@liyuj
2018-01-27T08:38:56.000000Z
字数 814
阅读 4351
Apache-Ignite-2.3.0-中文开发手册
1.Ignite集成总览
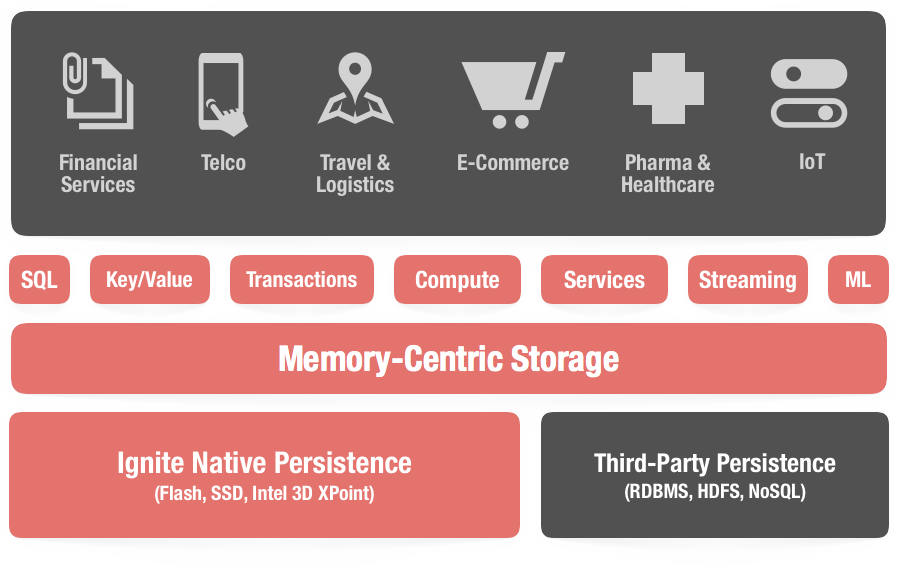
本系列集成文档包含了已有的所有有关Ignite和其他的技术和产品集成的信息。
集成的价值在于简化Ignite和应用、服务中使用的其他技术的结合,以便要么平滑地切换到Ignite,要么有助于将Ignite嵌入已有的系统。
现有的集成被分成下面的若干个领域:
集群化
Ignite可以部署在本地,也可以部署在云环境,有赖于和Amazon AWS、Google Compute Engine以及Apache JClouds的集成,Ignite集群可以部署在各种常见的云环境中。
Hadoop和Spark
Ignite的Hadoop加速器提供了一套组件,可以进行内存中的作业执行以及文件系统操作。对于Spark,Ignite通过一个SparkRDD抽象的实现对其进行了增强,他可以轻易地在内存中跨Spark作业共享状态。
内存缓存
这一部分的集成,Ignite将被用作纯粹缓存的目的,通常在这些场景中,Ignite以配置的方式启动,好处是可以避免代码层的修改。
OSGi支持
为了便于部署Ignite的不同模块,根据他们的依赖,Ignite提供了一组打包成特性库的Karaf特性,这意味着通过在Karaf shell中的一条命令就可以快速地将Ignite部署进OSGi环境。
与Apache Cassandra的集成
这个集成使得可以将Ignite和Cassandra整合在一起,其中Ignite作为分布式的内存系统,Cassandra作为持久化存储。一旦数据从Cassandra中预加载进Ignite,就可以在这个数据集上执行ANSI-99的SQL查询以及ACID的事务,让Ignite来保持内存和磁盘数据的同步就可以了。
流处理集成
Ignite可以和各种著名的流处理技术和产品进行集成,比如Kafka、Camel或者JMS,可以轻易且高效地将数据流数据注入Ignite。
