@sasaki
2016-01-27T02:32:27.000000Z
字数 16879
阅读 4069
NoSQL与Redis分布式缓存数据库
Redis
版本控制
@Title NoSQL与Redis分布式缓存数据库@Version v1.0@Timestamp 2015-01-19 16:42@Author Nicholas@Mail redskirt@outlook.com
一、NoSQL介绍
简介
NoSQL是以key-value形式存储,和传统的关系型数据库不一样,不一定遵循传统数据库的一些基本要求,比如SQL标准、ACID属性、表结构等,这类数据库主要有以下特点:非关系型、分布式、开源、水平可拓展等。适用场景
- 对数据库高并发读写
- 对海量数据的高效率存储和访问
- 对数据的高可扩展性和高可用性
二、Redis概述
Redis是一个Key-Value的存储系统。它支持存储的value类型很多,包括string(字符串)、list(链表)、set(集合)、zset(有序集合)。这些数据类型都支持p**ush/pub、add/remove**及取秶和并集及更丰富的操作,Redis支持各种不同方式的排序。为了保证效率,数据都是缓存在内存中,它也可以周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。
Redis适用场合
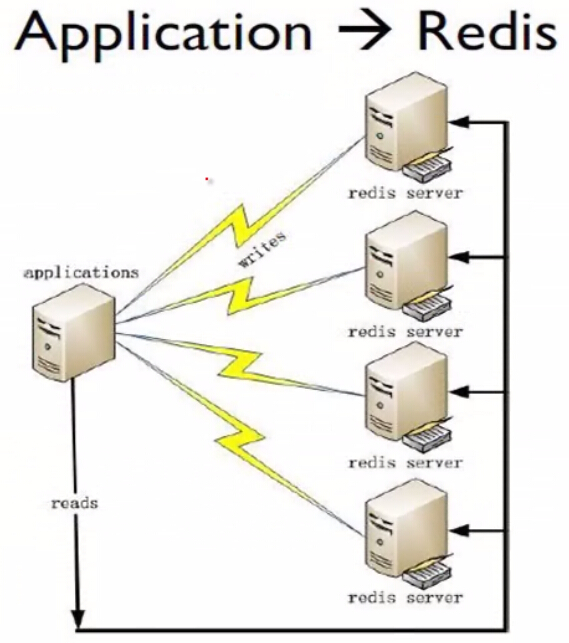
1)应用直接访问Redis
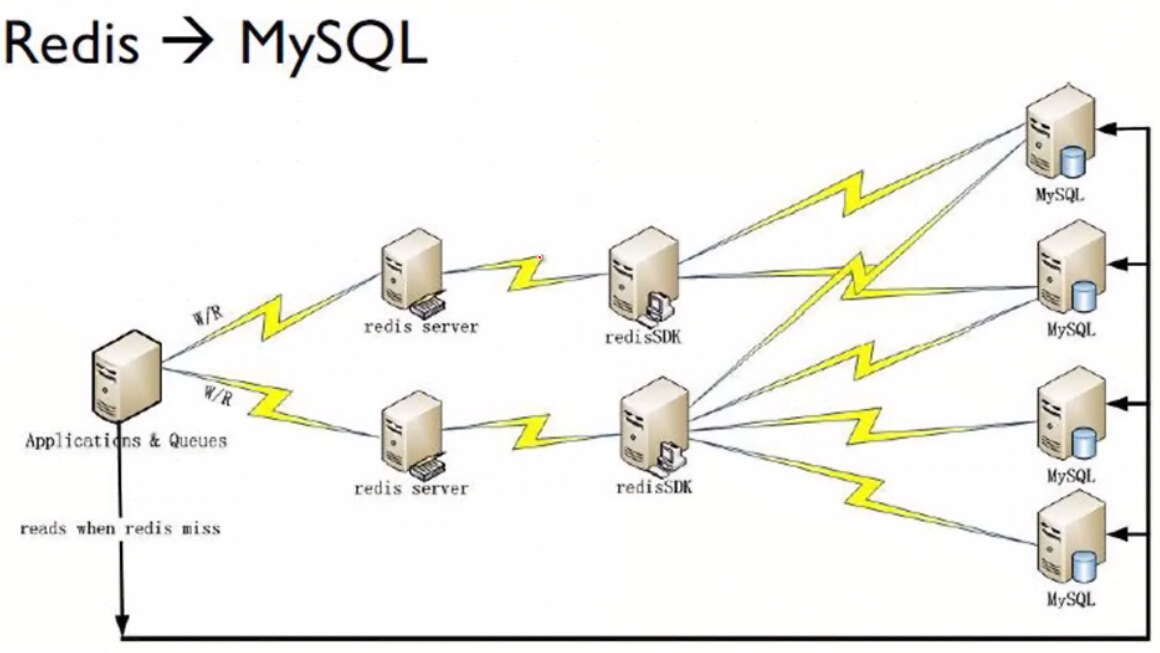
2)应用程序直接访问Redis,当Redis访问失败时访问MySQL
- 取最新N个数据的操作
- 排行榜应用,取TopN操作
- 需要精确设定过期时间的应用
- 计数器应用
- Uniq操作,获取某段时间所有数据排重值
- 实时系统,反垃圾系统
- Pub/Sub构建实时消息系统
- 构建队列系统
- 缓存
Redis主要配置含义
- daemonize:是否以后台daemon方式运行
- pidfile:pid文件位置
- port:监听的端口号
- timeout:请求超时时间
- loglevel:log信息级别
- logfile:log文件位置
- databases:开启数据库的数量
- save * :保存快照的频率,第一个表示多长时间,第三个*表示执行多少次写操作。在一定时间内执行一定数量的写操作时,自动保存快照。可设置多个条件。
- rdbcompression:是否使用压缩
- dbfilename:数据快照文件名(只是文件名,不包括目录)
- dir:数据快照的保存目录(这个是目录)
- appendonly:是否开启appendonlylog,开启的话每次写操作会记一条log,这会提高数据抗风险能力,但影响效率
- appendfsync:appendonlylog如何同步到磁盘(三个选项,分别是每次写都强制调用fsync、每秒启用一次fsync、不调用fsync等待系统自己同步)
三、Redis应用
Redis数据类型
string:一个Key对应一个Value,string类型是二进制安全的。Redis的string可以包含任何对象,比如jpg图片或序列化的对象。[root@master ~]# netstat -tunpl|grep 6379tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 28424/redis-servertcp 0 0 :::6379 :::* LISTEN 28424/redis-server[root@master redis-3.0.6]# redis-cli# set127.0.0.1:6379> set str helloOK# get127.0.0.1:6379> get str"hello"# setnx:设置key对应的值为string类型的value,如果key已经存在,返回0,nx是not exist的意思127.0.0.1:6379> setnx str hello(integer) 0# setex:设置key对应的值为string类型的value,并指定此键值对应的有效期127.0.0.1:6379> setex str_ 10 testOK127.0.0.1:6379> get str_"test"127.0.0.1:6379> get str_(nil)# setrange:设置指定key的value值的子字符串127.0.0.1:6379> set num 123456789OK127.0.0.1:6379> get num"123456789"127.0.0.1:6379> setrange num 6 666(integer) 9127.0.0.1:6379> get num"123456666"# mset:设置多个key的值,成功返回ok,失败返回0表示没有任何值被设置127.0.0.1:6379> mset key1 liuwei key2 nicholas key3 sasakiOK127.0.0.1:6379> get key1"liuwei"127.0.0.1:6379> get key2"nicholas"127.0.0.1:6379> get