@CrazyHenry
2018-04-19T12:27:53.000000Z
字数 6896
阅读 3982
faiss教程跟进--Makefile
hhhhfaiss
- Author:李英民 | Henry
- E-mail: li
_yingmin@outlookdotcom- Home: https://liyingmin.wixsite.com/henry
快速了解我: About Me
转载请保留上述引用内容,谢谢配合!
官方教程:https://github.com/facebookresearch/faiss/wiki
编译所有教程
在目录:/home/users/yingmin.li/proj/faiss_proj/faiss/tutorial/cpp下执行:make all #即5个都编译make cpu #编译1、2、3make gpu #编译4、5make clean #删除二进制文件只编译其中一个,比如编译4-GPU:make 4-GPU #注意没有.cpp
看懂了80%的Makefile:
MAKEFILE_INC=../../makefile.inc-include $(MAKEFILE_INC)NVCCLDFLAGS = -Xcompiler \"-Wl,-rpath=../../:../../gpu/\" \-L../.. -L../../gpu -lfaiss -lgpufaissLDFLAGS = -L../.. -Wl,-rpath=../.. -lfaiss#在此添加新的程序all: cpu gpu #make all 指令所执行的范围cpu: 1-Flat 2-IVFFlat 3-IVFPQ #观察all: cpu gpugpu: 4-GPU 5-Multiple-GPUs #观察all: cpu gpu1-Flat: 1-Flat.cpp ../../libfaiss.$(SHAREDEXT)$(CXX) -o $@ $(CXXFLAGS) $< -I../../../ $(LDFLAGS)2-IVFFlat: 2-IVFFlat.cpp ../../libfaiss.$(SHAREDEXT)$(CXX) -o $@ $(CXXFLAGS) $< -I../../../ $(LDFLAGS)3-IVFPQ: 3-IVFPQ.cpp ../../libfaiss.$(SHAREDEXT)$(CXX) -o $@ $(CXXFLAGS) $< -I../../../ $(LDFLAGS)#GPU版本的写法同样可以编译CPU的程序4-GPU: 4-GPU.cpp ../../libfaiss.$(SHAREDEXT) ../../gpu/libgpufaiss.$(SHAREDEXT)$(NVCC) $(NVCCFLAGS) -o $@ $< $(NVCCLDFLAGS) -I../../../5-Multiple-GPUs: 5-Multiple-GPUs.cpp ../../libfaiss.$(SHAREDEXT) \../../gpu/libgpufaiss.$(SHAREDEXT)$(NVCC) $(NVCCFLAGS) -o $@ $< $(NVCCLDFLAGS) -I../../../#在此添加新的程序../../libfaiss.$(SHAREDEXT):cd ../../ && make libfaiss.$(SHAREDEXT)../../gpu/libgpufaiss.$(SHAREDEXT):cd ../../gpu/ && make libgpufaiss.$(SHAREDEXT)clean:rm -f 1-Flat 2-IVFFlat 3-IVFPQ 4-GPU 5-Multiple-GPUs #删除所有可执行程序
看一下makefile.inc
# Copyright (c) 2015-present, Facebook, Inc.# All rights reserved.## This source code is licensed under the BSD+Patents license found in the# LICENSE file in the root directory of this source tree.# -*- makefile -*-# tested on CentOS 7, Ubuntu 16 and Ubuntu 14, see below to adjust flags to distribution.CC=gccCXX=g++ #CXX原来是g++CFLAGS=-fPIC -m64 -Wall -g -O3 -mavx -msse4 -mpopcnt -fopenmp -Wno-sign-compare -fopenmpCXXFLAGS=$(CFLAGS) -std=c++11 #使用c++11LDFLAGS=-g -fPIC -fopenmp# common linux flagsSHAREDEXT=so #这里就是一个soSHAREDFLAGS=-sharedFAISSSHAREDFLAGS=-shared########################################################################### Uncomment one of the 4 BLAS/Lapack implementation options# below. They are sorted # from fastest to slowest (in our# experiments).############################################################################ 1. Intel MKL## This is the fastest BLAS implementation we tested. Unfortunately it# is not open-source and determining the correct linking flags is a# nightmare. See## https://software.intel.com/en-us/articles/intel-mkl-link-line-advisor## The latest tested version is MLK 2017.0.098 (2017 Initial Release) and can# be downloaded here:## https://registrationcenter.intel.com/en/forms/?productid=2558&licensetype=2## The following settings are working if MLK is installed on its default folder:## MKLROOT=/opt/intel/compilers_and_libraries/linux/mkl/## BLASLDFLAGS=-Wl,--no-as-needed -L$(MKLROOT)/lib/intel64 -lmkl_intel_ilp64 \# -lmkl_core -lmkl_gnu_thread -ldl -lpthread## BLASCFLAGS=-DFINTEGER=long## you may have to set the LD_LIBRARY_PATH=$MKLROOT/lib/intel64 at runtime.# If at runtime you get the error:# Intel MKL FATAL ERROR: Cannot load libmkl_avx2.so or libmkl_def.so.# You may add set# LD_PRELOAD=$MKLROOT/lib/intel64/libmkl_core.so:$MKLROOT/lib/intel64/libmkl_sequential.so# at runtime as well.# 默认使用OpenBLAS,比MKL慢30%# 2. Openblas## The library contains both BLAS and Lapack. About 30% slower than MKL. Please see# https://github.com/facebookresearch/faiss/wiki/Troubleshooting#slow-brute-force-search-with-openblas# to fix performance problemes with OpenBLASBLASCFLAGS=-DFINTEGER=int# This is for Centos: #默认使用centosBLASLDFLAGS?