@liuruicai
2017-05-12T07:41:03.000000Z
字数 2928
阅读 1265
AI
Learn AI
第四次工业革命:人工智能(AI)入门
什么是AI
- 问题:类似医学诊断,预测机器故障时间或衡量某些资产的市值,涉及数千种数据集和大量变量之间的非线性关系
- 如何:数据优化和特征规范,data optimisation and feature specification
- 机器学习是AI的一个子集
- 机器学习算法的界定特征(Defining characteristic)就在于通过经验对预测结果进行改善所能取得的质量
the quality of their predictions imprrove with experience.- 目前机器学习的方法已超过15种
- 深度学习(最后关注)
- random forests,通过创建大量的决策树对预测进行优化
- Bayesian networks,使用基于概率的方法分析变量和变量之间的关系
- support vector machine(支持向量机),可通过多种分类样本并创建模型将新的输入内容分配给某一分类(that are fed categoriesed examples and crate model to assign new inputs to one of the categories)
- 深度学习是机器 学习的子集

- Pros
避免了程序员不得不自行处理特征规范
神经网络能在几科所有情况下做出正确的判断,实践出(近似的)直知- Cons
很难知道某个神经网络的预测能力是如何发展起来的
训练和运行需要投入大量计算处理能力深度学习如何工作
- 使用人造的“神经网络”,这是一种相互连接的“神经元”(基于软件的计算器)的集合
- 人造的神经元可接受一种或多种输入,进行数学运算,产生可输入的结果。
- 输出结果取决于每类输入的“权重”以及神经元的“输入-输入函数”配置
- 神经元可以是:
- 线性单位(Linear unit),输出结果与输入入总权重成比例;
- 阈值单位(Threshold unit),输出结果为两个级别中的一种,取决于输入是否高于某个特定值;
- S形单位(Sigmiod unit),输出结果频繁变化,不像输入那样呈线性变化 的态势。
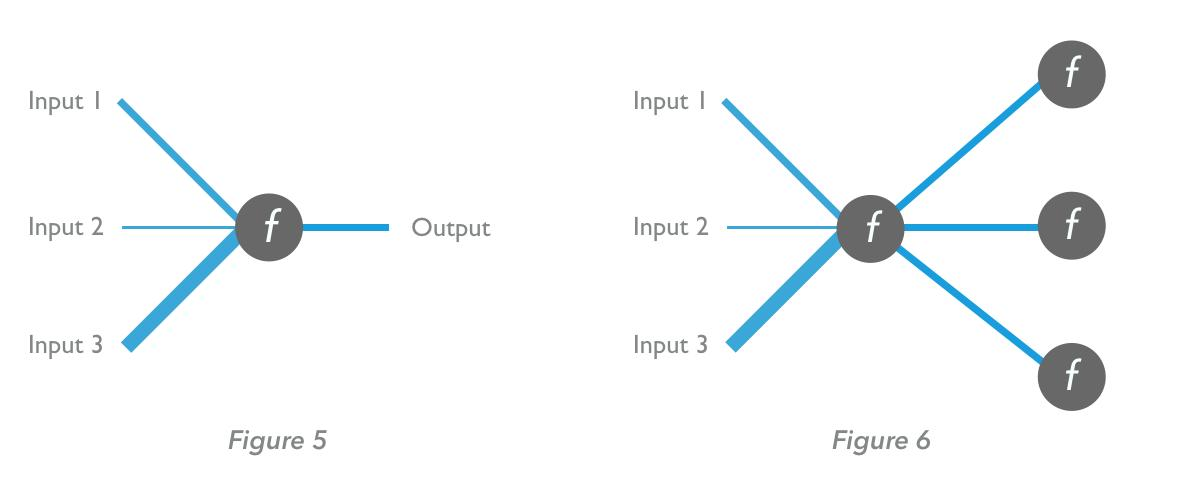
图5:直接输出的神经元;图6:一个神经元的输出成为另一个神经元的输入
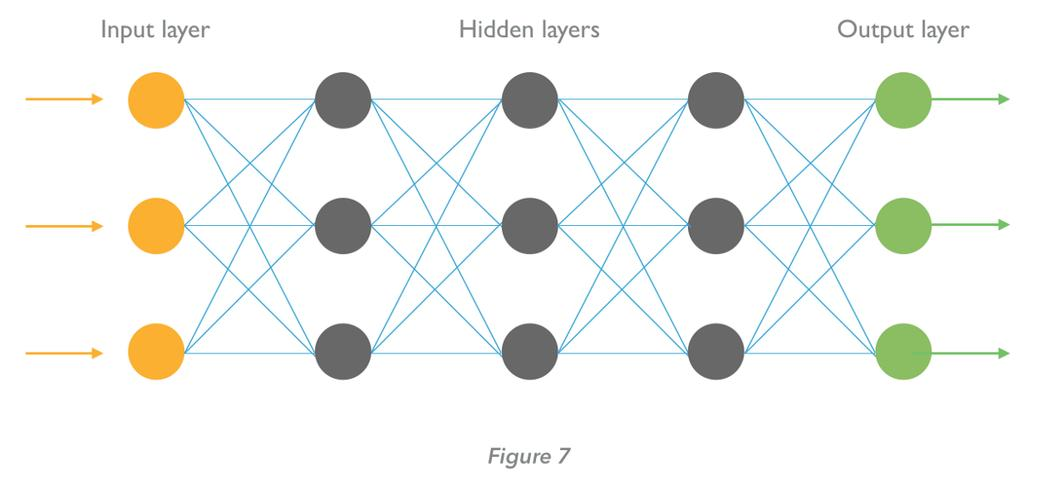
