@dongxi
2017-08-27T11:27:52.000000Z
字数 12229
阅读 2938
机器学习可行性-VC维度
0完成 机器学习 机器学习基石 CS229 Learning-From-Data
前言
机器学习是一种非常非常有力的工具,它能够通过一定的数据预测剩下的数据,实现一个学习的过程,但是机器学习为什么可以预测?本文借助VC维度这一概念,来粗浅的解释一下这个问题(本文章中,提及到的机器学习任务都默认是二分类问题,推广到其他问题与二分类问题相似)。
和
机器学习过程中,我们希望可以使用样本的统计量来估计总体的参数,所以我们必须要有一个假设,就是样本和总体服从同一分布,在我目前的认知中,这也是机器学习的最基本的条件,如果这一条件都无法满足,那么,我认为机器学习是无法进行的。所以,以下的所有问题,我们都假设样本和总体是服从同一分布的。
对于服从同一分布的情况,样本和总体会满足一定的条件,其中Hoeffding's Inequality就描述了这种性质:
上式中,表示样本的平均值,表示总体的平均值,表示我们的容忍度。同时,我们可以定义样本中错误概率和总体中的错误概率为:
那么,我们可以推导出:
所以只要右侧的上界足够小,我们就可以认为在样本的表现力与总体的表现力相似,但是这并不是意味着这个是一个很好地算法,很明显如果本身就很大,那么也并不会在总体上表现的很好。现在我们就可以将我们在最开始提出的问题进行简单的转换:
只要和都很小,那么就可以得到一个很小的,这也是我们的目的所在。因此我们需要一个较小的,所以我们通过在上选择一个最好的,用符号表示,,只要足够大,我们的选择范围就越广,那么就一定可以得到一个很小的,那么似乎我们的问题结束了,然而并不是这样。
我们是通过在上选择合适的,对于任意一个,我们都有成立,这主要是由于我们在选择样本是完全随机,可能就是选出来的样本对于不是很好,我们称这样的样本是一个,这种样本实际上不会对我们的产生什么影响,而在之前我们提及的在选择时,完全以为选择依据,那么只要对于任意一个,样本为就有可能导致我们最后选择的的很大,那么现在我们遇到的上界则变为了(表示中的数量):
