@liyuj
2017-01-10T13:17:47.000000Z
字数 9692
阅读 6877
Apache-Ignite-1.8.0-中文开发手册
5.流计算和CEP
5.1.流计算和CEP
Ignite流计算可以以可扩展以及容错的方式处理持续不断的数据流。在一个中等规模的集群中,数据注入Ignite的速度可以很高,甚至轻易地达到每秒处理百万级的事件。
工作方式
- 客户端节点通过Ignite数据流处理器向Ignite缓存中注入有限的或者持续的数据流;
- 数据在Ignite数据节点间自动分区,每个节点持有均等的数据量;
- 数据流可以在Ignite数据节点上以并置的方式直接并行处理;
- 客户端也可以在数据流上执行并发的SQL查询。
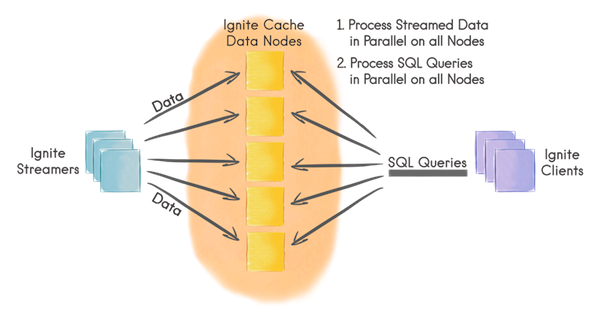
数据流处理器
数据流处理器是通过IgniteDataStreamerAPI定义的,他可以往Ignite数据流缓存中注入大量的持续不断的数据流,数据流处理器对于所有流入Ignite的数据以可扩展和容错的方式提供了至少一次保证。
滑动窗口
Ignite流计算功能也可以在数据的滑动窗口中进行查询。因为数据流是持续不断的,所以很少希望查询最初的所有数据集,反而更感兴趣于问像“最近两小时最受欢迎的十个产品是什么?”或者“过去一天特定种类产品的平均价格是多少?”这样的问题。要获得这些数据,需要能够在滑动数据窗口中进行查询。
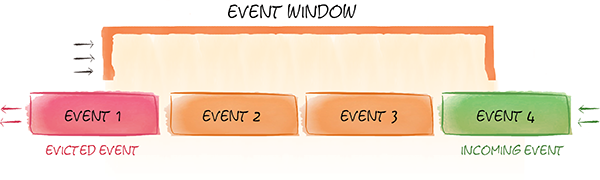
滑动窗口可以配置Ignite缓存的退出策略,可以基于时间、基于大小或者基于批次。可以一个缓存配置一个滑动窗口,然而如果希望同样的数据有不同的滑动窗口也可以容易地定义多个缓存。
查询数据
可以和Ignite的SQL、TEXT以及基于谓词的缓存查询一起使用Ignite数据索引能力的全部功能来在数据流中进行查询。
单词计数示例
在该示例中会将文本注入Ignite然后对每个独立的单词进行计数,还会周期性的在流中进行SQL查询来查询10个最频繁的单词。
与已有的流处理技术集成
Ignite可以与各种常见的流处理技术和产品进行集成,比如Kafka,Camel或者JMS,可以容易且高效地将流式数据注入Ignite。
5.2.数据流处理器
5.2.1.摘要
数据流处理器是通过IgniteDataStreamerAPI定义的,用于将大量的持续数据流注入Ignite缓存。数据流处理器以可扩展以及容错的方式,为将所有的数据流注入Ignite提供了至少一次保证。
5.2.2.IgniteDataStreamer
快速地将大量的数据流注入Ignite的主要抽象是IgniteDataStreamer,在内部他会适当地将数据整合成批次然后将这些批次与缓存这些数据的节点并置在一起。
高速加载是通过如下技术获得的:
- 映射到同一个集群节点上的数据条目会作为一个批次保存在缓冲区中;
- 多个缓冲区可以同时共处;
- 为了避免内存溢出,数据流处理器有一个缓冲区的最大数,他们可以并行的处理;
要将数据加入数据流处理器,调用IgniteDataStreamer.addData(...)方法即可。
// Get the data streamer reference and stream data.try (IgniteDataStreamer<Integer, String> stmr = ignite.dataStreamer("myStreamCache")) {// Stream entries.for (int i = 0; i < 100000; i++)stmr.addData(i, Integer.toString(i));}
允许覆写
默认的话,数据流处理器不会覆写已有的数据,这意味着如果遇到一个缓存内已有的条目,他会忽略这个条目。这是一个最有效的以及高性能的模式,因为数据流处理器不需要在后台考虑数据的版本。
如果预想到数据可能在数据流缓存中可能存在以及希望覆写它,设置IgniteDataStreamer.allowOverwrite(true)即可。
5.2.3.StreamReceiver
对于希望执行一些自定义的逻辑而不仅仅是添加新数据的情况,可以利用一下StreamReceiverAPI。
流接收器可以以并置的方式直接在缓存该数据条目的节点上对数据流做出反应,可以在数据进入缓存之前修改数据或者在数据上添加任何的预处理逻辑。
注意
StreamReceiver不会自动地将数据加入缓存,需要显式地调用任意的cache.put(...)方法。
5.2.4.StreamTransformer
StreamTransformer是一个StreamReceiver的简单实现,他会基于之前的值来修改数据流缓存中的数据。更新是并置的,即他会明确地在数据缓存的集群节点上发生。
在下面的例子中,通过StreamTransformer在文本流中为每个发现的确切的单词增加一个计数。
Java8:
CacheConfiguration cfg = new CacheConfiguration("wordCountCache");IgniteCache<String, Long> stmCache = ignite.getOrCreateCache(cfg);try (IgniteDataStreamer<String, Long> stmr = ignite.dataStreamer(stmCache.getName())) {// Allow data updates.stmr.allowOverwrite(true);// Configure data transformation to count instances of the same word.stmr.receiver(StreamTransformer.from((e, arg) -> {// Get current count.Long val = e.getValue();// Increment count by 1.e.setValue(val == null ? 1L : val + 1);return null;}));// Stream words into the streamer cache.for (String word : text)stmr.addData(word, 1L);}