图7:神经网络可通过组织整理呈现为多层次神经元(这也是“深度”这个词的由来)

图8:人脸识别算法,数据装入神经网络后,第一层局部对比模式,例如图版边缘,这是一种底层特征。随着图片在整个网络中流动,逐渐提取出“高层”特征,例如从边缘到鼻子,再从鼻子到面孔。在输出层方面,根据训练效果,神经网络会就图片是每种特定类型的可能性给出概率(人脸:97%;气球:2%;树叶:1%)。- 训练过程:通常来说,神经网络的训练过程需要使用大量已经进行过分类的样本。随后算法会通过检测出的错误和神经元之间的连接权重进行调整,借此改善效果。
- 神经网络的设计和完善需要投入相当多的技能。例如针对特定应用调整网络结构,提供适宜的训练数据集,根据进展调整网络结构,以及多种方法的混合使用等。
为何如此重要:offer Revolutionayr, rather than Evolutionary
- 五大领域:five filds of enquiry:
- Resoing
- Knowledge
- Planning
- Communication:自然语言理解
- Perception:
为何到今天才开始成熟(1965年就有人提出第一个实际有效的多层神经网络规范:
- 算法改进
- 卷积神经网络(CNN, Convolutional Neural Networ),使识别图像中物体的能力实现了比人类更高的准确度(计算机:95.1%;人类:94.9%);同时递归神经网络(RNN, Recurrent Neural Network),使语音和手写识别取得悦事进展。
- RNN可通过反馈连接让数据呈环路流动。
- RNN还出现了一种更强大的新类型:长短期记忆(LSTM,Long Short-Term Memory)模型。在额外的连接和内存“细胞(Cell)”的帮助下,RNN可以“记住”自己在数千步操作之前看到的数据,并使用这些数据对后续需要关注的内容进行解释
- CNN,受到动物视觉脑皮层工作原理启发设计而来,神经网络中的每一层均可充当判断特定模式是否存在所用的筛选器
- 卷积神经网络仅“向下馈送”。
- 专用硬件
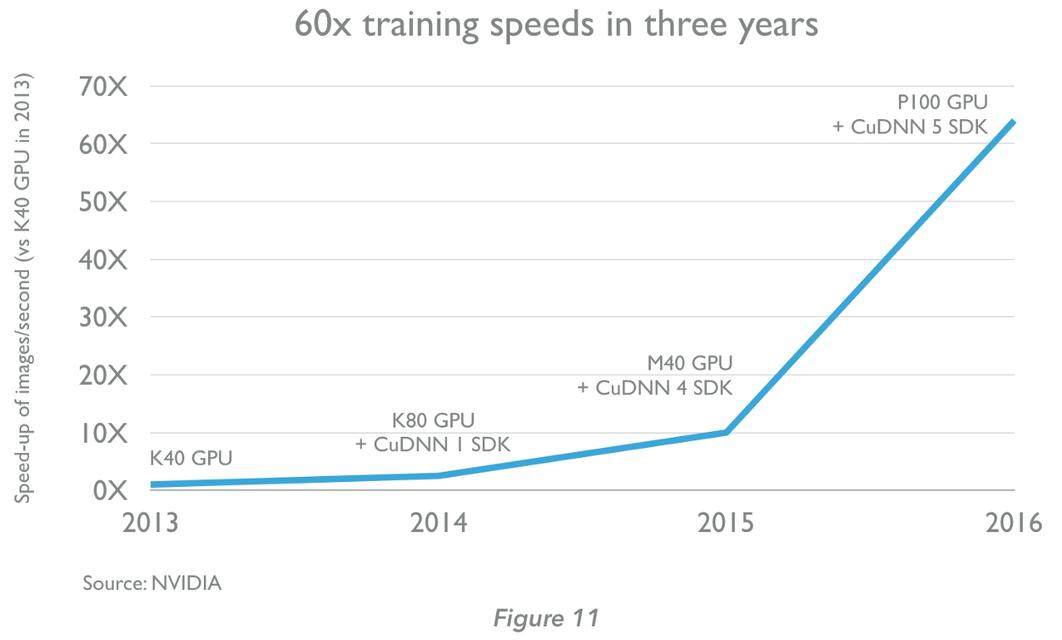
并行架构制造的GPU,可大幅缩短为深度学习训练神经网络所需的时间(Nvidia M40包含3,072个内核)。一颗GPU即可让神经网络的训练时间缩短5倍,比较大规模的问题甚至可实现10倍甚至更高的加速。如下图:- Extensive data(广博的数据)
- 深度学习所用的神经网络通常需要用大量数据集进行训练,样本数量从数千起步,甚至可高达数百万。
