@sasaki
2016-04-22T03:26:54.000000Z
字数 11412
阅读 9952
Sqoop——数据传输工具
BigData
版本控制
@Title Sqoop——数据传输工具@Version v1.0@Timestamp 2016-01-20 18:08@Author Nicholas@Mail redskirt@outlook.com
一、Sqoop简介与部署
Sqoop是一款开源的工具,主要用于在HADOOP不传统的数据库(mysql、postgresql等)进行数据的传递,可以将一个关系型数据库(例如:MySQL、Oracle、Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop1架构
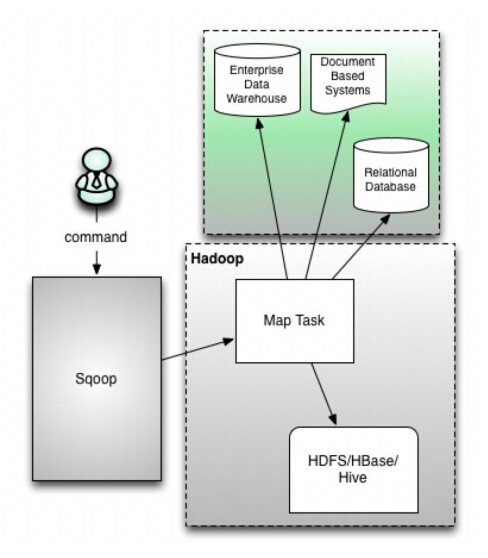
- 版本号为1.4.x为sqoop1
- 在架构上:sqoop1使用sqoop客户端直接提交的方式
- 访问方式:CLI控制台方式进行访问
- 安全性:命令或脚本中指定用户数据库名及密码
Sqoop2架构

- 版本号为1.99x为sqoop2
- 在架构上:sqoop2引入了sqoop server,对connector实现了集
中的管理 - 访问方式:REST API、 JAVA API、 WEB UI以及CLI控制台方式进
行访问 - CLI方式访问,会通过交互过程界面,输入的密码信息丌被看到,
同时Sqoop2引入基亍角色的安全机制
Sqoop2比Sqoop多了一个Server端。
Sqoop1与Sqoop2对比

Sqoop官方测试过数据库版本
- Sqoop主要通过JDBC和关系数据库进行交互。理论上支持JDBC的database都可以使用sqoop和hdfs进行数据交互。
- Sqoop官方测试通过列表
- Database version URL
- HSQLDB 1.8.0+ jdbc:hsqldb:*//
- MySQL 5.0+ jdbc:mysql://
- Oracle 10.2.0+ jdbc:oracle:*//
- PostgreSQL 8.3+ jdbc:postgresql://
安装Sqoop
由于我的Hadoop集群是CDH版本,在服务中添加Sqoop服务即可。
Sqoop验证安装
[root@master bin]# sqoop helpWarning: /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/bin/../lib/sqoop/../accumulo does not exist! Accumulo imports will fail.Please set $ACCUMULO_HOME to the root of your Accumulo installation.16/01/20 18:31:21 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5-cdh5.3.8usage: sqoop COMMAND [ARGS]Available commands:codegen Generate code to interact with database recordscreate-hive-table Import a table definition into Hiveeval Evaluate a SQL statement and display the resultsexport Export an HDFS directory to a database tablehelp List available commandsimport Import a table from a database to HDFSimport-all-tables Import tables from a database to HDFSimport-mainframe Import datasets from a mainframe server to HDFSjob Work with saved jobslist-databases List available databases on a serverlist-tables List available tables in a databasemerge Merge results of incremental importsmetastore Run a standalone Sqoop metastoreversion Display version informationSee 'sqoop help COMMAND' for information on a specific command.