key3"sasaki"# mset x:设置多个key的值,成功返回ok,失败返回0表示没有任何值被设置,但是不会覆盖已存在的key127.0.0.1:6379> msetnx key1 liuwei_ key4 test(integer) 0127.0.0.1:6379> get key1"liuwei"127.0.0.1:6379> get key4(nil)# get:获取key的string值,若不存在返回nil# getset:设置key值并且返回key的旧值127.0.0.1:6379> getset key1 test"liuwei"127.0.0.1:6379> get key1"test"# getrange:获取key的子字符串127.0.0.1:6379> get key2127.0.0.1:6379> getrange key2 0 4"nicho"# mget:指获取key的子字符串,若不存在刚返回nil127.0.0.1:6379> mget key1 key2 key3 0 41) "test"2) "nicholas"3) "sasaki"4) (nil)5) (nil)# incr:对key的值作加加操作,返回新值127.0.0.1:6379> set num 10OK127.0.0.1:6379> get num"10"127.0.0.1:6379> incr num(integer) 11127.0.0.1:6379> incr num(integer) 12# incrby:同incr,加指定值,key值不存在会设置key,并认为原key值为0127.0.0.1:6379> incrby num_ 20(integer) 20127.0.0.1:6379> incrby num__ 6(integer) 6127.0.0.1:6379> incrby num__ 6(integer) 12127.0.0.1:6379> incrby num__ 6(integer) 18# decr:对key的值作减减操作,返回新值# decrby:同decr,减指定值,key值不存在会设置key,并认为原key值为0# append:给指定key的字符串追加value,返回新字符串值的长度127.0.0.1:6379> set head redskirtOK127.0.0.1:6379> append head @outlook.com(integer) 20127.0.0.1:6379> get head"redskirt@outlook.com"# strlen:取指定key的value值的长度127.0.0.1:6379> strlen head(integer) 20
hashes:Redis hash是一个string类型的filed和value的映射表。它的添加、删除操作都是0(1)(平均)。hash特别合适用于存储对象。相比于将对象的每个字段存成单个string类型,将一个对象存储在hash类型中会占用更少的内存,并且可以更方便的存取整个对象。
# hset:设置hash field为指定值,如果key不存在,刚先创建127.0.0.1:6379> hset user:001 name nicholas(integer) 1127.0.0.1:6379> hget user:001 name"nicholas"# hsetnx:设置hash field为指定值,如果key不存在刚先创建,如果存在返回0127.0.0.1:6379> hsetnx user:002 name lamp(integer) 1127.0.0.1:6379> hget user:002 name"lamp"127.0.0.1:6379> hsetnx user:002 name lamp(integer) 0# hmset:同时设置hash的多个field127.0.0.1:6379> hmset user:003 name nicholas age 20 gender mOK127.0.0.1:6379> hget user:003 age"20"127.0.0.1:6379> hget user:003 gender"m"# hget:获取hash field的值# hmget:获取全部指定的hash filed127.0.0.1:6379> hmget user:003 name age gender1) "nicholas"2) "20"3) "m"# hincrby:给指定的hash filed加上指定值127.0.0.1:6379> hincrby user:003 age 3(integer) 23# gexists:判断指定filed是否存在127.0.0.1:6379> hexists user:003 age(integer) 1127.0.0.1:6379> hexists user:003 age_(integer) 0# hlen:返回指定hash的filed的数量127.0.0.1:6379> hlen user:003(integer) 3# ldel:删除指定hash的filed127.0.0.1:6379> hdel user:003 age(integer) 1127.0.0.1:6379> hget user:003 age(nil)# hkeys:返回hash的所有filed127.0.0.1:6379> hkeys user:0031) "name"2) "gender"# hgetall:获取某hash中全部的file及value127.0.0.1:6379> hgetall user:0031) "name"2) "nicholas"3) "gender"4) "m"
lists:List是一个链表结构,主要功能是push、pop、获取一个范围的所有值等等,操作中key理解为链表的名字。