@sasaki
2016-04-21T08:49:22.000000Z
字数 18459
阅读 5770
构建Flume、Kafka日志收集与分析系统
BigData
版本控制
@Title 构建Flume、Kafka日志收集与分析系统@Version v1.0@Timestamp 2016-02-18 16:20@Author Nicholas@Mail redskirt@outlook.com
Flume和Kafka整合
- 下载flume-kafka-plus: https://github.com/beyondj2ee/flumeng-kafka-plugin
- 提取插件中的flume-conf.properties文件,将改后的配置文件放进flume-ng/conf目录下
启动Flume,对监控的目录进行日志收集并导入Kafka
[root@master conf]# flume-ng agent -n producer -c conf -f /etc/flume-ng/conf/flume-kafka.properties -Dflume.root.logger=INFO,console
自定义Kafka Consumer将消息导入HDFS
运行HadoopConsumer jar,参数分别为 zookeeper,groupId,topicId,注意groupId,topicId要与flume-kafka.properties配置文件中producer.sinks.sink1.custom.topic.name一致。
[root@master ~]# java -cp /usr/application/tmp/search-query-mq-0.0.1-SNAPSHOT.jar org.redskirt.sq.mq.comsumer.HadoopConsumer 192.168.53.230:2181 topic1 topic1[root@master tmp]# hadoop fs -tail /user/root/search-query/date=2016-03-25/data
建立带Partition的Hive表
hive通过partitions将表粗粒度划分为不同的目录来提高查询的效率,例如包含时间戳的日志文件,如果我们按照时间来把日志文件分在不同的目录下,那么相同日期的记录就会存储在同一个分区目录下面,就可以更高效率地查询特定某个时间的记录。
CREATE EXTERNAL TABLE data(time varchar(8), userid varchar(30), query string, pagerank int, clickrank int, site string)PARTITIONED BY (date string)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
通过partitioned by声明的字段表面上和在普通的column表面没什么不同,不同之处在于,表并不存储通过partitioned by声明的字段,而是将不同字段的数据放在partitioned字段目录下面,通过路径来获得partitioned字段的值。所以在我们想partitioned 表中加载数据时,需要指明partitioned 字段的值。
hive> desc data;OKtime varchar(8)userid varchar(30)query stringpagerank intclickrank intsite stringdate string# Partition Information# col_name data_type commentdate stringTime taken: 0.107 seconds, Fetched: 12 row(s)# 向data表中装载数据LOAD DATA INPATH '/user/root/search-query/date=2016-03-25/data'INTO TABLE dataPARTITION(date='2016-03-25');# 同样,再制作两份数据,模拟产生两个日期的Partition数据,装入Hive表中LOAD DATA INPATH '/user/root/search-query/date=2016-03-26/data'INTO TABLE dataPARTITION(date='2016-03-26');LOAD DATA INPATH '/user/root/search-query/date=2016-03-27/data'INTO TABLE dataPARTITION(date='2016-03-27');
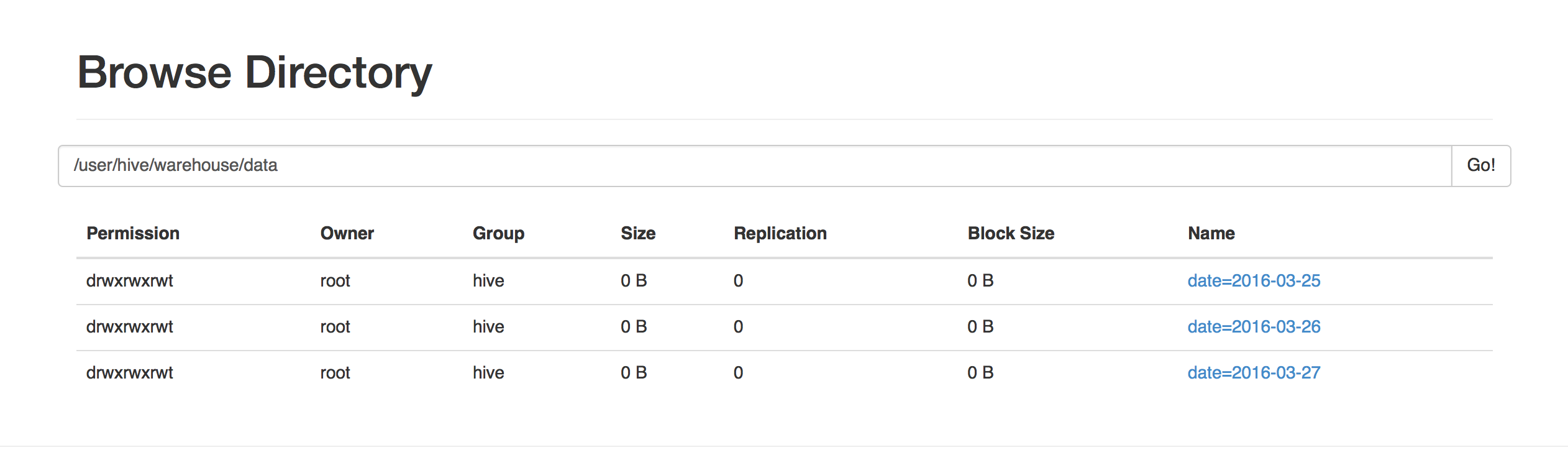
模拟产生三天的日志记录,分别在三个Partitions,效果如下
查看一个table的partitioned 情况
hive> show partitions data;OKdate=2016-03-25date=2016-03-26date=2016-03-27Time taken: 0.085 seconds, Fetched: 3 row(s)
外部表,删除表操作后数据还存在。
hive> drop table if exists data;OKTime taken: 0.217 seconds[root@master data]# hadoop fs -tail /user/hive/warehouse/data/date=2016-03-25/dataspbbs.asp?boardid=22&id=452584&page=&star=323:59:59 6722332983806055 [全国公安通缉犯名单] 1 4 www.dream88.cn/dispost.asp?BoardID=14&PostID=33123:59:59 6391786550589877 [福利彩票] 8 1 www.zhcw.com/23:59:59 06550975741118936 [堰塞湖的形成] 2 5 news.sina.com.cn/c/2008-05-28/045015632057.shtml23:59:59 045933662148281984 [徐娜是谁] 3 2
Hive DDL语句
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name(col_name data_type, ...)[PARTITIONED BY (col_name data_type, ...)][CLUSTERED BY (col_name, col_name, ...) [SORTED BY(col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS][SKEWED BY (col_name, col_name, ...)][ [ROW FORMAT row_format] [STORED AS file_format] ][LOCATION hdfs_path]