二、测试Sqoop导入/导出MySQL
准备环境
- mysql-connector-java
将mysql-connector-java-5.1.34-bin.jar放入sqoop/lib/下面(低于此版本mysql连接器可能会有异常) - mysql数据库允许远程连接
Linux下执行mysql命令登录测试是否mysql允许远程访问:
mysql –h mysql-server-ip –u username –p database,
如果没有权限,在mysql命令行中执行:
grant all PRIVILEGES on *.* to root@’hostname’ identified by ‘password’; flush privileges; - 测试sqoop是否可以连接到mysql
Sqoop测试命令,显示当前可用的数据库:
sqoop list-databases --connect jdbc:mysql://mysql-server-ip:3306/ --username root --password <password>
# 将mysql-*.jar放入sqoop目录中[root@master tmp]# cp mysql-connector-java-5.1.35.jar /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/sqoop[root@master tmp]# cp mysql-connector-java-5.1.35.jar /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/sqoop2# 用sqoop查看数据库[root@master tmp]# sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username root --password rootWarning: /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/bin/../lib/sqoop/../accumulo does not exist! Accumulo imports will fail.Please set $ACCUMULO_HOME to the root of your Accumulo installation.16/01/20 20:47:19 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5-cdh5.3.816/01/20 20:47:19 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.16/01/20 20:47:20 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.information_schemacmhivemysqlnavigator_audit_servernavigator_metadata_serverreports_managertest# 用于测试的数据库表结构及数据内容mysql> use testReading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedmysql> describe user_info;+--------+--------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+--------+--------------+------+-----+---------+----------------+| id | int(11) | NO | PRI | NULL | auto_increment || name | varchar(100) | YES | | NULL | || gender | varchar(10) | YES | | NULL | || grade | int(20) | YES | | NULL | |+--------+--------------+------+-----+---------+----------------+4 rows in set (0.00 sec)mysql> select * from user_info;+----+----------+--------+-------+| id | name | gender | grade |+----+----------+--------+-------+| 1 | redskirt | m | 100 || 2 | honey | m | 90 || 3 | lw | m | 92 || 4 | nicholas | m | 99 || 5 | sasaki | m | 99 |+----+----------+--------+-------+5 rows in set (0.00 sec)
- mysql-connector-java
mysql数据导入HDFS
- 全表导入(单map串行导入)
sqoop import --connect jdbc:mysql://mysql-serverip:3306/sqoop --username root --password root --table user_info -m 1
参数解析:
--connect:JDBC连接URL
--username:连接数据库用户名
--password:连接数据库密码
--table:要读取的表
-m:map并行读取的数量
含义:读取user_info表数据到HDFS集群,并叧通过一个map任务
注意:此Sqoop命令没有指定HDFS目录,默认数据会放在/user/{user.name}/{--table参数指定表名}目录下。[root@master tmp]# sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password root --table user_info -m 1mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%';Query OK, 0 rows affected (0.06 sec)mysql> flush privileges;Query OK, 0 rows affected (0.02 sec)
在YARN上可看到完成的MapReduce任务

# HDFS中查看结果[root@master tmp]# hadoop fs -cat /user/root/user_info/part-m-000001,redskirt,m,1002,honey,m,903,lw,m,924,nicholas,m,995,sasaki,m,99
- Select语句导入
sqoop import --connect jdbc:mysql://mysql-serverip:3306/test --username root --password root --query 'select * from user_info where id <5 and $CONDITIONS' --split-by id --target-dir /user/root/mysql/user_info -m 2
参数解析:
--query: 导入过程使用SQL语句
--split-by:表中的那一列作为任务分配列并列:有id列1,2,3,4, 5,6,-m选项为2,那么将分为1,2,3记录通过一个map任务来执行,4,5,6,通过另一个map任务来执行
--target-dir: 指定HDFS上存放数据目录
where $CONDITIONS: 当使用--query的时候需要有$CONDITIONS[root@master tmp]# sqoop import --connect jdbc:mysql://master:3306/test --username root --password root --query 'select * from user_info where id <5 and $CONDITIONS' --split-by id --target-dir /user/root/mysql/user_info -m 2# 查看导入结果[root@master tmp]# hadoop fs -cat /user/root/mysql/user_info/part-m-000001,redskirt,m,1002,honey,m,90