Java7:
CacheConfiguration cfg = new CacheConfiguration("wordCountCache");IgniteCache<Integer, Long> stmCache = ignite.getOrCreateCache(cfg);try (IgniteDataStreamer<String, Long> stmr = ignite.dataStreamer(stmCache.getName())) {// Allow data updates.stmr.allowOverwrite(true);// Configure data transformation to count instances of the same word.stmr.receiver(new StreamTransformer<String, Long>() {@Override public Object process(MutableEntry<String, Long> e, Object... args) {// Get current count.Long val = e.getValue();// Increment count by 1.e.setValue(val == null ? 1L : val + 1);return null;}});// Stream words into the streamer cache.for (String word : text)stmr.addData(word, 1L);
5.2.5.StreamVisitor
StreamVisitor也是StreamReceiver的一个方便实现,他会访问流中的每个键值组。注意,访问器不会更新缓存。如果键值组需要存储在缓存内,那么需要显式地调用任意的cache.put(...)方法。
在下面的示例中,有两个缓存:marketData和instruments,收到market数据的瞬间就会将他们放入marketData缓存的流处理器,映射到特定market数据的集群节点上的marketData的流处理器的StreamVisitor就会被调用,在分别收到market数据后就会用最新的市场价格更新instrument缓存。
注意,根本不会更新marketData缓存,它一直是空的,只是直接在数据将要存储的集群节点上简单利用了market数据的并置处理能力。
CacheConfiguration<String, Double> mrktDataCfg = new CacheConfiguration<>("marketData");CacheConfiguration<String, Double> instCfg = new CacheConfiguration<>("instruments");// Cache for market data ticks streamed into the system.IgniteCache<String, Double> mrktData = ignite.getOrCreateCache(mrktDataCfg);// Cache for financial instruments.IgniteCache<String, Double> insts = ignite.getOrCreateCache(instCfg);try (IgniteDataStreamer<String, Integer> mktStmr = ignite.dataStreamer("marketData")) {// Note that we do not populate 'marketData' cache (it remains empty).// Instead we update the 'instruments' cache based on the latest market price.mktStmr.receiver(StreamVisitor.from((cache, e) -> {String symbol = e.getKey();Double tick = e.getValue();Instrument inst = instCache.get(symbol);if (inst == null)inst = new Instrument(symbol);// Update instrument price based on the latest market tick.inst.setHigh(Math.max(inst.getLatest(), tick);inst.setLow(Math.min(inst.getLatest(), tick);inst.setLatest(tick);// Update instrument cache.instCache.put(symbol, inst);}));// Stream market data into Ignite.for (Map.Entry<String, Double> tick : marketData)mktStmr.addData(tick);}
5.3.滑动窗口
5.3.1.摘要
滑动窗口是配置作为Ignite缓存的退出策略的,可以基于时间、基于大小或者基于批量。可以一个缓存配置一个滑动窗口,如果需要不同的滑动窗口,也可以容易地为同样的数据定义多于一个缓存。
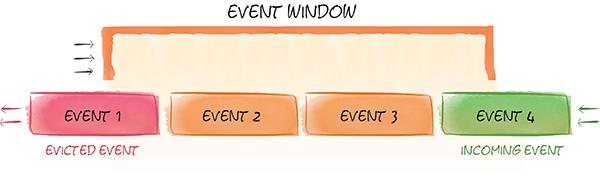
5.3.2.基于时间的滑动窗口
基于时间的滑动窗口可以用JCache标准的ExpiryPolicy进行配置,可以收到基于创建时间,最后访问时间,更新时间的流化过期事件。
