@awsekfozc
2016-02-17T13:37:17.000000Z
字数 1160
阅读 2607
Spark Deploy
Spark
Deploy mode
client: 开发测试时使用这个模式
本地,应用提交的这台机器上
cluster: 生产环境使用这个模式
运行在集群的work节点上
client
bin/spark-submit \--deploy-mode client \--class org.apache.spark.examples.SparkPi \--master spark://hadoop-zc.com:7077 \/opt/modules/spark-1.3.0-bin-2.5.0/lib/spark-examples-1.3.0-hadoop2.5.0.jar \10
cluster
bin/spark-submit \--deploy-mode cluster \--class org.apache.spark.examples.SparkPi \--master spark://hadoop-zc.com:7077 \/opt/modules/spark-1.3.0-bin-2.5.0/lib/spark-examples-1.3.0-hadoop2.5.0.jar \10
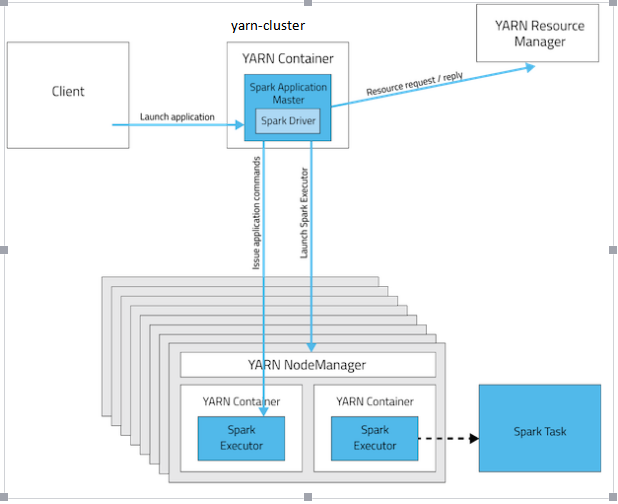
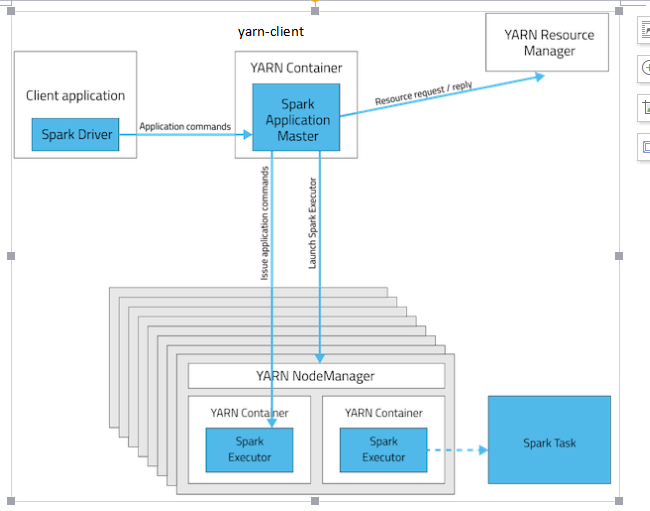
spark on yarn
Spark on yarn有分为两种模式yarn-cluster和yarn-client。yarn-cluster和yarn-client模式的区别其实就是Application Master进程的区别,yarn-cluster模式下,driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行。然而yarn-cluster模式不适合运行交互类型的作业。而yarn-client模式下,Application Master仅仅向YARN请求executor,client会和请求的container通信来调度他们工作,也就是说Client不能离开。一下是两种模式的提交代码:
bin/spark-submit \--master yarn-client \--class org.apache.spark.examples.SparkPi \/opt/modules/spark-1.3.0-bin-2.5.0/lib/spark-examples-1.3.0-hadoop2.5.0.jar \10
bin/spark-submit \--master yarn-cluster \--class org.apache.spark.examples.SparkPi \/opt/modules/spark-1.3.0-bin-2.5.0/lib/spark-examples-1.3.0-hadoop2.5.0.jar \10
在此输入正文