Sqoop将Hive数据导出MySql
# 列出MySql中所有数据库[root@master data]# sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username root --password rootWarning: /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/bin/../lib/sqoop/../accumulo does not exist! Accumulo imports will fail.Please set $ACCUMULO_HOME to the root of your Accumulo installation.16/03/25 23:46:47 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5-cdh5.3.816/03/25 23:46:47 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.16/03/25 23:46:48 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.information_schemacmcm_hivemysqlsearch_querytest# MySql中建立表结构DROP TABLE IF EXISTS `date_2016_03_25`;CREATE TABLE `date_2016_03_25` (`id` int(11) NOT NULL AUTO_INCREMENT,`time` time DEFAULT NULL,`userid` varchar(30) COLLATE utf8_bin DEFAULT NULL,`query` varchar(50) COLLATE utf8_bin DEFAULT NULL,`pagerank` int(2) DEFAULT NULL,`clickrank` int(2) DEFAULT NULL,`site` varchar(100) COLLATE utf8_bin DEFAULT NULL,`date` date DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_bin;SET FOREIGN_KEY_CHECKS = 1;# 将Hive中的表数据导出到MySql中[root@master data]# sqoop export --connect jdbc:mysql://master:3306/search_query --username root --password root --table date_2016_03_25 --input-fields-terminated-by '\t' --export-dir /user/hive/warehouse/data/date=2016-03-25/data
处理表数据
select语法
SELECT [ALL | DISTINCT] select_expr, select_expr, ...FROM table_reference[WHERE where_condition][GROUP BY col_list][CLUSTER BY col_list| [DISTRIBUTE BY col_list] [SORT BY col_list]][LIMIT number]
统计日期为2016-03-25的每个关键词的搜索量,并按搜索量降序排列,结果存入表keyword_20160325中
hive> create table keyword_20160325 as select query,count(query) as count from data where data.date='2016-03-25' group by data.query order by count desc;hive> desc keyword_20160325;OKquery stringcount bigintTime taken: 0.082 seconds, Fetched: 2 row(s)hive> select * from keyword_20160325 limit 10;OK[哄抢救灾物资] 133812[汶川地震原因] 117532[封杀莎朗斯通] 25298[一个暗娼的自述] 19516[广州军区司令员] 17322[暗娼李湘] 17168[成都警方扫黄现场] 10742[百度] 9916[尼泊尔地图] 9772[现役解放军中将名单] 9442Time taken: 0.066 seconds, Fetched: 10 row(s)# MySql中查询mysql> desc date_2016_03_25;+-----------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+-----------+-------------+------+-----+---------+-------+| time | varchar(30) | YES | | NULL | || userid | varchar(30) | YES | | NULL | || query | text | YES | | NULL | || pagerank | int(2) | YES | | NULL | || clickrank | int(2) | YES | | NULL | || site | text | YES | | NULL | |+-----------+-------------+------+-----+---------+-------+6 rows in set (0.00 sec)mysql> select query, count(query) as count from date_2016_03_25 group by query order by count desc limit 10;+-------------------------------+--------+| query | count |+-------------------------------+--------+| [哄抢救灾物资] | 133453 || [汶川地震原因] | 122856 || [封杀莎朗斯通] | 27381 || [一个暗娼的自述] | 16460 || [暗娼李湘] | 15675 || [广州军区司令员] | 13092 || [尼泊尔地图] | 11516 || [百度] | 10181 || [吕秀莲到大陆] | 9795 || [杨丞琳辱华惨痛下场] | 9598 |+-------------------------------+--------+10 rows in set (34.40 sec)