下面是在Ignite中如何配置基于创建时间的5秒钟滑动窗口:
CacheConfiguration<Integer, Long> cfg = new CacheConfiguration<>("myStreamCache");// Sliding window of 5 seconds based on creation time.cfg.setExpiryPolicyFactory(FactoryBuilder.factoryOf(new CreatedExpiryPolicy(new Duration(SECONDS, 5))));
5.3.3.FIFO的滑动窗口
FIFO(先进先出)滑动窗口可以用FifoEvictionPolicy进行配置,这个策略是基于大小的,数据流会被插入窗口直到缓存的大小达到上限,那么最老的数据就会被自动踢出。
下面是如何配置一个FIFO的滑动窗口,他持有了100万的流化数据:
CacheConfiguration<Integer, Long> cfg = new CacheConfiguration<>("myStreamCache");// FIFO window holding 1,000,000 entries.cfg.setEvictionPolicyFactory(new FifoEvictionPolicy(1_000_000));
5.3.4.LRU滑动窗口
LRU(最近最少使用)滑动窗口可以用LruEvictionPolicy进行配置,这个策略是基于大小的,数据流会被插入窗口直到缓存的大小达到上限,那么最近最少使用的数据就会被自动踢出。
下面是如何配置一个LRU的滑动窗口,他持有了100万的流化数据:
CacheConfiguration<Integer, Long> cfg = new CacheConfiguration<>("myStreamCache");// LRU window holding 1,000,000 entries.cfg.setEvictionPolicyFactory(new LruEvictionPolicy(1_000_000));
5.3.5.查询滑动窗口
滑动窗口可以和任何其他Ignite缓存以同样的方式进行查询,可以使用基于谓词的,基于SQL的和基于文本的查询。
下面的代码是一个在金融工具流进入缓存后的滑动窗口中执行SQL查询的例子。
首先要在要查询的字段上创建索引:
CacheConfiguration<String, Instrument> cfg = new CacheConfiguration<>("instCache");// Index some fields for querying portfolio positions.cfg.setIndexedTypes(String.class, Instrument.class);// Get a handle on the cache (create it if necessary).IgniteCache<String, Instrument> instCache = ignite.getOrCreateCache(cfg);
然后要查询三个性能最好的金融工具,可以通过(latest - open) 价格进行排序然后选择靠前的三个:
// Select top 3 best performing instruments.SqlFieldsQuery top3qry = new SqlFieldsQuery("select symbol, (latest - open) from Instrument order by (latest - open) desc limit 3");// List of rows. Every row is represented as a List as well.List<List<?>> top3 = instCache.query(top3qry).getAll();
要查询所有金融工具的总利润,可以通过将所有的 (latest - open)值相加得到:
// Select total profit across all financial instruments.SqlFieldsQuery profitQry = new SqlFieldsQuery("select sum(latest - open) from Instrument");List<List<?>> profit = instCache.query(profitQry).getAll();System.out.printf("Total profit: %.2f%n", row.get(0));
5.4.单词计数示例
5.4.1.摘要
在这个例子中希望将文本流注入Ignite然后统计每个单独单词的总数,还会定期发布通过SQL在流中查询得到的十个最流行的单词。
示例会按照如下步骤进行工作:
- 设置缓存来持有单词和计数;
- 设置一个5秒的滑动窗口来保持最近5秒的单词计数;
StreamWords程序会将文本流数据注入Ignite;QueryWords程序会从流中查询最高的十个单词;
5.4.2.缓存配置
定义了一个CacheConfig类,他提供了两个程序(StreamWords,QueryWords)都会用到的配置信息,这个缓存会使用单词作为键,单词的计数作为值。
注意这个示例中在缓存中用了一个5秒的滑动窗口,这意味着单词从他第一次进入缓存开始5秒后就会从缓存中消失。
public class CacheConfig {public static CacheConfiguration<String, Long> wordCache() {CacheConfiguration<String, Long> cfg = new CacheConfiguration<>("words");// Index the words and their counts,// so we can use them for fast SQL querying.cfg.setIndexedTypes(String.class, Long.class);// Sliding window of 5 seconds.cfg.setExpiryPolicyFactory(FactoryBuilder.factoryOf(new CreatedExpiryPolicy(new Duration(SECONDS, 5))));return cfg;}}
