@awsekfozc
2015-11-20T10:22:08.000000Z
字数 2466
阅读 1945
hadoop分布式部署(虚拟机下)
分布式部署
虚拟机设置
修改主机名
$ sudo hostname hadoop02.zc.com$ sudo vi /etc/sysconfig/network

设置网卡
删除网卡:$ vi /etc/udev/rules.d/70-persistent-net.rules//复制下图红色部分 mac地址

设置mac地址$ sudo vi /etc/sysconfig/network-scripts/ifcfg-eth0//上面复制的mac地址,设置到下图红色部分

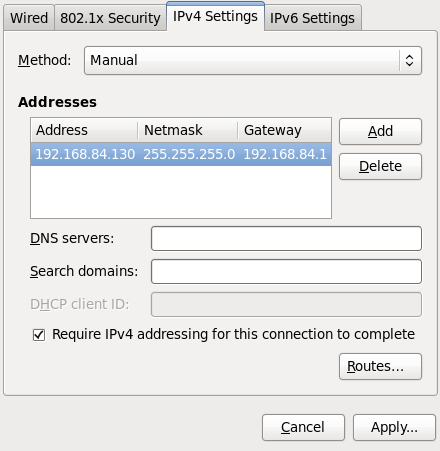
IP设置
映射设置
$ sudo vi /etc/hosts
虚拟机内映射

windows映射
C:\Windows\System32\drivers\etc\hosts

系统环境清理
删除/tmp目录下的数据
$ cd /tmp/$ sudo rm -rf ./*
删除原有hadoop
$ cd /opt/moduels/$ rm -rf hadoop-2.5.0/
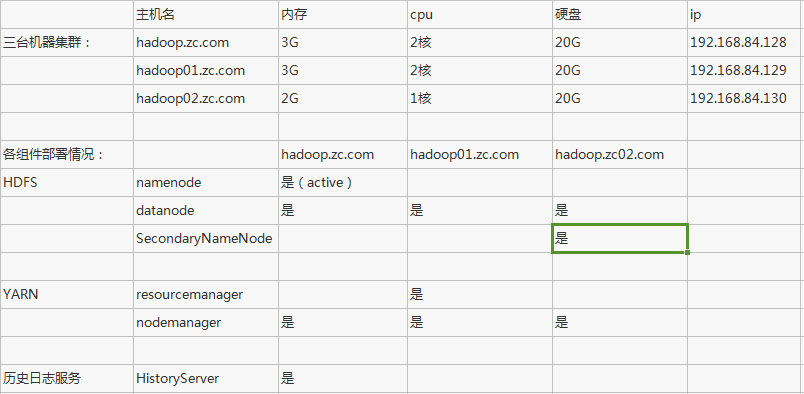
规划集群
设计表格
具体配置
core-site.xml
<configuration><!--namenode--><property><name>fs.defaultFS</name><value>hdfs://hadoop.zc.com:8020</value></property><!--本地目录--><property><name>hadoop.tmp.dir</name><value>/tmp/hadoop-${user.name}</value></property><!--默认用户--><property><name>hadoop.http.staticuser.user</name><value>zc</value></property></configuration>
hdfs-site.xml
<configuration><!--权限检查--><property><name>dfs.permissions.enabled</name><value>false</value></property><!--副本数--><property><name>dfs.replication</name><value>2</value></property><!--secondary服务--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop02.zc.com:50090</value></property></configuration>
slaves
hadoop.zc.comhadoop01.zc.comhadoop02.zc.com
yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--配置ResourceManager--><property><name>yarn.resourcemanager.hostname</name><value>hadoop01.zc.com</value></property><!--启用日志聚集--><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!--aggregation(日志聚集)保留时间,秒。--><property><name>yyarn.log-aggregation.retain-seconds</name><value>100800</value></property></configuration>
mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><!--历史日志服务内部地址,mapred-site.xml--><property><name>mapreduce.jobhistory.address</name><value>hadoop.zc.com:10020</value></property><!--历史日志服务地址web,mapred-site.xml--><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop.zc.com:19888</value></property></configuration>
复制至各个节点
$ scp -r hadoop-2.5.0/ zc@hadoop02.zc.com:/opt/app/
启动集群
1)格式化HDFS
$ bin/hdfs namenode -format
2)启动namenode
$ sbin/hadoop-daemon.sh start namenode
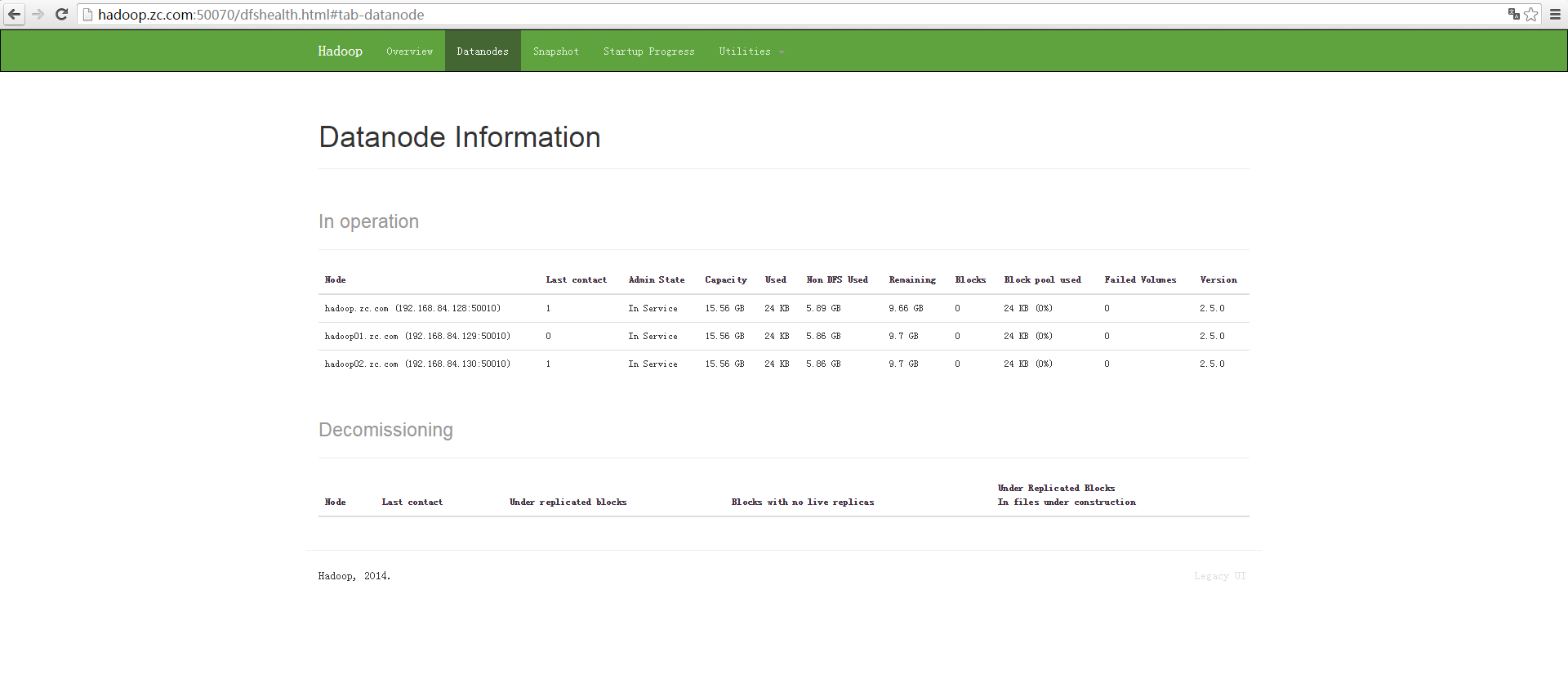
3)启动datanode(各个配置是datanode的节点都要启动)
$ sbin/hadoop-daemon.sh start datanode
4)启动resourcemanager
$ sbin/yarn-daemon.sh start resourcemanager
5)启动nodemanager(各个nodemanager点都要启动)
$ sbin/yarn-daemon.sh start nodemanager
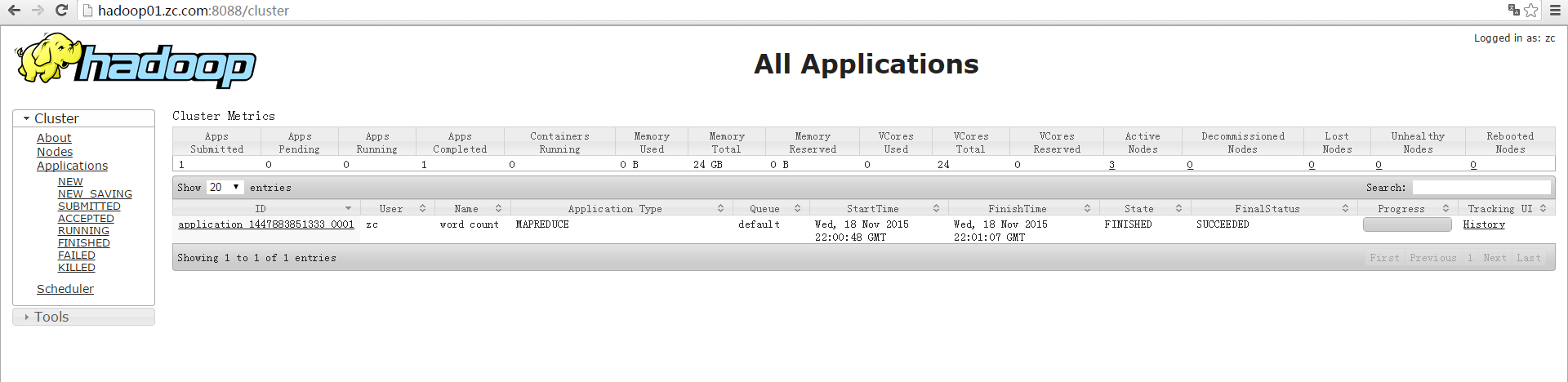
测试集群
1)上传文件
$ bin/hdfs dfs -put /opt/datas/wc.input data

1)运行mapreduce
$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wrodcount data output

