@awsekfozc
2015-12-11T17:20:55.000000Z
字数 3296
阅读 2886
Hive ETL
Hive
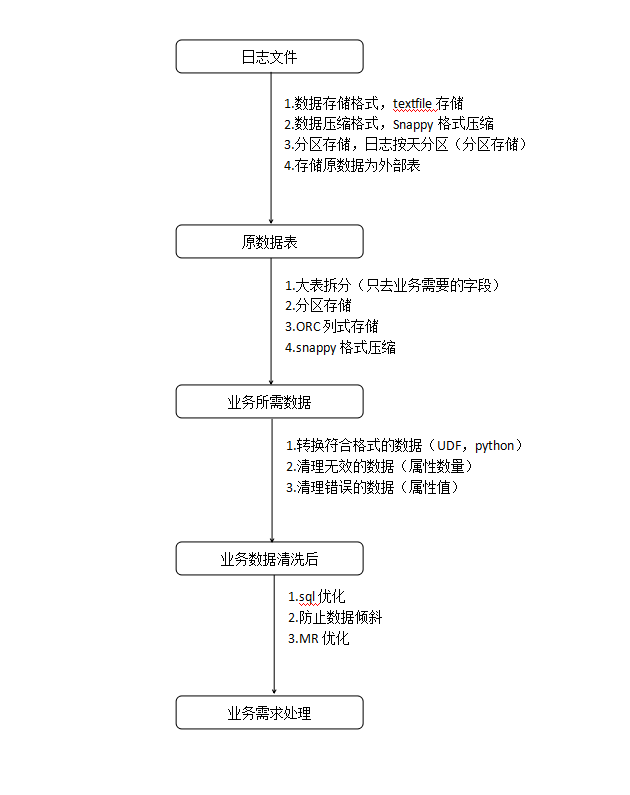
日志文件处理
1.数据存储设计
1.数据存储格式,textfile列式存储
2.数据压缩格式,Snappy格式压缩
3.分区存储,日志按天分区(分区存储)
4.存储原数据为外部表
5.属性分割,正则表达式分割
2.创建代码
use db_bf_log ;drop table IF EXISTS db_bf_log.bf_log_src ;create EXTERNAL table db_bf_log.bf_log_src (remote_addr string,remote_user string,time_local string,request string,status string,body_bytes_sent string,request_body string,http_referer string,http_user_agent string,http_x_forwarded_for string,host string)PARTITIONED BY (month string, day string)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'WITH SERDEPROPERTIES ("input.regex" = "(\"[^ ]*\") (\"-|[^ ]*\") (\"[^\]]*\") (\"[^\"]*\") (\"[0-9]*\") (\"[0-9]*\") (-|[^ ]*) (\"[^ ]*\") (\"[^\"]*\") (-|[^ ]*) (\"[^ ]*\")")stored as textfile tblproperties ("orc.compress"="SNAPPY");##说明:1.存储格式:textfile2.分区字段:month,day3.压缩格式:SNAPPY4.外部表:EXTERNAL5.分割类型:SERDE(row format)
2.数据加载
use db_bf_log ;load data local inpath '/opt/datas/moodle.ibeifeng.access.log' overwrite into table db_bf_log.bf_log_src partition(month = '201512',day = '10');
3.数据查询
select * from bf_log_src where month='201512' and day='10' limit 5;
原数据处理
1.数据存储设计
1.大表拆分(只取业务需要的字段)
2.分区存储
3.ORC列式存储
4.snappy格式压缩
2.创建代码
use db_bf_log ;drop table if exists db_bf_log.df_log_comm ;create table IF NOT EXISTS db_bf_log.df_log_comm (remote_addr string,time_local string,request string,http_referer string)PARTITIONED BY (month string, day string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'stored as orc tblproperties ("orc.compress"="SNAPPY");##说明:1.存储格式:ORC2.分区字段:month,day3.压缩格式:SNAPPY
3.数据加载
use db_bf_log ;INSERT into TABLE df_log_comm PARTITION(month='201512', day='10')select remote_addr, time_local, request, http_referer from db_bf_log.bf_log_src;
3.数据查询
select * from df_log_comm where month='201512' and day='10' limit 5;

数据清洗
1.清洗计划
1.转换符合格式的数据(UDF,python)
2.清理无效的数据(属性数量)
3.清理错误的数据(属性值)
2.UDF
3.python
创建python脚本(my.py)
import sysimport datetimefor line in sys.stdin:line = line.strip()userid, movieid, rating, unixtime = line.split('\t')weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()print '\t'.join([userid, movieid, rating, str(weekday)])
加载脚本
add FILE /opt/datas/my.py;
脚本清洗数据
INSERT OVERWRITE TABLE u_data_newSELECTTRANSFORM (userid, movieid, rating, unixtime)USING 'python my.py'AS (userid, movieid, rating, weekday)FROM u_data;
优化设置(hive-site.xml)
Fetch Task
<property>
<name>hive.fetch.task.conversion</name>
<value>minimal</value>
<description>
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (TABLESAMPLE, virtual columns)
</description>
</property>
MR压缩设置
1.设置map输出压缩
hive.exec.compress.intermediate=true
mapreduce.map.output.compress=true
mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec
2.设置reduce输出压缩
hive.exec.compress.output
mapreduce.output.fileoutputformat.compress
mapreduce.output.fileoutputformat.compress.codec
并行性
hive.exec.parallel.thread.number=8
hive.exec.parallel=true;
JVM重用
mapreduce.job.jvm.numtasks=4
Reduce的数目
设置数目通过测试获得,测试各种数目根据正太分布图取最后结果。
mapreduce.job.reduces=0;
推测执行
hive.mapred.reduce.tasks.speculative.execution=true;
mapreduce.map.speculative=true;
mapreduce.reduce.speculative=true;
数据倾斜[1]
其他帮助文档
1.正则在线工具
2.Hive DDL,文档1,文档2
3.Hive DML,文档1,文档2
4.Hive UDF,文旦1,文档2
5.
在此输入正文