5.4.3.单词流
StreamWords类负责从一个文本文件中持续地读入单词(例子中使用了alice-in-wonderland.txt)然后以流的方式注入Ignite“words”缓存。
流处理器配置
- 设置
allowOverwrite属性为true来确保已有的计数可以被更新; - 配置了一个
StreamTransformer,他会获取一个单词的当前计数然后加1。
public class StreamWords {public static void main(String[] args) throws Exception {// Mark this cluster member as client.Ignition.setClientMode(true);try (Ignite ignite = Ignition.start()) {IgniteCache<String, Long> stmCache = ignite.getOrCreateCache(CacheConfig.wordCache());// Create a streamer to stream words into the cache.try (IgniteDataStreamer<String, Long> stmr = ignite.dataStreamer(stmCache.getName())) {// Allow data updates.stmr.allowOverwrite(true);// Configure data transformation to count instances of the same word.stmr.receiver(StreamTransformer.from((e, arg) -> {// Get current count.Long val = e.getValue();// Increment current count by 1.e.setValue(val == null ? 1L : val + 1);return null;}));// Stream words from "alice-in-wonderland" book.while (true) {Path path = Paths.get(StreamWords.class.getResource("alice-in-wonderland.txt").toURI());// Read words from a text file.try (Stream<String> lines = Files.lines(path)) {lines.forEach(line -> {Stream<String> words = Stream.of(line.split(" "));// Stream words into Ignite streamer.words.forEach(word -> {if (!word.trim().isEmpty())stmr.addData(word, 1L);});});}}}}}}
5.4.4.查询单词
QueryWords类用于定期从缓存中查询单词计数。
SQL查询
- 使用标准SQL查询计数;
- Ignite SQL会将Java类视为SQL表,因为计数是以简单的
Long类型存储的,因此下面的SQL查询会查询Long表; - Ignite通常以
_key和_val字段名来保存键和值,因此在下面的SQL中使用这个语法。
public class QueryWords {public static void main(String[] args) throws Exception {// Mark this cluster member as client.Ignition.setClientMode(true);try (Ignite ignite = Ignition.start()) {IgniteCache<String, Long> stmCache = ignite.getOrCreateCache(CacheConfig.wordCache());// Select top 10 words.SqlFieldsQuery top10Qry = new SqlFieldsQuery("select _key, _val from Long order by _val desc limit 10");// Query top 10 popular words every 5 seconds.while (true) {// Execute queries.List<List<?>> top10 = stmCache.query(top10Qry).getAll();// Print top 10 words.ExamplesUtils.printQueryResults(top10);Thread.sleep(5000);}}}}
5.4.5.启动服务端节点
为了运行这个示例,需要启动数据节点,在Ignite中,数据节点称为服务端节点。可以根据需要启动尽可能多的服务端节点,但是至少要有一个节点来运行这个示例。
服务端节点可以通过如下的命令行来启动:
bin/ignite.sh
也可以像下面这样通过编程的方式来启动:
public class ExampleNodeStartup {public static void main(String[] args) throws IgniteException {Ignition.start();}}