- Select语句导入空值处理
sqoop import --connect jdbc:mysql://mysql-serverip:3306/sqoop --username root --password root --query 'select * from user_info where $CONDITIONS' --split-by id --target-dir /data/sqoop/mysql/user_info -m 2 --null-string '' --null-non-string ''
参数解析:
当从数据库中拉取过来的数据存在空值,默认Sqoop会设置为null,通过下面参数,来替换null值。
举例语句中,null值,设置为了空:
--null-string:string类型替换为第一个''中指定的值
--null-non-string:非string类型替换为第二个''中指定的值mysql> select * from user_info;+----+----------+--------+-------+| id | name | gender | grade |+----+----------+--------+-------+| 1 | redskirt | m | 100 || 2 | honey | m | 90 || 3 | lw | m | 92 || 4 | nicholas | m | 99 || 5 | sasaki | m | 99 || 6 | NULL | NULL | NULL |+----+----------+--------+-------+6 rows in set (0.00 sec)[root@master tmp]# hadoop fs -rmr /user/root/mysql/user_info[root@master tmp]# sqoop import --connect jdbc:mysql://master:3306/test --username root --password root --query 'select * from user_info where $CONDITIONS' --split-by id --target-dir /user/root/mysql/user_info -m 2 --null-string '' --null-non-string ''[root@master tmp]# hadoop fs -cat /user/root/mysql/user_info/part-m-000001,redskirt,m,1002,honey,m,903,lw,m,92[root@master tmp]# hadoop fs -cat /user/root/mysql/user_info/part-m-000014,nicholas,m,995,sasaki,m,996,,,
- 导入库下所有语句
sqoop import-all-tables --connect jdbc:mysql://mysql-serverip:3306/sqoop --username root --password root
参数解析:
import-all-tables:导入指定库下面所有的表[root@master tmp]# hadoop fs -rmr /user/root/user_info[root@master tmp]# sqoop import-all-tables --connect jdbc:mysql://master:3306/test --username root --password root
- 指定某些列导入HDFS
sqoop import --connect jdbc:mysql://master:3306/test --username root --password root --table user_info --target-dir /user/root/user_info -m 1 --null-string '' --null-non-string '' --columns id,name
参数解析:
--columns:指定导出哪几列[root@master tmp]# hadoop fs -rmr /user/root/user_info[root@master tmp]# sqoop import --connect jdbc:mysql://master:3306/test --username root --password root --table user_info --target-dir /user/root/user_info -m 1 --null-string '' --null-non-string '' --columns id,name[root@master tmp]# hadoop fs -cat /user/root/user_info/part-m-000001,redskirt2,honey3,lw4,nicholas5,sasaki6,
HDFS数据导入mysql
- 数据导出到mysql表
sqoop export --connect jdbc:mysql://mysql-serverip:3306/test --username root --password root --table user_info_ --fields-terminated-by ',' --export-dir /user/root/mysql/user_info --input-null-string '' --input-null-non-string ''
参数解析:
export:从HDFS导出mysql(或其他RDBMS)
--table:mysql当中表
--fields-terminated-by:源数据字段分隔符
--export-dir:源数据HDFS上位置# 创建目标表结构mysql> use test;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedmysql> create table if not exists user_info_(-> id int(11) not null primary key auto_increment,-> name varchar(50)-> );Query OK, 0 rows affected (0.00 sec)# 执行导出[root@master tmp]# sqoop export --connect jdbc:mysql://master:3306/test --username root --password root --table user_info_ --fields-terminated-by ',' --export-dir /user/root/mysql/user_info --input-null-string '' --input-null-non-string ''# 查看数据库mysql> select * from user_info_;+----+----------+| id | name |+----+----------+| 1 | redskirt || 2 | honey || 3 | lw || 4 | nicholas || 5 | sasaki || 6 | NULL |+----+----------+6 rows in set (0.00 sec)
- Batch模式数据导入到mysql表
sqoop export -Dsqoop.export.records.per.statement=10 -- connect jdbc:mysql://mysql-server-ip:3306/sqoop --username root --password root --table user_info_bak --fields-terminatedby ',' --export-dir /user/root/mysql/user_info
参数解析
--Dsqoop.export.records.per.statement=10指定每10条数据执行一次insert类似 INSERT INTO xxx VALUES (), (), (), ...
