@dongxi
2017-08-04T13:07:38.000000Z
字数 8127
阅读 1897
朴素贝叶斯算法
机器学习 CS229
前言
朴素贝叶斯是另一种生成学习算法,不过与高斯判别分析不同,朴素贝叶斯针对的则是特征向量为离散值的情况。它比较典型的应用范围就是文本分类,以下也以文本分类为例对朴素贝叶斯进行简单的了解。
朴素贝叶斯分类器
与其他分类算法相同,朴素贝叶斯算法也需要标注好的数据集,其中对于文本分类问题来说,一般采用向量空间模型(vector space model)来表示文本。下面是一个文本的表示示例:
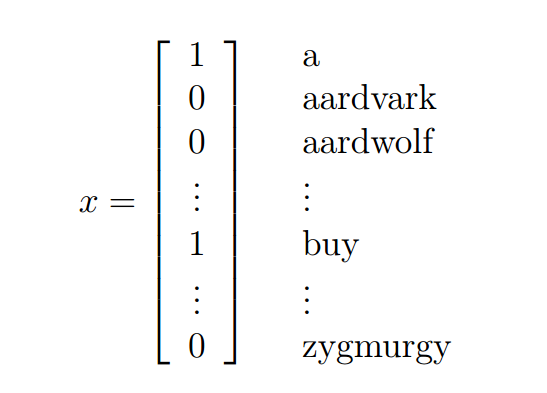
如果我们的要对进行建模,其中,,也就是意味着字典中有50000个单词,这样当我们直接对有种输出的多项分布建模时,我们的参数向量就会达到维(我认为这里指的应该就是参数向量)(突然感觉好像离散值的分类算法用生成算法不是很赞啊 瞎猜的 待验证),客观的讲这是不现实的。而在朴素贝叶斯算法中,增加了一种理想化的假设,那就是特征向量的所有维度都是不相关的,基于这种假设我们会有:
那么我们可以引入参数如下:
那么我们的联合似然函数为(其中为字典大小):
其中:
那么带入公式我们可以有:
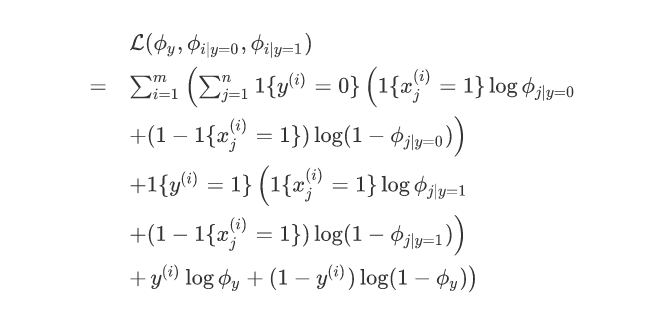
接下来我们分别对他们求偏导数:
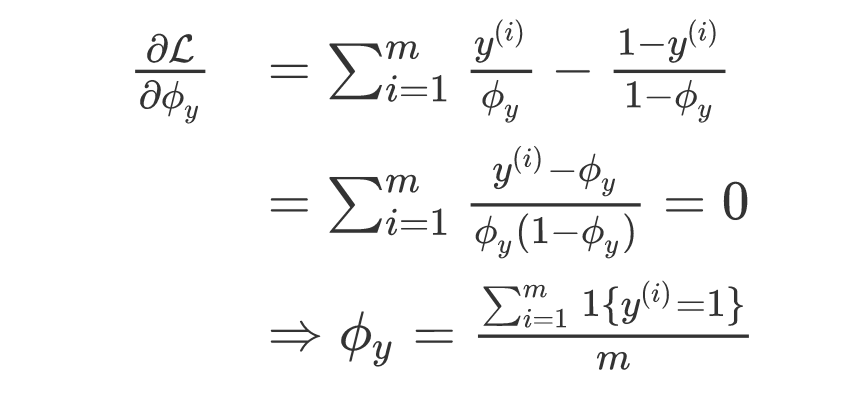
