.9.1.摘要
Apache Flume是一个高效的收集、汇总以及移动大量的日志数据的分布式的、高可靠和高可用的服务(https://github.com/apache/flume)。
IgniteSink是一个Flume池,他会从相对应的Flume通道中提取事件然后将数据注入Ignite缓存,目前支持Flume的1.6.0版本。
在启动Flume代理之前,就像下面章节描述的,IgniteSink及其依赖需要包含在代理的类路径中。
7.9.2.设置
- 通过实现EventTransformer接口创建一个转换器;
- 在${FLUME_HOME}中的plugins.d目录下创建
ignite子目录,如果plugins.d目录不存在,创建它; - 构建前述的转换器并且拷贝到
${FLUME_HOME}/plugins.d/ignite/lib目录; - 从Ignite发行版中拷贝其他的Ignite相关的jar包到
${FLUME_HOME}/plugins.d/ignite/libext,如下所示;
plugins.d/`-- ignite|-- lib| `-- ignite-flume-transformer-x.x.x.jar <-- your jar`-- libext|-- cache-api-1.0.0.jar|-- ignite-core-x.x.x.jar|-- ignite-flume-x.x.x.jar <-- IgniteSink|-- ignite-spring-x.x.x.jar|-- spring-aop-4.1.0.RELEASE.jar|-- spring-beans-4.1.0.RELEASE.jar|-- spring-context-4.1.0.RELEASE.jar|-- spring-core-4.1.0.RELEASE.jar`-- spring-expression-4.1.0.RELEASE.jar
- 在Flume配置文件中,指定带有缓存属性的Ignite XML配置文件的位置(可以将*flume/src/test/resources/example-ignite.xml *作为一个基本的样例),缓存属性中包含要创建缓存的缓存名称(与Ignite配置文件中的相同),EventTransformer的实现类以及可选的批处理大小。所有的属性都显示在下面的表格中(必须项为粗体)。
| 属性名称 | 默认值 | 描述 |
|---|---|---|
| channel | - | |
| type | 组件类型名,应该为org.apache.ignite.stream.flume.IgniteSink |
- |
| igniteCfg | Ignite的XML配置文件 | - |
| cacheName | 缓存名,与igniteCfg中的一致 | - |
| eventTransformer | org.apache.ignite.stream.flume.EventTransformer的实现类名 | - |
| batchSize | 每事务要写入的事件数 | 100 |
名字为a1的Sink代理配置片段如下所示:
a1.sinks.k1.type = org.apache.ignite.stream.flume.IgniteSinka1.sinks.k1.igniteCfg = /some-path/ignite.xmla1.sinks.k1.cacheName = testCachea1.sinks.k1.eventTransformer = my.company.MyEventTransformera1.sinks.k1.batchSize = 100
指定代码和配置后(可以参照Flume的文档),就可以运行Flume的代理了。
7.10.ZeroMQ流处理器
Ignite的ZeroMQ流处理器模块具有将ZeroMQ数据流注入Ignite缓存的功能。
要将数据流注入Ignite缓存,需要按照如下步骤操作:
- 将Ignite的ZeroMQ流处理器模块加入Maven依赖:
如果使用Maven来管理项目的依赖,那么需要添加如下的ZeroMQ模块依赖(注意将${ignite.version}替换为实际使用的版本号):
<dependencies>...<dependency><groupId>org.apache.ignite</groupId><artifactId>ignite-zeromq</artifactId><version>${ignite.version}</version></dependency>...</dependencies>
- 要么实现StreamSingleTupleExtractor,要么实现StreamMultipleTupleExtractor,这里可以了解更多的细节。
- 像下面这样设置提取器,并且初始化流处理器:
try (IgniteDataStreamer<Integer, String> dataStreamer =grid().dataStreamer("myCacheName")) {dataStreamer.allowOverwrite(true);dataStreamer.autoFlushFrequency(1);try (IgniteZeroMqStreamer streamer = new IgniteZeroMqStreamer(1, ZeroMqTypeSocket.PULL, "tcp://localhost:5671", null)) {streamer.setIgnite(grid());streamer.setStreamer(dataStreamer);streamer.setSingleTupleExtractor(new ZeroMqStringSingleTupleExtractor());streamer.start();}}
7.11.RocketMQ流处理器
这个流处理器模块提供了从Apache RocketMQ到Ignite的流化处理功能。
如果要使用Ignite的RocketMQ流处理器模块:
- 将其导入自己的Maven工程;
如果使用Maven管理项目的依赖,需要想下面这样添加RocketMQ的模块依赖(将${ignite.version}替换为实际使用的Ignite版本):
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd">...<dependencies>...<dependency><groupId>org.apache.ignite</groupId><artifactId>ignite-rocketmq</artifactId><version>${ignite.version}</version></dependency>...</dependencies>...</project>
2.实现StreamSingleTupleExtractor或者StreamMultipleTupleExtractor,看下面的MyTupleExtractor示例。
对于一个简单的实现,可以看看RocketMQStreamerTest.java。
3.初始化之后启动:
try (IgniteDataStreamer<String, byte[]> dataStreamer = ignite.dataStreamer(MY_CACHE)) {dataStreamer.allowOverwrite(true);dataStreamer.autoFlushFrequency(10);streamer = new RocketMQStreamer<>();//configure.streamer.setIgnite(ignite);streamer.setStreamer(dataStreamer);streamer.setNameSrvAddr(NAMESERVER_IP_PORT);streamer.setConsumerGrp(CONSUMER_GRP);streamer.setTopic(TOPIC_NAME);streamer.setMultipleTupleExtractor(new MyTupleExtractor());streamer.start();}finally {streamer.stop();}
在javadoc中可以找到更多可用选项的信息。