或是
--Dsqoop.export.records.per.transaction=10指定每次事务多少条记录被insert,类似BEGIN; INSERT, INSERT, .... COMMIT- HDFS数据对mysql表做更新
sqoop export --connect jdbc:mysql://mysql-serverip:3306/sqoop --username sqoop --password sqoop --table user_info_bak --update-key id --fields-terminated-by ',' --export-dir /user/root/mysql/user_info
参数解析
--update-key id指定根据那个列进行更新,也可指定多列,用逗号分隔。
相当于:update user_info_bak set name=‘xxx’… where id=“1’;update user_info_bak set name=‘ yyy’… where id=“2’;…
- HDFS导出mysql表空值处理
sqoop export --connect jdbc:mysql://mysql-serverip:3306/sqoop --username sqoop --password sqoop --table user_info --input-null-string '' --input-null-non-string ''
参数解析
同导入的含义相同
--input-null-string:会被翻译成数据库中string列NULL的值
--input-null-non-string:被翻译成数据库中非string列NULL的值
三、导入Hbase,Hive场景
mysql数据导入Hive
- mysql直接导入到hive
sqoop import --connect jdbc:mysql://master:3306/tmpbase --username root --password password --table user_info --hive-import -hive-database default --hive-table user_info_bak
参数解析:
--hive-import:该次导入任务为导向hive
--hive-table:要导入的hive表
--hive-database:导入的hive库
注意两边表结构要一致mysql数据导入Hbase
- mysql直接导入到hbase
sqoop import --connect jdbc:mysql://master:3306/tmpbase --username root --password password --table user_info --hbase-table user_info --column-family f --hbase-createtable
参数解析:
--hbase-table:要导入的hbase表
--column-family:指定hbase表中列族
--hbase-create-table:如果HBase表没有创建,自行创建
注意:实际使用效率较差,小数据量情况下使用(100百万以下数据,可以尝试使用)- Mysql bulk load方式导入到hbase
sqoop import --connect jdbc:mysql://master:3306/tmpbase --username root --password password --table user_info --hbase-table user_info --column-family f --hbase-createtable --hbase-bulkload
参数解析:
--hbase-table:要导入的hbase表
--column-family:指定hbase表中列族
--hbase-create-table:如果HBase表没有创建,自劢创建
--hbase-bulkload:以bulkload方式导入HBase,而非直接put
四、Sqoop增量导入
Sqoop Append增量模式
ppend模式:追加模式,必须是数值字段(1,2,3,4)
适用范围:有自增序列sqoop import --connect jdbc:mysql://mysql-serverip:3306/sqoop --username root --password root --query 'select * from user_info where $CONDITIONS' --split-by id --target-dir /data/sqoop/ -m 1 --incremental append -- check-column grade --last-value 80
参数解析:
--incremental:指定sqoop增量模式
--check-column:指定增量的列
--last-value:指定列值从那一行开始Sqoop Lastmodified增量模式
Lastmodified模式:根据时间戳更新模式。
适用范围:有自增序列sqoop import --connect jdbc:mysql://msyql-serverip:3306/sqoop --username root --password root --query 'select * from user_info where $CONDITIONS' --split-by id --target-dir /data/sqoop -m 1 --incremental lastmodified --check-column c_date --append --last-value '2015-03-05 01:16:18'
参数解析:
--incremental:指定sqoop增量模式
--check-column:指定增量的列(datatime类型)
--last-value:指定从那一段时间到当前开始
--c_date:datetime
五、Sqoop Job定义
Sqoop定义任务
- 定义user_info Job
sqoop job --create user_info -- import --connect jdbc:mysql://mysql-server-ip:3306/sqoop --username root --password root --table user_info -m 1
参数解析:
sqoop job –create:将创建一个Job名字为user_infoSqoop执行任务及修改Job参数
- 执行定义的 Job
sqoop job -exec user_info
参数解析:
sqoop job -exec:将执行已经定义好的user_info覆盖定义Job的默认参数
sqoop job -exec user_info -- -m 3:覆盖之前存在的参数-m 1为-m 3