Redis的list类型其实就是一个每个子元素都是string类型的双向链表。可以通过push、pop操作从链表的头部或者尾部添加删除元素,这样List既可作为栈,又可以作为队列。
# lpush:在key对应list的头部添加字符串元素,模拟栈127.0.0.1:6379> lpush list 1(integer) 1127.0.0.1:6379> lpush list 2(integer) 2127.0.0.1:6379> lpush list 3(integer) 3127.0.0.1:6379> lrange list 0 -11) "3"2) "2"3) "1"# rpush:在key对应list的尾部添加字符串元素,模拟队列127.0.0.1:6379> lpush list_ 1(integer) 1127.0.0.1:6379> lpush list_ 2(integer) 2127.0.0.1:6379> lpush list_ 3(integer) 3127.0.0.1:6379> lrange list_ 0 -11) "1"2) "2"3) "3"# linsert:在key对应的list的特定位置前或后添加字符串127.0.0.1:6379> lpush list3 1(integer) 1127.0.0.1:6379> lpush list3 2(integer) 2127.0.0.1:6379> lrange list3 0 -11) "2"2) "1"127.0.0.1:6379> linsert list3 before 1 3(integer) 3127.0.0.1:6379> lrange list3 0 -11) "2"2) "3"3) "1"# lset:设置List中指定下标的元素值127.0.0.1:6379> lrange list3 0 -11) "2"2) "3"3) "1"127.0.0.1:6379> lset list3 0 4OK127.0.0.1:6379> lrange list3 0 -11) "4"2) "3"3) "1"# lrem:从key对应的List中删除n个和value相同的元素。(n<0从尾删除,n=0全部删除)127.0.0.1:6379> lrange list3 0 -11) "4"2) "3"3) "1"127.0.0.1:6379> lrem list3 1 4(integer) 1127.0.0.1:6379> lrange list3 0 -11) "3"2) "1"127.0.0.1:6379> lpush list3 5(integer) 3127.0.0.1:6379> lpush list3 5(integer) 4127.0.0.1:6379> lpush list3 5(integer) 5127.0.0.1:6379> lrange list3 0 -11) "5"2) "5"3) "5"4) "3"5) "1"127.0.0.1:6379> lrem list3 0 5(integer) 3127.0.0.1:6379> lrange list3 0 -11) "3"2) "1"# ltrim:保留指定key的值范围内的数据127.0.0.1:6379> lpush list5 1 2 3 4 5 6(integer) 6127.0.0.1:6379> lrange list5 0 -11) "6"2) "5"3) "4"4) "3"5) "2"6) "1"127.0.0.1:6379> ltrim list5 0 3OK127.0.0.1:6379> lrange list5 0 -11) "6"2) "5"3) "4"4) "3"# lpop:从List的头部删除元素,并返回删除元素127.0.0.1:6379> lrange list5 0 -11) "6"2) "5"3) "4"4) "3"127.0.0.1:6379> lpop list5"6"127.0.0.1:6379> lrange list5 0 -11) "5"2) "4"3) "3"# rpop:从List的尾部删除元素,并返回删除元素127.0.0.1:6379> rpop list5"3"127.0.0.1:6379> lrange list5 0 -11) "5"2) "4"# rpoplpush:从第一个List的尾部移除元素并添加到第二个List的头部127.0.0.1:6379> rpush list9 1 2(integer) 2127.0.0.1:6379> rpush list10 1 2(integer) 