换言之,是否足够小,在很大程度上与中的数目有关,如果我们的很小,那么得到就很难保证会很小,而如果很大,那么就无法保证可以保持在可以接受的范围内。
有效方程
在之前的推导中,我们使用了一个很大的上限,我们认为遇到等于每一个方程遇到的概率之和。这是一个很大的上界,如果方程,那么他们遇到的事件也应该是十分相似的,如下图,如果可以将接近的方程相互合并,那么或许可以将限制到一个可以接受的范围。
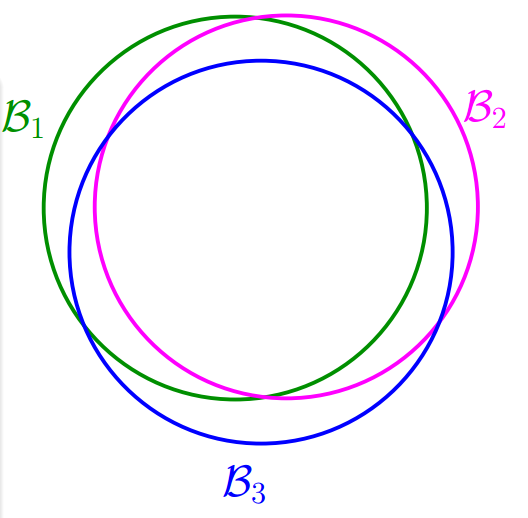
现在假设要从平面上挑选一条直线作为将一个数据进行分类,很显然中是有无数个方程的(参数范围为实数域),但是由于产生结果只有两类,所以可以将方程分为两类:
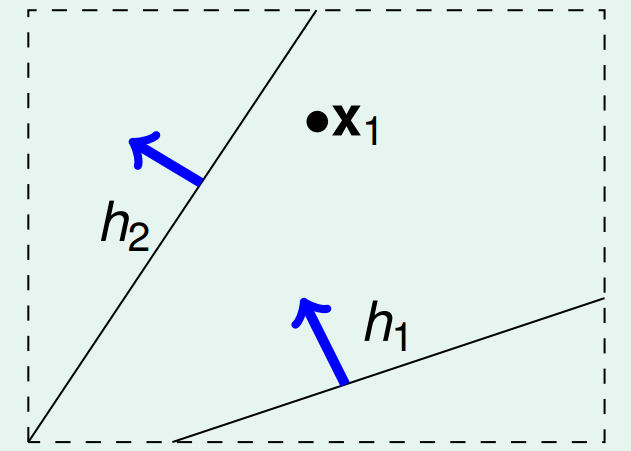
如果我们的数据点变为两个和,那么可以产生四种结果,也就意味着有四种直线:

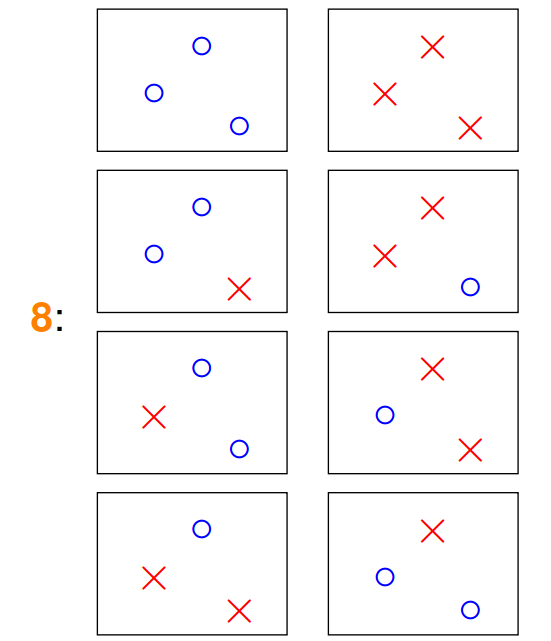
同理,如果有三个数据点,便可以出现8种分类结果,也就是会可以产生8类直线进行分割(不考虑三点共线的情况,在这里我们只讨论最多产生的直线分类):
那么,对于四个数据点的情况,我们可以出现16种分类组合,但是好像可以产生的分类类型出现了一点变化:
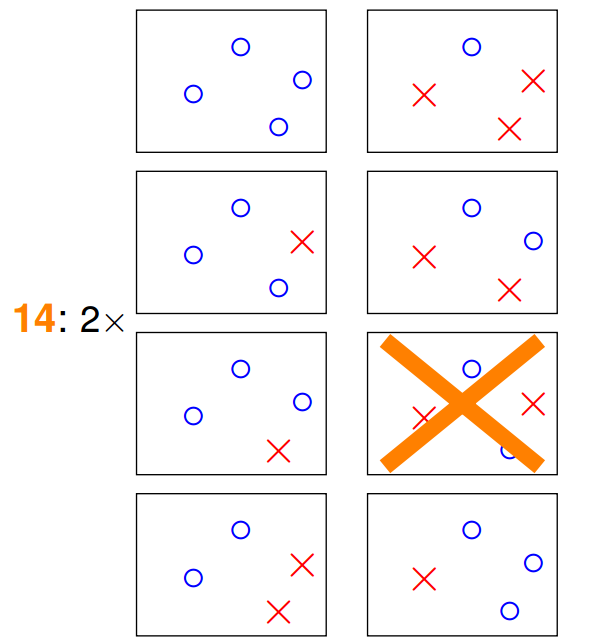
很明显有一种情况我们是无法用线性进行分割的,对于这种情况,我们最多产生14种直线进行分割。这里我并没有找到很严格的证明,但是我们可以启发性的认为属于同一类的直线,他们将会同时遇到/不遇到,所以新的上限可以进行一定程度的紧缩:
通过观察上式,我们发现只要能够让增加速度小于指数,比如多项式速度,那么只要我们取无限大的数据,就可以得到一个,那么我们如何推导呢?
