@awsekfozc
2016-01-27T05:47:39.000000Z
字数 1393
阅读 1668
Spark App
Spark
Job submit
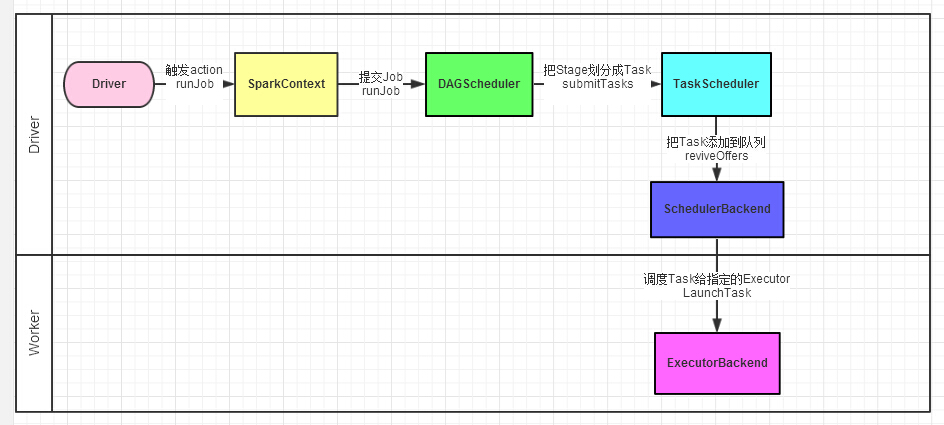
1. Driver程序的代码运行到action操作,触发了SparkContext的runJob方法。SparkContext创建Executors
2. SparkContext调用DAGScheduler的runJob函数。
3. DAGScheduler把Job倒推划分stage,然后把stage转化为相应的Tasks,把Tasks交给TaskScheduler。
4. 通过TaskScheduler把Tasks添加到任务队列当中,交给SchedulerBackend进行资源分配和任务调度。
5. 调度器给Task分配执行Executor,ExecutorBackend负责执行Task。
History Server
##spark-env.sh HDFS要创建这个目录才能启动成功SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop.zc.com:8020/user/zc/spark/logs"##spark-defaults.confspark.eventLog.enabled truespark.eventLog.dir hdfs://hadoop.zc.com:8020/user/zc/spark/logsspark.eventLog.compress true##cmd$ sbin/start-history-server.sh##端口18080

代码
package com.zc.bigdata.spark.appimport org.apache.spark._/*** Created by zc on 1/20/15.*/object FirstSparkApp {def main(args: Array[String]) {val inputFile = "hdfs://hadoop.zc.com:8020/user/zc/spark/input" ;val outputFile = "hdfs://hadoop.zc.com:8020/user/zc/spark/output" ;// create SparkConfval sparkConf = new SparkConf() //.setAppName("firstSparkApp") //.setMaster("local[2]")// create SparkContxtval sc = new SparkContext(sparkConf)// create RDDval rdd = sc.textFile(inputFile)// rdd transformationval wordCountRdd = rdd.flatMap(line => line.split(" ")) //.map(word => (word,1)) //// .sortByKey() //.reduceByKey((a,b) => (a + b))// rdd action// wordCountRdd.foreach(println)wordCountRdd.saveAsTextFile(outputFile)sc.stop()}}
提交任务:$ bin/spark-submit --master spark://hadoop.zc.com:7077 /opt/datas/jar/sparkApp.jar
在此输入正文