统计每秒访问量TPS,按访问量降序排列,并把结果输出到表time_20150325中
hive> select time, count(time) as count from data where data.date='2016-03-25' group by time order by count desc limit 10;...OK15:38:11 11621:32:17 11216:32:51 11217:35:17 11215:34:37 11016:35:53 11021:09:29 11017:41:19 10816:15:39 10815:16:05 106Time taken: 59.953 seconds, Fetched: 10 row(s)hive> create table time_20160325 as select time, count(time) as count from data where data.date='2016-03-25' group by time order by count desc;
创建一个表用于存放今天与昨天的关键词搜索量和增量及其增量比率,表数据位于 '/user/hive/warehouse/log_analysis/keyword_20160325_20160326'
hive> create external table if not exists keyword_20160325_20160326(keyword string, count int, increment int, incrementrate double) location '/user/hive/warehouse/log_analysis/keyword_20160325_20160326';OKTime taken: 0.083 seconds
关联两天关键词统计结果表keyword_20160325与keyword_20160326,统计今天与昨天同时出现的关键词的搜索次数,今天相对昨天的增量和增量比率,并按增量比率降序排列,结果输出到keyword_20160325_20160326表中
# 先建立keyword_20160326表并填充数据hive> create table keyword_20160326 as select query,count(query) as count from data where data.date='2016-03-26' group by data.query order by count desc;insert overwrite table keyword_20160325_20160326 select cur.query,cur.count,cur.count - yes.count as increment,(cur.count - yes.count)/yes.count as incrementrate from keyword_20160325 cur join keyword_20160326 as yes on (cur.query = yes.query) order by incrementrate desc;hive> select cur.query,cur.count,cur.count - yes.count as increment,(cur.count - yes.count)/yes.count as incrementrate from keyword_20160326 cur join keyword_20160325 as yes on (cur.query = yes.query) order by incrementrate desc limit 5;...Total MapReduce CPU Time Spent: 12 seconds 610 msecOK[哄抢救灾物资] 66906 -66906 -0.5[汶川地震原因] 58766 -58766 -0.5[封杀莎朗斯通] 12649 -12649 -0.5[一个暗娼的自述] 9758 -9758 -0.5[广州军区司令员] 8661 -8661 -0.5Time taken: 37.813 seconds, Fetched: 5 row(s)
统计
date='2016-03-25'网站的PV(Page View)量,即所有用户浏览页面的总和,一个独立用户每打开一个页面就被记录1 次hive> select count(1) as pv from data where date='2016-03-25';...OK3448528Time taken: 28.189 seconds, Fetched: 1 row(s)
查看前10的搜索结果URL访问
hive> select site as request,count(site) as numrequest from data where date='2016-03-25' group by site order by numrequest desc limit 10;...OKnews.21cn.com/social/daqian/2008/05/29/4777194_1.shtml 61724news.21cn.com/zhuanti/domestic/08dizhen/2008/05/19/4733406.shtml 38506pic.news.mop.com/gs/2008/0528/12985.shtml 33100www.tudou.com/programs/view/2F3E6SGHFLA/ 29150bjyouth.ynet.com/view.jsp?oid=40472396 24904www.17tech.com/news/20080531107270.shtml 22760www.baidu.com/ 12086www.taihainet.com/news/military/jslwt/2007-06-27/141544.shtml 8622www.17tech.com/news/20080531107274.shtml 7628news.vnet.cn/photo/292_6.html 7574Time taken: 84.934 seconds, Fetched: 10 row(s)
获取搜索量topN的用户其搜索词的具体统计情况
hive> select userid,count(userid) as numuser from data where date='2016-03-25' group by userid order by numuser desc;
导出数据到MySQL,当然数据库表要先存在,否则会报错,此错误的原因为sqoop解析文件的字段与MySql数据库的表的字段对应不上造成的。因此需要在执行的时候给sqoop增加参数,告诉sqoop文件的分隔符,使它能够正确的解析文件字段。hive默认的字段分隔符为'\001',sqoop的默认分隔符是 ','。
