@awsekfozc
2016-01-08T16:11:01.000000Z
字数 3000
阅读 4778
OpenTSDB介绍
OpenTSDB
参考来源:
http://www.searchtb.com/2012/07/opentsdb-monitoring-system.html
http://opentsdb.net/docs/build/html/index.html
http://www.ttlsa.com/opentsdb/opentsdb-setup/
http://blog.csdn.net/bluishglc/article/details/31052749
http://www.jianshu.com/p/0bafd0168647
1)简介
OpenTSDB是基于HBase存储时间序列数据的一个开源数据库,确切地说,它只是一个HBase的应用。主要用途,就是做监控系统;譬如收集大规模集群(包括网络设备、操作系统、应用程序、环境状态)的监控数据并进行存储,查询。
opentsdb极大的方便了运维人员,可以动态的增加metrics。可以灵活支持任何语言的收集器。因此使用它降低了开发和维护成本。
优势:
1. 使用Hbase存储,不存在单点故障。 2. 使用Hbase存储,存储空间几乎无限。支持永久存储,可以做容量规划 3. 易于定制图形 4. 能扩展采集数据点到100亿级。 5. 能扩展metrics数量到K级别(比如CPU的使用情况,可以算作一个metric,即metric就是1个监控项) 6. 支持秒级别的数据。
2)架构
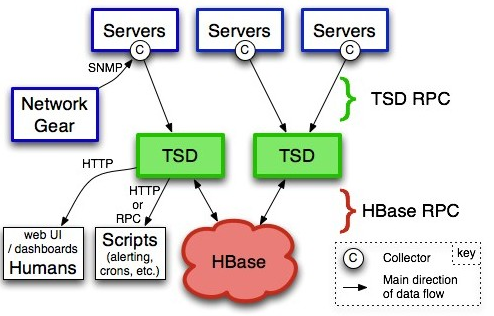
- servers:需要收集数据的对象,可以网络设备、操作系统、应用程序等等。每个servers需要设置一个Collector用来收集时间序列数据
- Collector:收集数据的程序,可以使python,使用HBase API,shell等等。
- TSD:对外通信的无状态的服务器,Collector可以通过TSD简单的RPC协议推送监控数据;另外TSD还提供了一个web UI页面供数据查询;另外也可以通过脚本查询监控数据,对监控数据做报警
- Hbase:TSD收到监控数据后,是通过AsyncHbase这个库来将数据写入到HBase;AsyncHbase是完全异步、非阻塞、线程安全的Hbase客户端,使用更少的线程、锁以及内存,可以提供更高的吞吐量,特别对于大量的写操作。
3)Hbase中存储时间序列
场景
譬如假设我们采集1个服务器(hostname=qatest)的CPU使用率,发现该服务器在21:00的时候,CPU使用率达到99%
下面结合例子看看OpenTSDB存储的一些核心概念
- Metric:即平时我们所说的监控项。譬如上面的CPU使用率
- Tags:就是一些标签,在OpenTSDB里面,Tags由tagk和tagv组成,即tagk=takv。标签是用来描述Metric的,譬如上面为了标记是服务器A的CpuUsage,tags可为hostname=qatest
- Value:一个Value表示一个metric的实际数值,譬如上面的99%
- Timestamp:即时间戳,用来描述Value是什么时候的;譬如上面的21:00
- Data Point:即某个Metric在某个时间点的数值。
Data Point包括以下部分:Metric、Tags、Value、Timestamp。上面描述的服务器在21:00时候的cpu使用率,就是1个DataPoint保存到OpenTSDB的,就是无数个DataPoint。
要素
我们先创建一个Metric:cpu-zc-use。用来收集cpu使用情况的一个指标。
$ ./build/tsdb mkmetric cpu-zc-use##插入一条数据cpu-zc-use 1451084030437 20.3 host=foo type=user
如果我们从不同的机器和用户下收集了大量的cpu信息,如果没有对一条信息进行一定地标识,我们是无法区分出哪些数据来自哪台机器的哪个用户,所以我们还需要建立一些“标签”(Tag)来标识一条数据。严格地说,指标和标签之间并没有必然的从属关系,就像两个不同的指标的数据可能都有指示其来自哪台主机的host标签一样,但是有一点是确定的,即:对于一条数据来说,应该至少含有一个指标和一个标签,这样的数据才是有意义的,因此,在OpenTSDB的表设计上,就把“指标”(metrics)和“标签”(Tag)统一放在了tsdb-uid表中存储,格式为:RowKey(自增ID,3字节数组):name:metrics,name:tagk,name:tagv,同时对它们之间的反向关联关系也作了展开存储。
tsdb-uid表:这里其实保存的就是一些metric,tagk,tagv的一些映射关系。
第一条记录:rowkey为\x00,含3个字段:metrics,tagk,tagv, 其值分别是已经添加的所有指标、标签名和标签值的数量。这一条数据是系统生成和维护的。这里有两个metrics:cpu和mem,两个key:host和type,两个value:foo和user,所以 rowkey为\x00的三个数据的value都是2
一个UID是针对一种指标+一种标签名+一种标签值的组合分配的,即:一种指标+一种标签名+一种标签值 = 一个UID,也就是说:一个UID对应的一种指标+一种标签名+一种标签值的组合才是可以单独抽取出来时行统计的最小单位!

tsdb表:一下是cpu-zc-use的两个datapoint

rowkey如下图所示

一些设计技巧:
针对Hot Spot的应对策略
一般来说,如果使用时间做rowkey,那么前面就必须加“哈希”字段(也就是salted处理)。但是OpenTSDB并没有特别的哈希字段,它的处理比较聪明:首先,时间字段不会放在rowkey的开始位置,其次,rowkey开始位置挑选了自身的一个理想的业务字段“metrics"来替代了“哈希”字段。
从OpenTSDB的处理上我们可以总结出一点:在处理时间序列数据时,如果系统中存在“理想的”“天然的”起哈希作用的字段应该优先考虑其作为rowkey的起始组成部分,后接时间字段,但如果找不到这样的字段再设置人工的哈希字段
- rowkey的设计思想
一.为了能够检索特定的metrics,tag name,tag name的data point, 将 metrics,tag name,tag name编入rowkey是显然的事情,但是直接使用它们来组成rowkey有两个明显的问题:
- 会占用大量的存储空间(因为这些值会大量重复地出现在很多的rowkey中)
- 由于每一个metrics,tag key,tag value的长度都是不固定的,这不利于通过字节偏移量来直接定位它们.(否则需要使用特定的分隔符,而且为了避免输入信息中可能存在特定的分隔符导致解析出错,还要对所有输入信息的分割符进行转义处理)
围绕一个性能指标,会有多种附加"属性"(或者说"标签")对其进行说明与描述, 那么对指标的查询也自然是以这些标签或标签值展开的,因此一条指标记录的rowkey必然要包含这些标签和标签值.但是由于标签和标签值是不定长的,这为rowkey的设计带来麻烦,所以需要为这些标签和标签值分配一个定长的ID,在rowkey中使用它们的ID来指代它们,这样rowkey就可以规范化,方便从rowkey中直接通过偏移截取需要的"部分".
在此输入正文