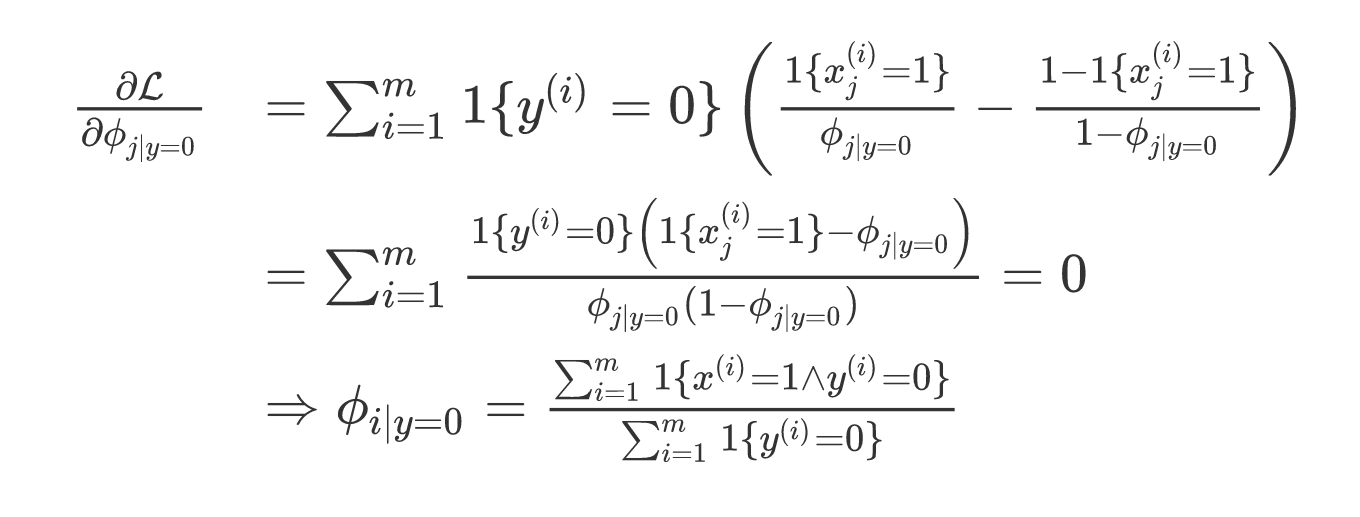
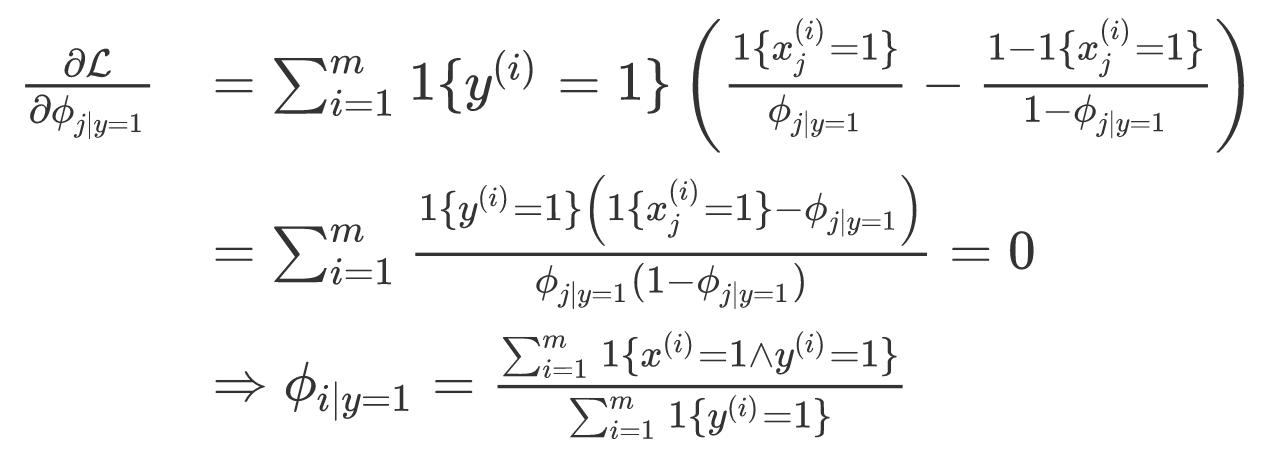
对于新样本我们可以通过公式很容易的得到计算结果:
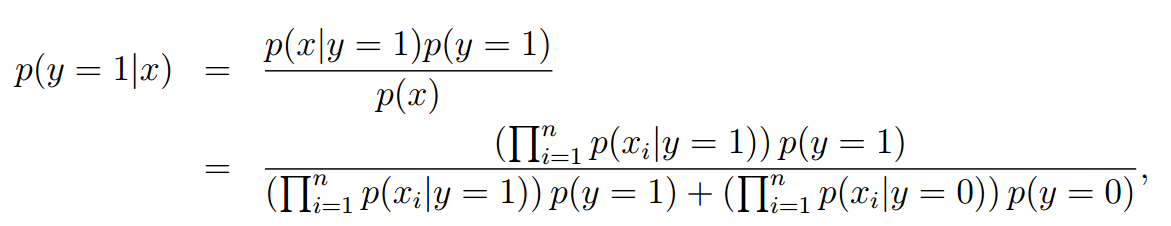
但是由于概率的取值范围为,多个概率相乘的结果可能会非常小,以至于产生下溢出,所以我们可以取对数进行等价处理。
拉普拉斯平滑
拉普拉斯平滑,主要是用于解决零概率的问题,又被成为+1平滑。
给定个训练样本,那么根据最大似然估计求出的参数。如果特征在训练集上,那么,仅仅由于在训练集上未出现就就将概率设置为0在统计学上是十分不合理的。为了避免这种情况,我们引入了拉普拉斯平滑,通过分子分母在原来的统计基础上增加一个常数,来达到平滑的目的。
多项分布型朴素贝叶斯
现在对当前的内容进行适当地扩展,我们不在认为,而是,相对于之前我们的参数公式来说,和,与之前是完全相同的,而则发生了较大的变化:
那么,似然函数的形式如下:
考虑到存在约束条件和,我们在似然函数的对数形式中引入拉格朗日乘子,得到如下函数:
接下来采用最大似然估计的方式,对各个参数求偏导:
又因为和,结合上式我们可以得到:
接下来我们将和带入,则有:
观察求出来的参数,我们对其进行拉普拉斯平滑:
那么最终导出的分类准则如下:
朴素贝叶斯与连续型数据