2127.0.0.1:6379> lrange list9 0 -11) "1"2) "2"127.0.0.1:6379> lrange list10 0 -11) "1"2) "2"127.0.0.1:6379> rpoplpush list9 list10"2"127.0.0.1:6379> lrange list9 0 -11) "1"127.0.0.1:6379> lrange list10 0 -11) "2"2) "1"3) "2"# lindex:返回名称为key的List中的index位置的元素127.0.0.1:6379> lrange list10 0 -11) "2"2) "1"3) "2"127.0.0.1:6379> lindex list10 0"2"127.0.0.1:6379> lindex list10 1"1"# llen:返回key对应的List的长度127.0.0.1:6379> llen list10(integer) 3
sets:Set是string类型的无序集合,通过hash table实现,添加、删除和查找的复杂度都是0(1),可以对集合取并集、交集、差集。通过这些操作可以实现SNS好友推荐和Blog的Tag功能。
# sadd:向名称为key的Set中添加元素127.0.0.1:6379> sadd set1 1(integer) 1127.0.0.1:6379> sadd set1 2(integer) 1127.0.0.1:6379> sadd set1 2(integer) 0127.0.0.1:6379> smembers set11) "1"2) "2"# srem:删除名称为key的Set中的元素127.0.0.1:6379> srem set1 2(integer) 1127.0.0.1:6379> srem set1 2(integer) 0127.0.0.1:6379> smembers set11) "1"# spop:随机返回并删除名称为key的Set中的一个元素127.0.0.1:6379> smembers set21) "1"2) "2"3) "3"4) "4"5) "5"127.0.0.1:6379> spop set2"3"127.0.0.1:6379> spop set2"1"127.0.0.1:6379> spop set2"5"127.0.0.1:6379> smembers set21) "2"2) "4"# sdiff:返回所有给定key与第一个key的差集127.0.0.1:6379> smembers set21) "2"2) "4"127.0.0.1:6379> smembers set31) "1"2) "2"3) "3"4) "4"127.0.0.1:6379> sdiff set2 set3(empty list or set)127.0.0.1:6379> sdiff set3 set21) "1"2) "3"# sinter:返回所有给定key的交集127.0.0.1:6379> sinter set2 set31) "2"2) "4"# sinterstore:返回所有给定key的交集,并将结果存为另一个key127.0.0.1:6379> smembers set21) "2"2) "4"127.0.0.1:6379> smembers set31) "1"2) "2"3) "3"4) "4"127.0.0.1:6379> sinterstore set4 set2 set3(integer) 2127.0.0.1:6379> smembers set41) "2"2) "4"# sunion:返回所有给定的key的并集127.0.0.1:6379> sunion set2 set31) "1"2) "2"3) "3"4) "4"# sunionstore:返回所有给定key的并集,并将结果存为另一个key127.0.0.1:6379> sunionstore set5 set2 set3(integer) 4127.0.0.1:6379> smembers set51) "1"2) "2"3) "3"4) "4"# smove:从第一个key对应的Set中移除member并添加到第二个对应的Set中127.0.0.1:6379> smove set2 set3 2(integer) 1127.0.0.1:6379> smembers set21) "4"127.0.0.1:6379> smembers set31) "1"2) "2"3) "3"4) "4"# scard:返回名称为key的Set的元素个数127.0.0.1:6379> scard set3(integer) 4# sismember:判断member是否为名称为key的Set的元素127.0.0.1:6379> scard set3(integer) 4127.0.0.1:6379> sismember set3 1(integer) 1127.0.0.1:6379> sismember set3 5(integer) 0# srandmember:随机返回名称为key的Set的一个元素,但不删除元素127.0.0.1:6379> srandmember set3"2"127.0.0.1:6379> srandmember set3"1"127.0.0.1:6379> srandmember set3"3"127.0.0.1:6379> smembers set31) "1"2) "2"3) "3"4) "4"
sorted set:sorted set在set的基础上增加了顺序属性,在添加元素时可以指定顺序,每次指定后,zset会自动重新按新的值调整顺序。可以理解为有两列的Mysql表,一列存Value,一列存顺序。操作中key理解为zset的名字。