Error: java.io.IOException: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failureThe last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.at org.apache.sqoop.mapreduce.ExportOutputFormat.getRecordWriter(ExportOutputFormat.java:79)at org.apache.hadoop.mapred.MapTask$NewDirectOutputCollector.<init>(MapTask.java:644)at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1642)at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:163)Caused by: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failureThe last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.# 解决:将localhost改为IP或主机名master# 又遇到以下问题Error: java.io.IOException: Can't export data, please check failed map task logsat org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:112)at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39)at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64)at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:784)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1642)at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:163)Caused by: java.lang.RuntimeException: Can't parse input data: '20:57:15 6401633234309676 [比亚迪f1] 2 jsp.auto.sohu.com/view/subbrand-sbid-279443.html'at date_2016_03_25.__loadFromFields(date_2016_03_25.java:507)at date_2016_03_25.parse(date_2016_03_25.java:420)at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:83)... 10 moreCaused by: java.lang.NumberFormatException: For input string: "20:57:15 6401633234309676 [比亚迪f1] 2 3 jsp.auto.sohu.com/view/subbrand-sbid-279443.html"at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)at java.lang.Integer.parseInt(Integer.java:492)at java.lang.Integer.valueOf(Integer.java:582)at date_2016_03_25.__loadFromFields(date_2016_03_25.java:469)... 12 more# 遇到如下很问题Error: java.io.IOException: Can't export data, please check failed map task logsat org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:112)at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39)at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64)at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:784)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1642)at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:163)Caused by: java.lang.RuntimeException: Can't parse input data: 'download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html'at date_2016_03_25.__loadFromFields(date_2016_03_25.java:464)at date_2016_03_25.parse(date_2016_03_25.java:382)at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:83)... 10 moreCaused by: java.util.NoSuchElementExceptionat java.util.ArrayList$Itr.next(ArrayList.java:834)at date_2016_03_25.__loadFromFields(date_2016_03_25.java:459)... 12 more
解决上一问题后继续尝试导出,此时Map任务可以运行,但是中途报错如下,