=/usr/lib64/libopenblas.so.0# for Ubuntu 16:# sudo apt-get install libopenblas-dev python-numpy python-dev# BLASLDFLAGS?=/usr/lib/libopenblas.so.0# for Ubuntu 14:# sudo apt-get install libopenblas-dev liblapack3 python-numpy python-dev# BLASLDFLAGS?=/usr/lib/libopenblas.so.0 /usr/lib/lapack/liblapack.so.3.0## 3. Atlas## Automatically tuned linear algebra package. As the name indicates,# it is tuned automatically for a give architecture, and in Linux# distributions, it the architecture is typically indicated by the# directory name, eg. atlas-sse3 = optimized for SSE3 architecture.## BLASCFLAGS=-DFINTEGER=int# BLASLDFLAGS=/usr/lib64/atlas-sse3/libptf77blas.so.3 /usr/lib64/atlas-sse3/liblapack.so## 4. reference implementation## This is just a compiled version of the reference BLAS# implementation, that is not optimized at all.## BLASCFLAGS=-DFINTEGER=int# BLASLDFLAGS=/usr/lib64/libblas.so.3 /usr/lib64/liblapack.so.3.2############################################################################ SWIG and Python flags #对于我没啥用########################################################################### SWIG executable. This should be at least version 3.xSWIGEXEC=swig# The Python include directories for a given python executable can# typically be found with## python -c "import distutils.sysconfig; print distutils.sysconfig.get_python_inc()"# python -c "import numpy ; print numpy.get_include()"## or, for Python 3, with## python3 -c "import distutils.sysconfig; print(distutils.sysconfig.get_python_inc())"# python3 -c "import numpy ; print(numpy.get_include())"#PYTHONCFLAGS=-I/usr/include/python2.7/ -I/usr/lib64/python2.7/site-packages/numpy/core/include/############################################################################ Cuda GPU flags############################################################################ root of the cuda 8 installationCUDAROOT=/usr/local/cuda-8.0/ #使用cuda-8.0CUDACFLAGS=-I$(CUDAROOT)/includeNVCC=$(CUDAROOT)/bin/nvccNVCCFLAGS= $(CUDAFLAGS) \-I $(CUDAROOT)/targets/x86_64-linux/include/ \-Xcompiler -fPIC \-Xcudafe --diag_suppress=unrecognized_attribute \-gencode arch=compute_35,code="compute_35" \ #可以删除此行,因为我们的显卡很强-gencode arch=compute_52,code="compute_52" \-gencode arch=compute_60,code="compute_60" \--std c++11 -lineinfo \-ccbin $(CXX) -DFAISS_USE_FLOAT16# GeForce GTX TITAN X 5.2是公司显卡的型号# 在Makefile里写$(NVCC) $(NVCCFLAGS) -o $@ $< $(NVCCLDFLAGS) -I../../../# 等价于 $($(CUDAROOT)/bin/nvcc) $($(CUDAFLAGS) \# -I $(CUDAROOT)/targets/x86_64-linux/include/ \# -Xcompiler -fPIC \# -Xcudafe --diag_suppress=unrecognized_attribute \# -gencode arch=compute_35,code="compute_35" \# -gencode arch=compute_52,code="compute_52" \# -gencode arch=compute_60,code="compute_60" \# --std c++11 -lineinfo \# -ccbin $(CXX) -DFAISS_USE_FLOAT16) -o $@ $< $(NVCCLDFLAGS) -I../../../# NVCCLDFLAGS这个参数是存在于Makefile文件中的# NVCCLDFLAGS= -Xcompiler \"-Wl,-rpath=../../:../../gpu/\" \# -L../.. -L../../gpu -lfaiss -lgpufaiss# BLAS LD flags for nvcc (used to generate an executable)# if BLASLDFLAGS contains several flags, each one may# need to be prepended with -XlinkerBLASLDFLAGSNVCC=-Xlinker $(BLASLDFLAGS)# Same, but to generate a .soBLASLDFLAGSSONVCC=-Xlinker $(BLASLDFLAGS)
结论:
显卡型号:
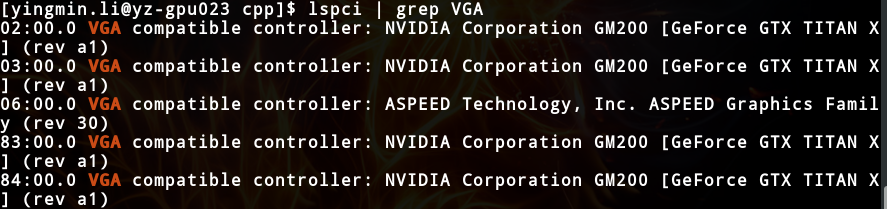
查阅官网得:
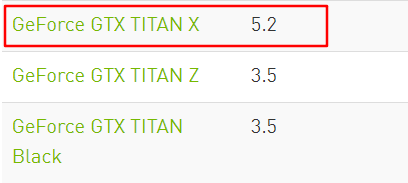
1.改成 -gencode arch=compute_52,code="compute_52"之后,计算能力进一步提升!!!!
2.GPU的完整编译指令是这样的:
/usr/local/cuda-8.0//bin/nvcc -I /usr/local/cuda-8.0//targets/x86_64-linux/include/ -Xcompiler -fPIC -Xcudafe --diag_suppress=unrecognized_attribute -gencode arch=compute_52,code="compute_52" -gencode arch=compute_60,code="compute_60" --std c++11 -lineinfo -ccbin g++ -DFAISS_USE_FLOAT16 -o 5-Multiple-GPUs 5-Multiple-GPUs.cpp -Xcompiler \"-Wl,-rpath=../../:../../gpu/\" -L../.. -L../../gpu -lfaiss -lgpufaiss -I../../../

