@xudongh
2017-04-23T07:48:56.000000Z
字数 6131
阅读 2628
从零开始写一个简单的小爬虫
前端开发
这篇文章教大家如何使用node从零开始写一个简单的小爬虫,这是篇简单、通俗的教程,帮助我们对爬虫有基本了解 - -
在阅读这篇文章之前我们需要什么:
- 会一点点javascript语言
- 会一点点node.js以及npm工具的使用
- 用5分钟时间阅读cherrio库的文档
- 一台装有编译器的电脑
一、什么是爬虫
简单来说,爬虫是一种动物 一种自动获取网页内容的程序。
在我们浏览网页的时候,加载完网页后,网页的数据已经被我们从服务器端下载下来了,那爬虫就是抓取网页数据,把我们需要的内容提取出来的过程。比如,我们想下载某个网页中的所有图片,那就可以利用爬虫获取这个页面的所有数据,然后对页面数据中的所有图片抽出来。
以上是一个简单的单页面爬虫的原理。而实际上,爬虫被应用于搜索引擎,所以其实“爬虫”这个名称非常形象生动,它就像一只虫子一样,在网络上爬啊爬,那它想要的数据。
二、如何利用爬虫抓取数据
1、抓取文本数据
下面我们以厚朴网站的一个页面为例子:
厚朴〖HOPE〗工作室 >> 前端开发
现在我想获取这个页面所有文章的标题:
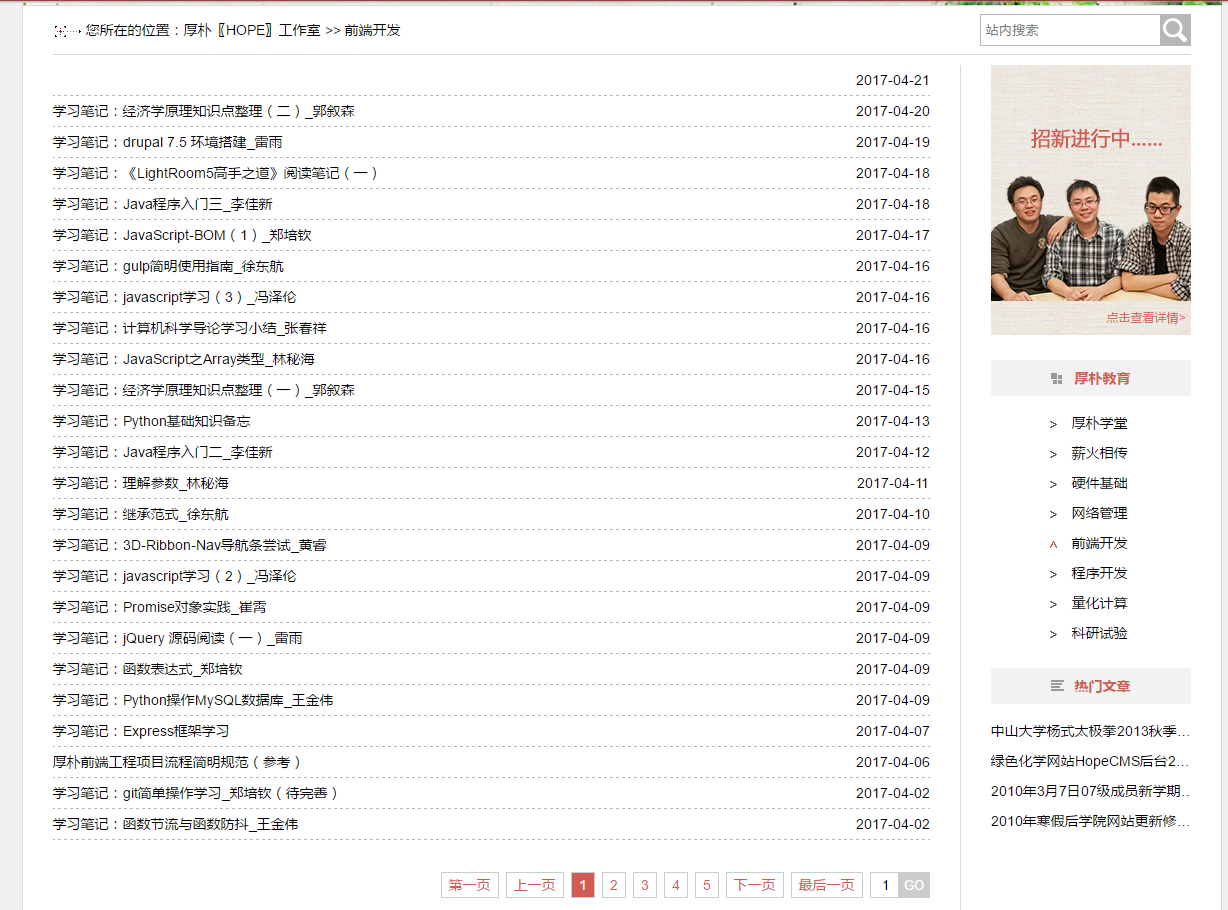
我们得到的数据结果应该是这样的:
学习笔记:HTML基本标签及其用法整理_刘浩翔学习笔记:经济学原理知识点整理(二)_郭叙森学习笔记:drupal 7.5 环境搭建_雷雨学习笔记:《LightRoom5高手之道》阅读笔记(一)学习笔记:Java程序入门三_李佳新学习笔记:JavaScript-BOM(1)_郑培钦学习笔记:gulp简明使用指南_徐东航学习笔记:javascript学习(3)_冯泽伦学习笔记:计算机科学导论学习小结_张春祥学习笔记:JavaScript之Array类型_林秘海学习笔记:经济学原理知识点整理(一)_郭叙森学习笔记:Python基础知识备忘学习笔记:Java程序入门二_李佳新学习笔记:理解参数_林秘海学习笔记:继承范式_徐东航学习笔记:3D-Ribbon-Nav导航条尝试_黄睿学习笔记:javascript学习(2)_冯泽伦学习笔记:Promise对象实践_崔霄学习笔记:jQuery 源码阅读(一)_雷雨学习笔记:函数表达���_郑培钦学习笔记:Python操作MySQL数据库_王金伟学习笔记:Express框架学习厚朴前端工程项目流程简明规范(参考)学习笔记:git简单操作学习_郑培钦(待完善)学习笔记:函数节流与函数防抖_王金伟
在获取文章标题数据之前,我们先要获取到整个页面的数据,因此,新建一个文件crawler.js:
const http = require('http');const url = 'http://ce.sysu.edu.cn/hope/FrontEnd/Index.aspx';http.get(url, function(res) {let html = '';res.on('data', function(data) {html += data;})res.on('end', function() {console.log(html);})})
在上面这段代码中,首先我们引入了http模块,并使用http模块的get方法获取到了这个url的数据。fucntion(res) {...}是一个回调函数,其中res.on()是一个事件监听,用于监听数据是否有变化,而on()方法和addListener是一样的,用于监听事件,没有任何区别。
EventEmitter.prototype.on = EventEmitter.prototype.addListener;
通过node.js执行代码:

整个页面的html代码已经被我们获取到了。
接下来就是对我们所需要的内容进行提取。这时我们需要cheerio这一个库,方便我们操作获取的数据。先安装cheerio:
npm install cheerio --save
引入cheerio模块:
const http = require('http');const cheerio = require('cheerio');const fs = require('fs');const url = 'http://ce.sysu.edu.cn/hope/FrontEnd/Index.aspx';
同时我们也引入了fs模块,为了后面我们需要对数据进行文本i\o操作做准备。
查看页面的源代码发现,文章的标题都被写在一个类名为hope_list_item_content的盒子里面:
<a class="hope_list_item_content" href="..." title="点击查看更多">[我们需要的数据]</a>
定义一个用于对数据进行筛选的函数:
function saveTitles(data) {let $ = cheerio.load(html);let titles = $('.hope_list_item_content'); // 获取这个类名的数据let titlesData= []; //定义一个空数组用于存放数据}
此处用了cheerio的方法(如果不懂的去看cheerio文档,超级简单),这样我们就能够像Jquery一样操作dom结构。
function saveTitles(data) {let $ = cheerio.load(html);let titles = $('.hope_list_item_content');let titlesData= [];titles.each(function(i, elem) {let title = $(this).text();titlesData.push(title);})titlesData = titlesData.join('\r\n'); //将数组转换成字符串,以`\r\n`分隔return titlesData}
此处使用each遍历数据,不要问为什么不是forEach,因为这是cheerio的方法而不是原生js的方法- -
通过遍历的方法,将所有文章title保存在名为titlesData的数组中。
文章标题我们已经通过上面的函数获得了,console.log出来看下:
const http = require('http');const cheerio = require('cheerio');const fs = require('fs');const url = 'http://ce.sysu.edu.cn/hope/FrontEnd/Index.aspx';function saveTitles(data) {let $ = cheerio.load(data);let titles = $('.hope_list_item_content');let titlesData= [];titles.each(function(i, elem) {let title = $(this).text();titlesData.push(title);})titlesData = titlesData.join('\r\n');return titlesData}http.get(url, function(res) {let html = '';res.on('data', function(data) {html += data;})res.on('end', function() {let output = saveTitles(html);console.log(output);})})
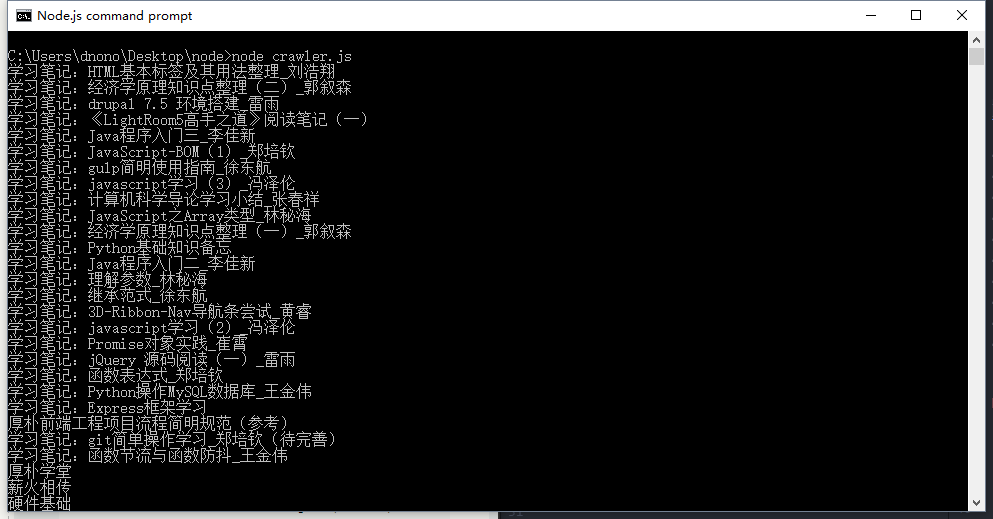
此时我们已经得到我们需要的数据。通过前面引入的fs模块,将数据写入到文件:
res.on('end', function() {let output = saveTitles(html);// console.log(output);//将数据写入到文件fs.writeFile(output.txt, output, function() {console.log('数据写入成功')})})
执行下代码,可以在根目录找到output.txt文件,里面就有我们想要的数据。
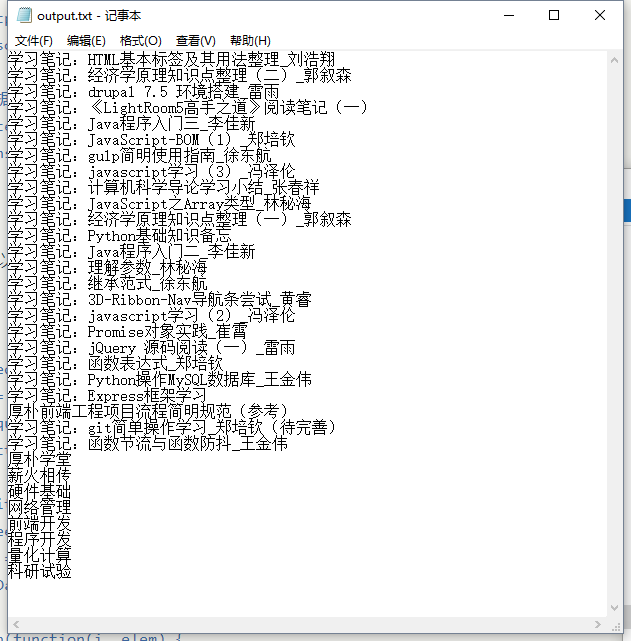
完整的代码:
const http = require('http');const cheerio = require('cheerio');const fs = require('fs');const url = 'http://ce.sysu.edu.cn/hope/FrontEnd/Index.aspx';function saveTitles(data) {let $ = cheerio.load(data);let titles = $('.hope_list_item_content');let titlesData= [];titles.each(function(i, elem) {let title = $(this).text();titlesData.push(title);})titlesData = titlesData.join('\r\n');return titlesData}http.get(url, function(res) {let html = '';res.on('data', function(data) {html += data;})res.on('end', function() {let output = saveTitles(html);// console.log(output);fs.writeFile('output.txt', output, function() {console.log('数据写入成功')})})})
2、抓取图片数据
抓取图片数据和抓取文本数据的方法大同小异,其主要区别是,在保存图片数据的时候,我们是通过二进制形式进制保存的。
我们发现这个网站Raumrot上的图片很好看,想把它们都下载下来,但由于图片比较多,手动一张张保存下来太麻烦,因此我们可以通过爬虫将图片都爬下来。
首先。创建crawlerImg.js文件:
const http = require('http');const fs = require('fs');const cheerio = require('cheerio');const url = 'http://raumrot.com/photo-set-landing/';http.get(url, function(res) {let html = '';res.on('data', function(data) {return html += data;})res.on('end', function(){console.log(html);})}).on('error', function(err) {console.log('出错: ' + err);})
同样,先获取整个页面的html代码数据,可以通过console.log()看下是否抓取到。
然后,筛选出图片,从html代码中获得图片的src地址,再用http.get()方法将图片下载下来。
通过查看源代码知道,我们需要的图片均在<img> 标签内,所以可以定义一个函数:
function saveImages(data) {let $ = cheerio.load(data),img = $('img'); //获得图片的标签元素console.log('总计有' + img.length + '张图片');}
遍历图片标签,获得图片src地址,通过src地址下载图片,并将其保存下来:
function saveImages(data) {let $ = cheerio.load(data),img = $('img');console.log('总计有' + img.length + '张图片');img.each(function(i, elem) {let imgSrc = $(this).attr('src');http.get(imgSrc, function(res) {let imageData = ''; //定义变量用于保存图片数据res.setEncoding('binary'); //将图片转换为二进制,以便保存res.on('data', function(data) {imageData += data;})res.on('end', function() {//定义图片名称,获取原图片后缀let imgPath = 'img-' + (i+1) + '.' + imgSrc.split('.').pop();//将图片的二进制数据写入文件,通过回调函数打印成功指示fs.writeFile(__dirname + '/imgs/' + imgPath, imageData, 'binary', function() {console.log('成功下载第' + (i+1) + '张图片');})})})})}
这里与获取文本数据不一样的是,将一张图片数据转换为二进制数据进行保存,然后马上输出,接着对下一张图片采取相同操作,一张一张进行。
完整的代码为:
const http = require('http');const fs = require('fs');const cheerio = require('cheerio');const url = 'http://raumrot.com/photo-set-landing/';function saveImages(data) {let $ = cheerio.load(data),img = $('img');console.log('总计有' + img.length + '张图片');img.each(function(i, elem) {let imgSrc = $(this).attr('src');http.get(imgSrc, function(res) {let imageData = '';res.setEncoding('binary');res.on('data', function(data) {imageData += data;})res.on('end', function() {let imgPath = 'img-' + (i+1) + '.' + imgSrc.split('.').pop();fs.writeFile(__dirname + '/images/' + imgPath, imageData, 'binary', function() {console.log('成功下载第' + (i+1) + '张图片');})})})})}http.get(url, function(res) {let html = '';res.on('data', function(data) {return html += data;})res.on('end', function() {saveImages(html);})}).on('error', function(err) {console.log('出错: ' + err);})
在node.js上运行,经过几秒后,我们就可以在images文件夹中得到图片:
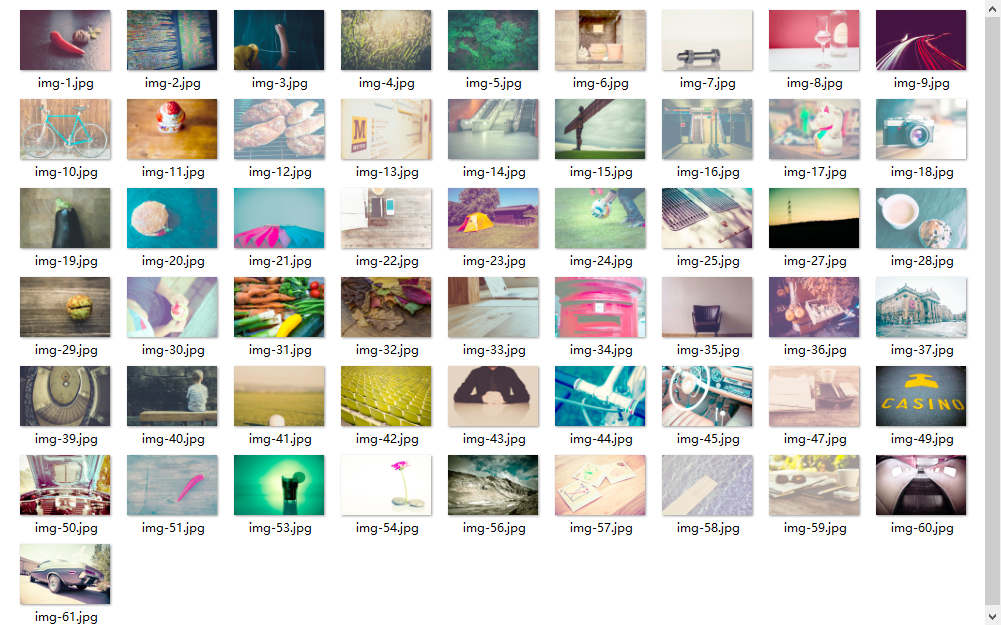
三、总结
上面提到的小爬虫,仅仅对于单页面的数据进行获取分析,仅仅用于学习使用,而爬虫实则更多应用于做数据分析,且不是针对单页面,更是整个网站或更大的范围。事实上,很多编程语言都能够实现爬虫。简单归简单,在对爬虫有基本的了解之时,明白了爬虫的工作原理。