对于前面说的两种朴素贝叶斯分类器都只适用于离散型随机变量,如果遇到连续型的数据该如何处理呢?对于这种问题可以采用两种常用的方法:概率分布估计和离散化。
概率分布估计
对于连续型数据,我们通常假设该数据在每类样本中都各自服从高斯分布和(做出其他分布假设也是可以的,但是一般都采用高斯分布模型)。由于在朴素贝叶斯中假设样本每一个属性都是条件独立的,那么每一个属性都可以有不同的概率分布,如下图所示:
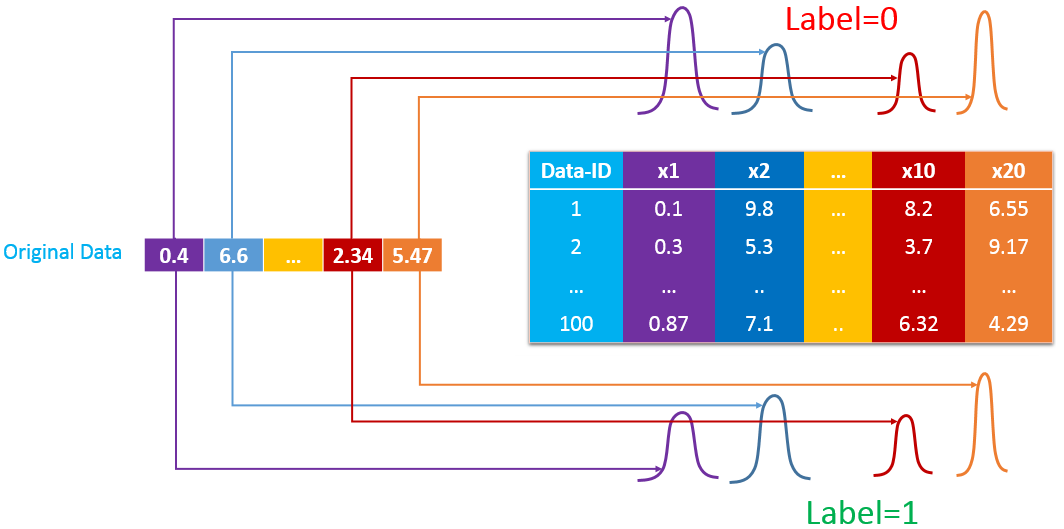
此时我们的模型参数包括一个伯努利分布的参数和个高斯分布的模型参数、、和。模型中的概率关系如下:
还是假设我们有个训练样本,那么我们会有如下的似然函数:
将上述函数转换成对数形式:
对各个参数求偏导数:
同理可得:
我们继续求方差的偏导数:
同理可得:
实际上,就是训练集中正样本出现的频率,和则分别表示正样本和负样本的第维均值,和分别表示正样本和负样本特征第维的方差。
离散化
对于连续值的问题也可以将其离散化为个有限的离散值(一般),这样就转化成多项分布的朴素贝叶斯算法了。假设我们有很多维联系的特征需要离散化处理,如下图所示,第一维数据被划分为两个区间,第二维数据被划分为四个区间,如果原始数据第一维和第二维分别落入第二个和第三个,那么离散化后的数值分别为2和3。
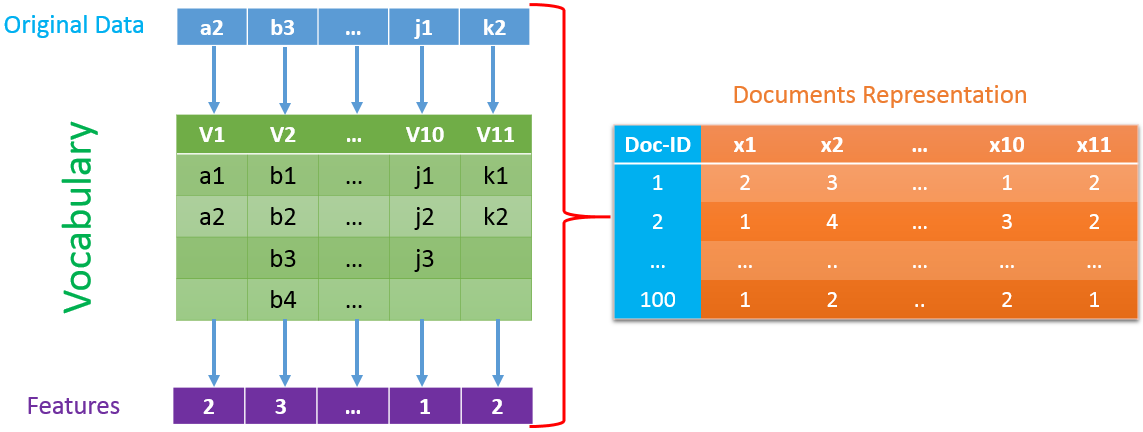
