@awsekfozc
2016-01-08T11:09:37.000000Z
字数 3361
阅读 1926
MapReducew五大过程
MapReduce
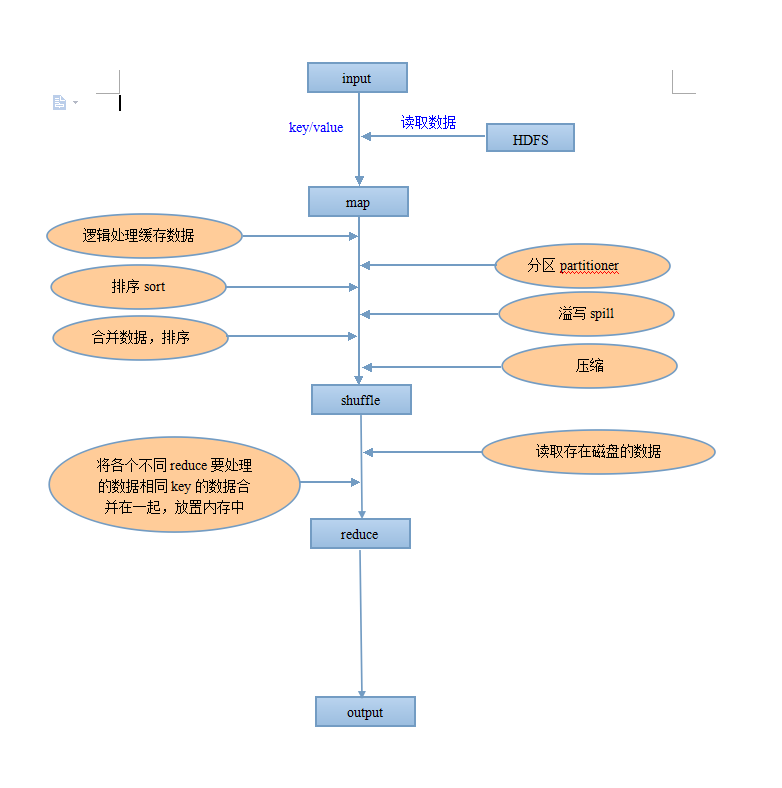
Input
- 将输入日志数据,数据库数据输入到map函数 (key-value形式)
- 一行记录对于一个键值对(key-value)
Map
1)每个节点都需要执行代码(需要打成jar包)
2)对输入的数据做逻辑处理。
3)接受一个键值对(key-value),产生一组中间键值对。map函数产生的中间键值对里键相同的值传递给一个reduce函数。
4)map任务结束之前,将处理的结果放置再内存中(默认大小为100M),称之为“环形缓冲区”。当内存占到一定比率时(默认80%),把内存中的数据溢写到磁盘(spill)
Shuffle
map shuffle
1)分区partitioner:当map在内存中的数据溢写到磁盘之前。根据reduce的不同。自动将数据分为到不同的区域。决定了map输出的数据被那个对应的reduce处理。
2)排序sorter:对分区中的数据排序,此时数据还在内存之中,排序速度快。
3)溢写spill:上述过程完成后,将数据写到spill到本地磁盘。
4)合并merge:当map处理数据结束以后。合并各个分区的数据,排序合并后的数据。形成一个分区完成排序完成的文件。
5)map端的reduce(combiner)(可选,不是所有mapreduce都能设置combiner)
6)压缩:压缩Map输出的数据
参数设置
<!-- mapred-site.xml --><!--Map任务CPU最小核数--><property><name>mapreduce.map.cpu.vcores</name><value>1</value></property><!--Reduce任务CPU最小核数--><property><name>mapreduce.reduce.cpu.vcores</name><value>1</value></property><!--在排序时合并的流的数目--><property><name>mapreduce.task.io.sort.factor</name><value>10</value></property><!--环形缓存的大小--><property><name>mapreduce.task.io.sort.mb</name><value>100</value></property><!--缓存区的限制(80%)--><property><name>mapreduce.map.sort.spill.percent</name><value>0.80</value></property>
分区设置(partitioner)
/*** map shuffle 分区设置(partitioner)*/package com.zc.hadoop.shuffle;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Partitioner;public class TestPartitioner extends Partitioner<Text, Text>{public int getPartition(Text arg0, Text arg1, int arg2) {// TODO Auto-generated method stubreturn 0;}}/*** mapreduce中调用*/job.setPartitionerClass(TestPartitioner.class);
排序,分组设置(srot,group)