# zadd:向名称为key的Zset中添加元素member,score用于排序。如果该元素存在则更新其顺序。127.0.0.1:6379> zadd zset1 1 one(integer) 1127.0.0.1:6379> zadd zset1 2 two(integer) 1127.0.0.1:6379> zadd zset1 3 two(integer) 0127.0.0.1:6379> zadd zset1 4 four(integer) 1127.0.0.1:6379> zrange zset1 0 -1 withscores1) "one"2) "1"3) "two"4) "3"5) "four"6) "4"# zrem:删除名称为key的Zset中的元素member127.0.0.1:6379> zrem zset1 two(integer) 1127.0.0.1:6379> zrem zset1 two(integer) 0127.0.0.1:6379> zrange zset1 0 -1 withscores1) "one"2) "1"3) "four"4) "4"# zincrby:如果在名称为key的Zset中已经存在元素member,则该元素的score增加incrememt,否则向该集合中添加该元素,其中score的值为increment127.0.0.1:6379> zincrby zset1 2 one"3"127.0.0.1:6379> zincrby zset1 4 five"4"127.0.0.1:6379> zrange zset1 0 -1 withscores1) "one"2) "3"3) "five"4) "4"5) "four"6) "4"# zrank:返回名称为key的Zset中memmber的元素排名(按score升序排序),即下标127.0.0.1:6379> zrank zset1 one(integer) 0127.0.0.1:6379> zrank zset1 five(integer) 1127.0.0.1:6379> zrank zset1 four(integer) 2# zrevrank:返回名称为key的Zset中memmber的元素排名(按score降序排序),即下标127.0.0.1:6379> zrevrank zset1 one(integer) 2127.0.0.1:6379> zrevrank zset1 five(integer) 1127.0.0.1:6379> zrevrank zset1 four(integer) 0# zrevrange:返回名称为key的Zset(按score降序)中的index从start到end的所有元素127.0.0.1:6379> zrevrange zset2 0 -1 withscores1) "four"2) "4"3) "three"4) "3"5) "two"6) "2"7) "one"8) "1"# zrangebyscore:返回集合中score在给定区间的元素127.0.0.1:6379> zrangebyscore zset2 2 4 withscores1) "two"2) "2"3) "three"4) "3"5) "four"6) "4"# zcount:返回集合中score在给定区间的数量127.0.0.1:6379> zcount zset2 1 4(integer) 4# zcard:返回集合中的元素个数127.0.0.1:6379> zcard zset2(integer) 4# zremrangebyrank:依据索引删除集合中排名在给定区间的元素127.0.0.1:6379> zremrangebyrank zset2 1 3(integer) 3127.0.0.1:6379> zrange zset2 0 -1 withscores1) "one"2) "1"# zremrangebyscore:依据顺序删除集合中排名在给定区间的元素127.0.0.1:6379> zrange zset3 0 -1 withscores1) "one"2) "1"3) "two"4) "2"5) "three"6) "3"7) "four"8) "4"9) "five"10) "5"127.0.0.1:6379> zremrangebyscore zset3 1 3(integer) 3127.0.0.1:6379> zrange zset3 0 -1 withscores1) "four"2) "4"3) "five"4) "5"
Redis常用命令
1)键值相关命令