Error: java.io.IOException: Can't export data, please check failed map task logsat org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:112)at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:39)at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)at org.apache.sqoop.mapreduce.AutoProgressMapper.run(AutoProgressMapper.java:64)at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:784)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1642)at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:163)Caused by: java.lang.RuntimeException: Can't parse input data: '家电维修(中、高级)技能培训项目任务书]'at date_2016_03_25.__loadFromFields(date_2016_03_25.java:421)at date_2016_03_25.parse(date_2016_03_25.java:344)at org.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:83)... 10 moreCaused by: java.lang.NumberFormatException: For input string: "家电维修(中、高级)技能培训项目任务书]"at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)at java.lang.Integer.parseInt(Integer.java:492)at java.lang.Integer.valueOf(Integer.java:582)at date_2016_03_25.__loadFromFields(date_2016_03_25.java:408)... 12 more
查看原数据匹配家电维修(中、高级)技能培训项目任务书]的部分如下
[root@master ~]# hadoop fs -text /user/hive/warehouse/data/date=2016-03-25/data |grep 家电维修(中、高级)技能培训项目任务书]21:59:14 8160510088862797 [1、 家电维修(中、高级)技能培训项目任务书] 4 1 www.tech.net.cn/tab/tab200404023.doc22:03:48 8160510088862797 [1、 家电维修(中、高级)技能培训项目任务书] 8 2 www.sict.edu.cn/deng/file/1\xa8\xb2?\xa8\xb0\xa8\xba?\xa1\xa4?D??oD\xa1\xea?\xa1\xa7\xa8\xa6\xa8\xa8???t/1\xa8\xb2?\xa8\xb0\xa8\xba?\xa1\xa4?D???\xa6\xcc\xa8\xa8?\xa1\xe3\xa8\xb0\xa6\xcc?oD\xa1\xea?\xa1\xa7\xa8\xa6\xa8\xa8\xa8\xa8???\xa8\xba\xa8\xa6.doc
可知道原来这里的[1、 家电维修(中、高级)技能培训项目任务书]部分中间多了一个Tab格,导致数据被Tab分隔时影响到读取。
解决:该问题不会影响Map任务的继续运行,为了省时间也可忽略异常继续导出任务。另外,只能将源数据GET至本地将其中有不规范Tab的行删除或替换成' '(空格)后重新导入HDFS。
导出成功后在MySql中查看数据发现中文乱码问题
mysql> select * from date_2016_03_25 limit 10;+----------+-------------------+-------------+----------+-----------+----------------------------------------------------+| time | userid | query | pagerank | clickrank | site |+----------+-------------------+-------------+----------+-----------+----------------------------------------------------+| 18:04:18 | 5853765130623645 | [?????] | 2 | 3 | pics.skyhits.com/HtmlPage/2005-06-10/XZ_4332_1.htm || 18:04:18 | 17840627555496796 | [???????] | 3 | 10 | www.xflove.com/MusicPlay/10/b797670a2ddd3378.html || 18:04:18 | 38336111772650055 | [?????] | 6 | 8 | ks.cn.yahoo.com/question/1306060803181.html || 18:04:18 | 677837215166377 | [????????] | 1 | 1 | zhidao.baidu.com/question/46344034 || 18:04:19 | 07869829328567912 | [??????] | 3 | 3 | www.17tech.com/news/20080531107270.shtml || 18:04:19 | 7764140658031031 | [?????????] | 2 | 2 | www.xici.net/b321606/d37714654.htm || 18:04:19 | 11911560432779528 | [????] | 1 | 3 | mogi.moliyo.com/ || 18:04:19 | 7462123601217611 | [????] | 1 | 1 | oneone258.blog.sohu.com/66590341.html || 18:04:19 | 3425538072999014 | [?????] | 2 | 2 | you.video.sina.com.cn/b/7065867-1198766455.html || 18:04:19 | 2949443329241388 | [?????] | 5 | 12 | iask.sina.com.cn/b/9406403.html |+----------+-------------------+-------------+----------+-----------+----------------------------------------------------+10 rows in set (0.00 sec)
解决:
更改my.cnf文件,添加以下内容