增长函数
在以下的过程中,我们使用一个代表中一种类型的直线,而代表能够产生直线类型的集合,所以我们会有
那么,对于一个最多产生多少种不同的,很显然这是一个与和都相关的数据,我们可以用以下方式表示:
这个式子又被成为增长函数(Growth Function)。如果我们采用确定的进行机器学习过程,那么增长函数很显然是一个只与相关的函数。以下是几个常见的的成长函数:
Positive Rays

这是一个很简单的模型,如果大于值,那么我们就预测点为,反之则预测为,很明显,这时我们的增长函数为:。- Positive Intervals

与上述类似,使用简单的排列组合,可以推导出此时我们的成长函数为:。
3. Convex Sets

对于一个凸集合,从中任选个点,这些点包裹的空间范围,预测为,那么增长函数并不是多项式级别的,而是指数级别的,即:。
Shatter & Break Point
以上只是列举了少数几个特别简单的,那么对于一个不是那么简单的,比如多维空间的线性分割,我们该如何推导增长函数呢?
首先,我们引入两个比较简单的概念,Shatter和Break Point。如果当作用于有个样本的时,产生的数量与相等,那么我们就说这个输入被给shatter掉了。
对于一个给定的成长函数,从开始,对于第一个,使当时,永远有,那么我们称是成长函数的break point,也就是意味着对于任何的,都无法shatter(其实,只要break point为k,那么任何都不可能被shatter)。
以二维平面的线性分类问题为例,当时,总可以shatter,对于时,存在可以shatter的情况,但是当时,任何情况都不可以shatter,换言之,4便是该的break point。
我们简单推导一下这一过程,首先假设我们有个的break point为2,那么对于时,增加一个dichotomy,那么会有:
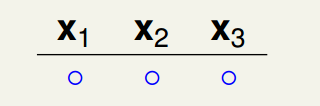
很显然,这是可能成立的,我们继续增加dichotomy,那么:
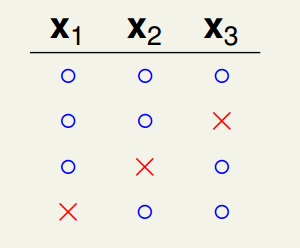
我们再增加一个我们继续增加dichotomy:
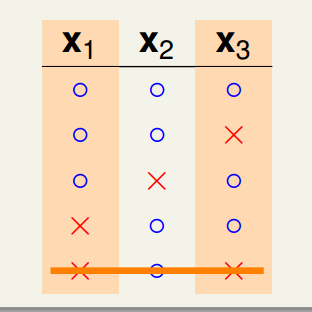
此时,出现了不可以被shatter的内容,因为我们已经列举了和的所有情况,这与的事实不符,继续尝试可以发现,我们已经无法增加任何组合了。因此,时,能够产生的dichotomies最多便是4种。