/*** map shuffle 排序,分组设置(srot,group)*/package com.zc.hadoop.shuffle;import org.apache.hadoop.io.RawComparator;import com.zc.hadoop.mapreduce.WordCountMr;import com.zc.hadoop.mapreduce.WordCountMr.WCMapper;public class TestRawComparator implements RawComparator<WordCountMr.WCMapper> {public int compare(WCMapper arg0, WCMapper arg1) {// TODO Auto-generated method stubreturn 0;}public int compare(byte[] arg0, int arg1, int arg2, byte[] arg3, int arg4,int arg5) {// TODO Auto-generated method stubreturn 0;}}/*** mapreduce中调用*/job.setCombinerClass(TestRawComparator.class);job.setGroupingComparatorClass(TestRawComparator.class);
combiner设置
/*** combiner*/package com.zc.hadoop.shuffle;import java.io.IOException;import java.util.Iterator;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapred.OutputCollector;import org.apache.hadoop.mapred.Reporter;import org.apache.hadoop.mapreduce.Reducer;public class TestCombiner extends Reducer<Text, IntWritable, IntWritable, Text>{public void reduce(Text key, Iterator<IntWritable> values,OutputCollector<IntWritable, Text> output, Reporter reporter)throws IOException {// TODO Auto-generated method stub}}/*** mapreduce中调用*/job.setCombinerClass(WordCountCombiner.class);
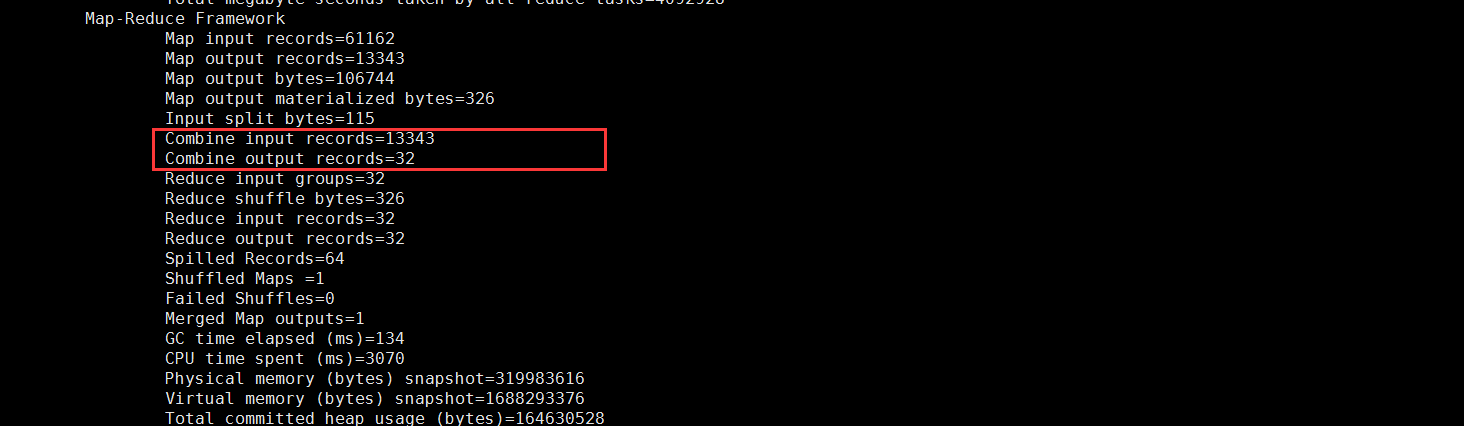
combiner结果
压缩设置(comperss)
/*** 设置配置(代码设置方式)* param1:* param2:*//*** param1:启用压缩* param2:true 启用*/configuration.set("mapreduce.map.output.compress", "true");/*** param1:设置压缩类型* param2:类路径*/configuration.set( "mapreduce.map.output.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
<!--配置设置方式--><!--启用压缩--><property><name>mapreduce.map.output.compress</name><value>true</value></property><!--设置压缩方式--><property><name>mapreduce.map.output.compress.codec</name><value>org.apache.hadoop.io.compress.SnappyCodec</value></property>
reduce shuffle
1)读取数据:已完成的map task存储在本地磁盘的数据(map shuffle过程一将之,分组,合并,排序)。为各个reduce task去拉取每个reduce要处理的数据。将相同key的数据合并在一起,放置再内存中。
Reduce
1)接收合并好的数据,业务处理
2)结果写入磁盘
Output
输出reduce后的数据到文件系统中。
在此输入正文