[root@master ~]# vim /etc/my.cnf[mysql]default-character-set=utf8[client]default-character-set=utf8[mysqld]default-character-set=utf8character_set_server=utf8[root@Hadoop48 ~]# service mysqld restart# 查看字符集设置情况mysql> \s--------------mysql Ver 14.14 Distrib 5.1.73, for redhat-linux-gnu (x86_64) using readline 5.1Connection id: 16Current database:Current user: root@localhostSSL: Not in useCurrent pager: stdoutUsing outfile: ''Using delimiter: ;Server version: 5.1.73 Source distributionProtocol version: 10Connection: Localhost via UNIX socketServer characterset: utf8Db characterset: utf8Client characterset: utf8Conn. characterset: utf8UNIX socket: /var/lib/mysql/mysql.sockUptime: 13 secThreads: 15 Questions: 253 Slow queries: 0 Opens: 24 Flush tables: 1 Open tables: 17 Queries per second avg: 19.461--------------mysql> show variables like "char%";+--------------------------+----------------------------+| Variable_name | Value |+--------------------------+----------------------------+| character_set_client | utf8 || character_set_connection | utf8 || character_set_database | utf8 || character_set_filesystem | binary || character_set_results | utf8 || character_set_server | utf8 || character_set_system | utf8 || character_sets_dir | /usr/share/mysql/charsets/ |+--------------------------+----------------------------+8 rows in set (0.00 sec)
再次查询表数据,中文正常。
mysql> select * from date_2016_03_25 limit 3;+----------+-------------------+----------------------+----------+-----------+--------------------------------------------------------------------------------+| time | userid | query | pagerank | clickrank | site |+----------+-------------------+----------------------+----------+-----------+--------------------------------------------------------------------------------+| 00:00:00 | 2982199073774412 | [360安全卫士] | 8 | 3 | download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html || 00:00:00 | 07594220010824798 | [哄抢救灾物资] | 1 | 1 | news.21cn.com/social/daqian/2008/05/29/4777194_1.shtml || 00:00:00 | 5228056822071097 | [75810部队] | 14 | 5 | www.greatoo.com/greatoo_cn/list.asp?link_id=276&title=%BE%DE%C2%D6%D0%C2%CE%C5 |+----------+-------------------+----------------------+----------+-----------+--------------------------------------------------------------------------------+3 rows in set (0.00 sec)
Hive Partition与Bucket
Partition:
- 为减少不必要的暴力数据扫描,可以对表进行分区
- 为避免产生过多小文件,建议只对离散字段进行分区
Bucket:
- 对于值较多的字段,可将其分成若干个Bucket
- 可结合Partition与Bucket使用
hive> create external table log_in(time varchar(8), userid varchar(30), query string, pagerank int, clickrank int, site string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location 'hdfs://192.168.53.230:8020/user/root/hive/external';
过程参考链接
Kafka学习干货:http://www.cnblogs.com/cxzdy/p/4980350.html
Kafka实战-Flume到Kafka http://www.open-open.com/lib/view/open1435884136903.html
高可用Hadoop平台-Flume NG实战图解篇 http://www.cnblogs.com/smartloli/p/4468708.html
http://www.cnblogs.com/xfly/p/3825804.html
http://blog.csdn.net/xiao_jun_0820/article/details/41576999
解决Kafka Producer消息的字符类型转换问题
http://blog.csdn.net/u014373825/article/details/42711191