为了方便起见,我们采用表示的任意的能够产生的最大的dichotomies的数量(这里的是任意的,是一个很宽的上限,比如该例可能)。
虽然说,一般的情况下我们都是难以得到一个准确的,但是我们是可以推导出的上界的。我们可以很轻易的得到下表:
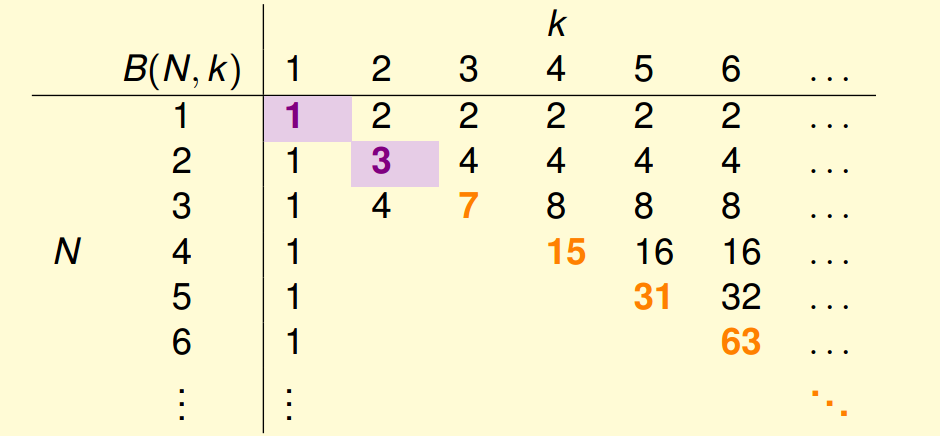
但是,如何能够填写表格中还处于空白的部分呢?我们穷举中所有的dichotomies穷举出来,然后进行简单的排序:
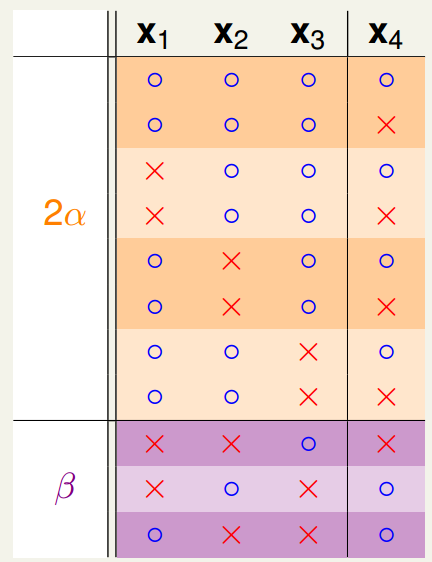
其中,部分中的都是成对出现的,而则都是单独存在的。下面我们去掉,然后将重复的部分进行合并:
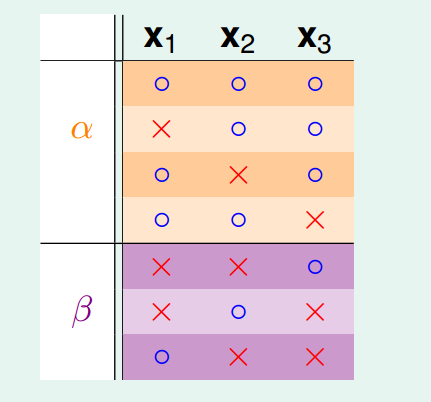
很显然,对于部分一定是不能被shatter的,所以会有:。接下来,单独看部分,则有:
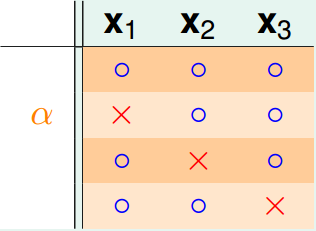
的情况下,是成对存在的,如果在可以被shatter掉任何两个点,那么就可以和产生的dichotomies就可以被shatter了,与我们的不符,因此不能被shatter任何两个点shatter,即:。
到目前为止,我们终于可以推导出了的上界,也就是:
同理,我们可以得到一个递推式:
通过数学归纳法,可以我们有():
到此为止,我们已经可以将前面的空白地方填充上:
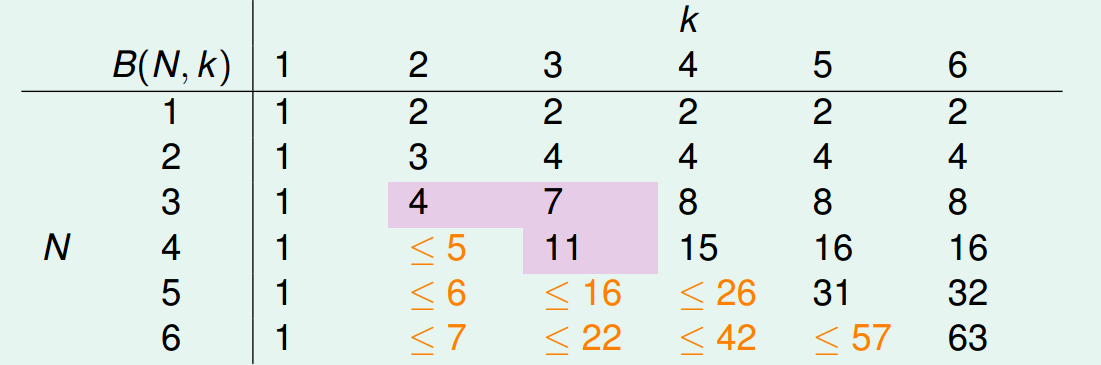
所以,只要我们能够求出的break point,那么只要样本足够大,我们就可以认为机器学习产生的结果是有效的,也就是。

VC维度
在前文中,我们可以知道如果中存在一个break point,那么就可以保证其增长速度一定是多项式级别的,同时根据上面的推导,很显然break point越大,那么相应的复杂度也就会越高,在这里引入VC维度(VC Dimension)这一概念来表述的复杂度(实际上,直接用break point也应该是可以的描述的)。
一个的VC维度(记为)描述了其能在任何情况shatter的最多的点集中点数目,很显然,,因此增长函数的上界可以变更为:
VC bound
到目前为止,我们似乎已经将要证明的东西证明出来了,在确定这件事之前,我们在确定一下,现在我们有的不等式可以写成这样:
仔细观察下,发现好像有点不大对,我们之所以能够推导出一个,是因为中点的数目有限,所以产生的是有限的,才可以将分类,然而对于out of sample的情况,点是无穷无尽的,很显然只要产生任意一点的变化,求得的就会发生变化,因此对于来说,是有限的,而对于则是无限的,而这种无限可能无法更改的。那么现在我们希望能够将进行简单的替换,把变为有限个。
假设我们能够在总体中再取得笔资料作为验证集(Verification Set),那么对于任何一个,我们都可以求出一个有限的,我们启发式的认为如果的概率与差距很大的话,那么与也不会很相似。
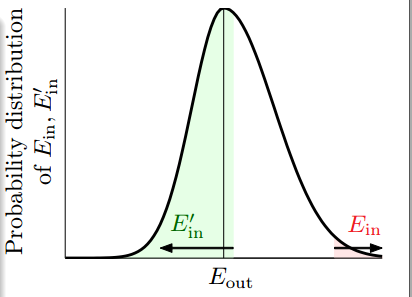
实际上,由于中心极限定理可以知道当很大的时候,可以服从以为中心的近似的正态分布,如上图。事件发生完全取决于。如果已经发生了,则如果我们从总体中在抽出一份,则会有50%左右的概率会发生,还有大概50%的概率,实际上,最终我们可以得到如下结论(表示上确界):
从RHS出发,会有(主要运用了贝叶斯公式):
再来看下不等式的最后一项,对于一个固定的来说,的选择是只与有关,而与无关的,对于一个固定的,任选一个使,成立,那么上式变为:
再引入一个比较有意思的东西:
很明显,LHS的两个式子是RHS的充分条件,而在原式中是作为条件的,那么原式又可以进一步的转换:
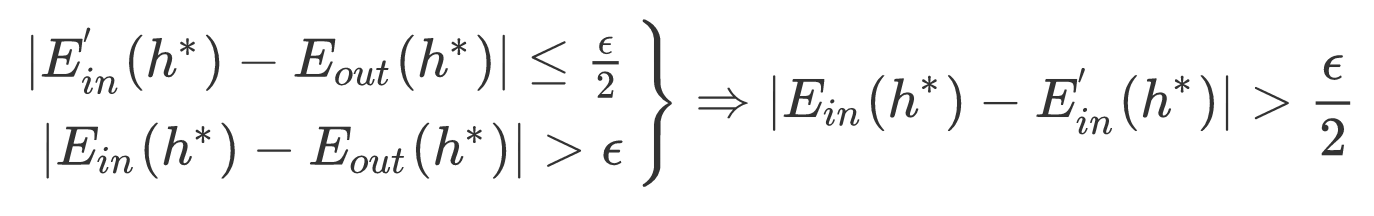
第一个不等号就是上面叙述的内容,第二个不等号主要运用了Hoeffding Inequality,推导如下:
在之前的讨论中,明确了的选择与无关,那么很很显然成立,将原式带入就可以得到,到目前为止我们就得到了之前提及的式子,也就是:
对一般可以采取一个比较合理的约束,,在此时将带入上式,则会有:
这与上面我们启发式的讨论的相似,现在我们可以认为我们一次取得了笔数据,分别为和,而则变为了出现在最多能产生的dichotomies数目了。所以,我们新的为:
前面的数据相当于建立一个
N的bin,然后从中抽取N个数据(不放回抽取),那么我我们需要知道新的bin中的分布,如果可以知道这个分布,那么我们就可以使用Hoeffding without replacement,将之推算出来了,而bin中的分布为,又因为:
所以原式又可以进行一定的转换:
这个上限被称为VC bound:
这便是机器学习可行性的理论保障之一。总的来说,如果希望机器学习可以进行那么就要求有以下三个要求:
- 的有限,保障VC Bound存在。(good )
- 相对于足够大,这样可以保证bound有意义。(good \mathcal{D})
- 算法能够选择一个足够优秀的,使足够小。(good )
对于较小的,我们可以比较容易的求出到什么情况完全无法在shatter了,但是对于比较复杂的模型就比较困难了,这时可以根据模型的自由度(模型中可以自由变动的参数个数,即我们的机器需要通过学习来决定的参数个数)近似的得到一个。比如我们之前的例子:
- Positive Rays:需要确定1个参数,这个参数就是机器需要根据来确定的一个参数,则Positive Rays中自由的参数个数为1,即;
- Positive Intervals:需要确定左右2个参数,则可以由机器自由决定的参数的个数为2,;
- d-D Perceptrons:d维的感知机,可以由机器通过学习自由决定的参数的个数为, 。
模型选择
回顾我们之前提及的两个问题:
- 和能否足够接近;
- 能否足够小。
这就导致了如果我们选择的不能过大,同样也不能过小,要合适才好,不过,合适才是最难的。令,那么我们希望的发生概率就变为了,其中又被称为置信度。经过简单的推导,我们可以得到为:
那么,我们可以将和可以表示为:
其中称为模型复杂度,一般用表示,模型复杂度用来衡量和的差异程度。我们可以绘制出下图:
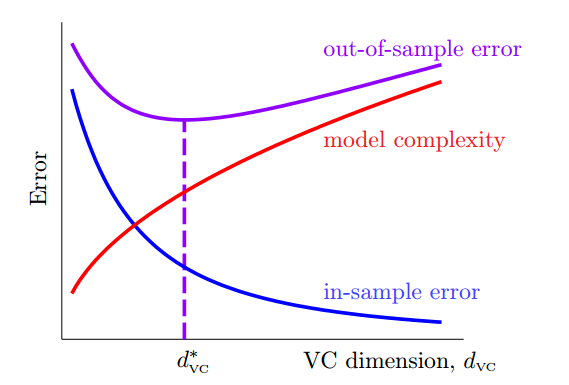
很显然,是最好的情况,由此可见,合适的才是最好的。
很显然,随着的增大而减小,理论上讲,只要有无穷无尽的数据,我们的也可以很大很大,但是我们不可能有无穷无尽的数据,所以对于一个需要多少数据量呢?一般来说,我们希望保证置信率,根据VC Bound计算大致上,不过这是一个很宽松的范围,在经验上,一般来说满足就可以得到比较好的结果了。
总结
本篇文章最开始是由于CS 229中关于VC维度那章节去查阅资料时,发现机器学习基石好像最初的几节课都是在讲这个东西的,就去看了机器学习基石,可是没想到前七节课都是讲的这个,然后就索性全都看了,还买了书。
在写本篇文章时,很大程度上借鉴了机器学习笔记中的内容,其中的内容写的确实很详尽,建议阅读。
参考
Machine Learning Foundations (機器學習基石)
机器学习笔记
Learning From Data
