@xudongh
2016-10-16T04:38:59.000000Z
字数 1140
阅读 1759
参数传递机制
计算机
不匹配的浮点型转换程序演示:
#include <stido.h>int main(void){float n1 = 3.0;double n2 = 3.0;long n3 = 2000000000;long n4 = 1234567890;printf("%.1e %.1e %.1e %.1e\n", n1, n2, n3, n4);printf("%ld %ld\n",n3, n4);printf("%ld %ld %ld %ld\n", n1, n2, n3, n4);return 0;
经过xcode测试发现程序中的错误被编译器捕获,直接就不给你输出结果。(编译器真强大...)
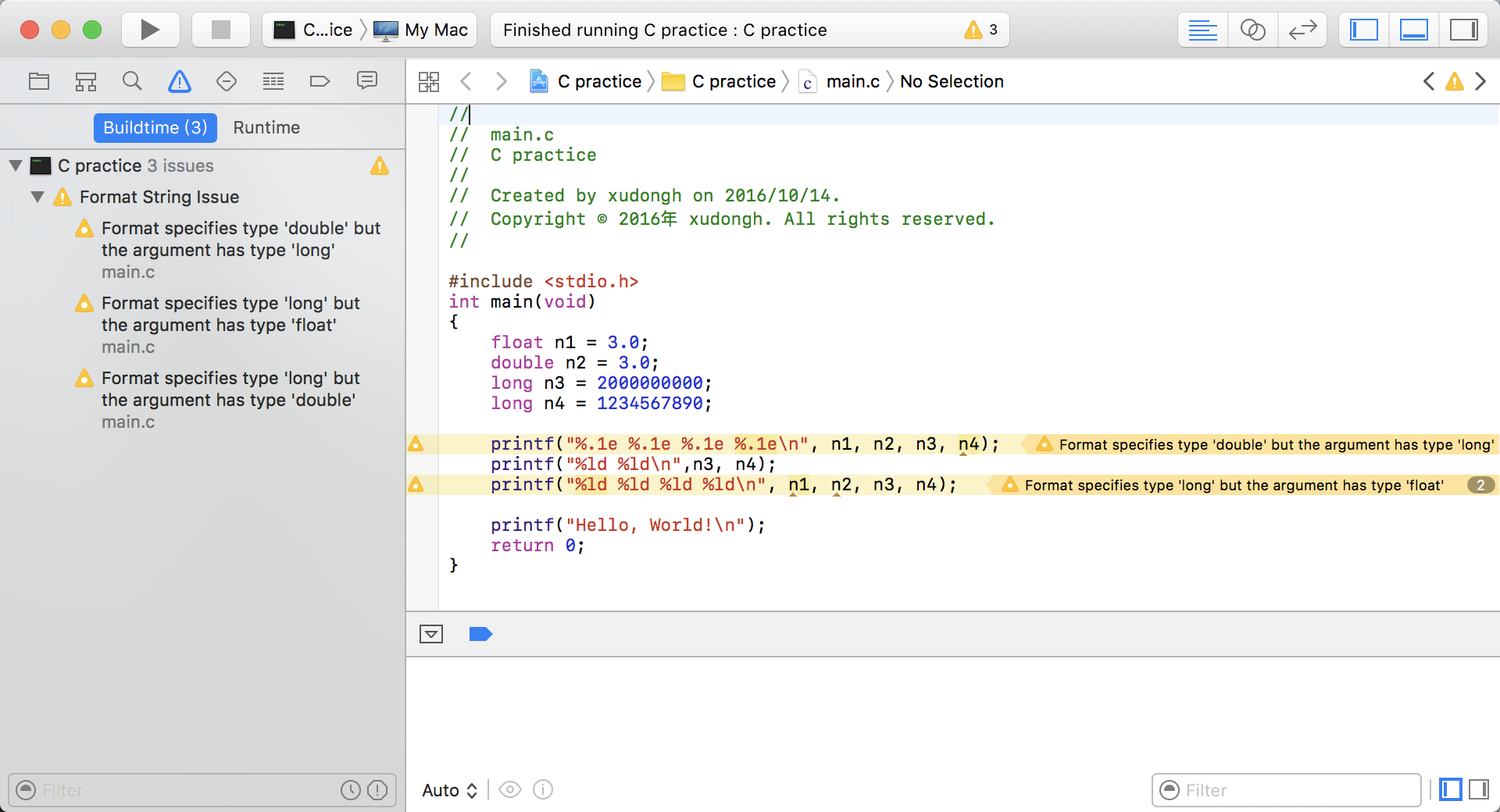
但有些编译器,仍能输出结果:
3.0+00 3.0e+00 3.1e+46 1.7e+2662000000000 12345678900 1074266112 0 1074266112
对于第1行,n3和n4的值并不正确。首先,%e转换说明让printf()函数认为待打印的值是double类型(本系统double为8字节)。当printf()查看n3(本系统long为4字节)时,除了查看n3的4字节外,还会查看n3相邻的4字节,共8字节单元。然后,它将8字节单元中的位组合解释为浮点数。因此,即使n3的位数正确,根据%e的转换说明和%ld转换说明解释出来的值也不同。最终得到的结果是无意义的值。
对于第3行,用%ld转换说明打印浮点数会失败,但是在这里,用%ld打印long类型的书也失败了!问题出在C如何把信息传递给函数。
参数传递机制因编译器实现而异。以某系统为例,分析参数传递的原理。函数调用如下:
printf("%ld %ld %ld %ld\n", n1, n2, n3, n4);
该调用告诉计算机把变量n1、n2、n3和n4的值传递给程序。这是一种常见的参数传递方式。程序把传入的值放在被称为栈(stack)的内存区域。计算机根据变量类型(而不是根据转换说明)把这些值放在栈中。因此,n1被储存在栈中,占8字节(float类型被转换成double类型)。同样,n2也在栈中占8字节,而n3和n4在栈中分别占4字节。然后,控制转到printf()函数。该函数根据转换说明(不是根据变量类型)从栈中读取值。
%ld转换说明表明printf()应该读取4字节,所以printf()读取栈中的前4字节作为第1个值。这是n1的前半部分,将被解释成一个long类型的整数。根据下一个%ld转换说明,printf()再读取4字节,这是n1的后半部分,将被解释成第2个long类型的整数。类似地,根据第3个和第4个%ld,printf()读取n2的前半部分和后半部分,并解释成两个long类型的整数。因此,对于n3和n4,虽然用对了转换说明,但prinf()还是读错了字节。