- 人类平均每天会生成2.2EB(23亿GB)数据,全球数据总量中有90%是过去24个月内创建的
- 三波数据时代:
第一波”的数据创建时代始于二十世纪八十年代,当时创建的主要是文档和事务数据- “第二波”数据时代,在可联网智能手机的推动下,诞生了大量非结构化媒体数据(邮件、照片、音乐、视频)、Web数据,以及各种元数据。
- “第二波”数据时代,在可联网智能手机的推动下,诞生了大量非结构化媒体数据(邮件、照片、音乐、视频)、Web数据,以及各种元数据。
- 1992年,全人类每天平均传输100GB数据,但到2020年,我们将每秒传输61,000GB数据
- ImageNet是一个免费提供的数据库,其中已经包含超过1千万张手工分类的图片。
- 云服务
- 使得机器学习能力的开发成本和难度大幅降低。
- 还提供了可直接用于自己应用程序内的一系列云端机器学习服务
- 兴趣和创业者: 公众对AI的兴趣在过去五年里增加了六倍
接下来会怎样?
- 与任何范式转变过程一样,有时过高的期望可能会超出短期内所能实现的潜力。As with any paradigm shift, at times inflated expectations will exceed short-term portential.
- 我们期待着未来某一时刻,人们对AI的幻想能够彻底幻灭,随之而来的将会是长期、持续的价值认可,因为机器学习已经被用于改善并革新现有的系统。
- 第一次工业革命在十八世纪八十年代使用蒸汽机驱动了机械化的生产过程;
- 第二次工业革命在十九世纪七十年代使用电力推动了商品的大规模量产;
- 第三次工业革命在二十世纪七十年代使用电子和软件技术实现了生产和交流的自动化。
- 今天,随着软件逐渐“蚕食”整个世界,我们创造价值的主要来源已成为信息本身的处理。通过用更智能的方式完成这样的工作,机器学习将低调地为我们带来效益和历史意义。

如何跨越人工智能技术与产品的鸿沟?
- 训练,向算法模型提供客户请求和相应的正确啥反应的样本数据。样本通常是静态化,结构化的数据,如csv数据格式
- 还需要新的数据 进行增量式的训练,公司应该及早投资机器学习架构,不断收集数据,并使用穿丝袜定期更新人工智能模型。
- 实时数据的使用面临着许多工程性挑战,包括调度,不停机模型迭代,稳定性和性能监控。
- GIGO(garbage in, garbage out)是机器学习的基本规则,所以一个良好的人工智能系统能够检测出潜在的问题,并在需要人工干预的时候向管理员发出警报。
- 克服构建信任的困难:如果客户不信任人工智能,就不会使用它驱动的产品