在这里我们假设每一维的数据都是连续值,原始特征的第维连续数据经离散化后变成了个离散数据,每个样本对应的标签信息。所以模型之中存在的参数以及概率关系与多项分布的朴素贝叶斯模型是相同的,所以就不再继续推导一遍了(这种方法在Ng的讲义中也提及到了)。
概率分布与离散化的选择
上面两种方案在使用过程中该如何选择呢?一般来说,如果训练数据较少或者我们大致知道数据的概率分布,那么选择概率分布模型效果会比较好;当有大量训练数据时,往往离散化的方法也会有不错的表现,这是由于其模型相对更加复杂(???),整个学习过程实际上是在不断拟合数据的实际概率分布,而概率分布模型则是假设数据满足了某种概率分布进行学习过程的,就如同在之前的文章中提到了的。
一般来说,朴素贝叶斯模型更多的被用于有大量训练数据的应用场景,所以离散化的技术手段使用的也更加广泛些。根据我们的经验,简单的模型容易产生欠拟合的现象,而复杂的模型容易产生过拟合的情况。在训练数据比较小的时候,由于复杂模型比较容易出现过拟合的问题,所以简单模型的泛化能力要比复杂模型好一些,但这时两者都只能学习到数据中的极少数特点;当数据很充足时,简单模型则会出现欠拟合的问题,其泛化能力并不会因训练集的增大而增强,这时就是复杂模型更加适用的情况了。
结语
本篇文章大量借鉴了参考一中的内容,在看到这篇文章之后,我几乎把整篇文章重写了一遍,从某些程度而言,我就是将那篇文章中前后不一致的地方一致化,同时去掉一些我认为不需要的地方,需要注意的是之前我一直以为其中的是,所以在我的博客中会出现不一致的现象,对于之前的我就不再进行改动了,但是之后的文章则会对这一部分进行修改。