# keys:返回满足给定pattern的所有key127.0.0.1:6379> keys *1) "num__"2) "num"3) "head"4) "set4"5) "zset1"6) "hello"7) "zset3"8) "list3"9) "list4"10) "set2"127.0.0.1:6379> keys set*1) "set4"2) "set2"3) "set1"4) "set3"5) "set5"# exists:确认一个key是否存在127.0.0.1:6379> exists zset(integer) 0127.0.0.1:6379> exists zset1(integer) 1# del:删除一个key127.0.0.1:6379> del set3(integer) 1127.0.0.1:6379> exists set3(integer) 0# expire:设置一个key的过期时间127.0.0.1:6379> expire set1 10(integer) 1127.0.0.1:6379> ttl set1(integer) -2# move:移动key到指定数据库127.0.0.1:6379> exists set5(integer) 1127.0.0.1:6379> move set5 1(integer) 1127.0.0.1:6379> exists set5(integer) 0127.0.0.1:6379> select 1OK127.0.0.1:6379[1]> exists set5(integer) 1# persist:移除给定key的过期时间127.0.0.1:6379[1]> expire set5 300(integer) 1127.0.0.1:6379[1]> ttl set5(integer) 294127.0.0.1:6379[1]> persist set5(integer) 1127.0.0.1:6379[1]> ttl set5(integer) -1# randomkey:随机返回key空间的一个key127.0.0.1:6379> randomkey"list6"127.0.0.1:6379> randomkey"key3"127.0.0.1:6379> randomkey"list10"127.0.0.1:6379> randomkey"head"# rename:重命名key127.0.0.1:6379> rename key3 key30OK127.0.0.1:6379> exists key3(integer) 0127.0.0.1:6379> exists key30(integer) 1# type:返回值的类型127.0.0.1:6379> type key30string127.0.0.1:6379> type zset3zset
2)服务器相关命令
# ping:测试连接是否存活127.0.0.1:6379> pingPONG# echo:在命令行打印内容127.0.0.1:6379> echo honey"honey"# select:选择数据库。Redis数据库编号从0~15127.0.0.1:6379> select 0OK127.0.0.1:6379> select 1OK127.0.0.1:6379[1]> keys *(empty list or set)# quit:退出连接# dbsize:返回当前数据库中key的数目127.0.0.1:6379> dbsize(integer) 28# info:返回Redis服务器信息# config get:实时转存收到的请求127.0.0.1:6379> config get dir1) "dir"2) "/usr/redis-3.0.6"127.0.0.1:6379> config get *1) "dbfilename"2) "dump.rdb"3) "requirepass"4) ""5) "masterauth"6) ""7) "unixsocket"8) ""9) "logfile"...# flushdb:删除当前选择数据库中的所有key127.0.0.1:6379> flushdbOK127.0.0.1:6379> dbsize(integer) 0# flushall:删除所有数据库中的所有key127.0.0.1:6379> flushallOK
Redis高级实用特性
- 安全性
- 主从复制
- 事务处理
- 持久化机制
- 发布订阅消息
- 虚拟内存使用
安全性:设置客户端连接后进行任何其他指定前需要使用的密码。
警告:因为redis速度相当快,所以在一台比较好的服务器下,一个外部的用户可以在一秒钟进行150K次的密码尝试,这意味着你需要指定非常非常强大的密码来防止暴力破解。[root@master ~]# vim /usr/redis-3.0.6/redis.conf...requirepass honey[root@master ~]# pkill redis-server[root@master ~]# redis-server /usr/redis-3.0.6/redis.conf &# 进入Redis后用auth授权**127.0.0.1:6379> auth honeyOK127.0.0.1:6379> keys *(empty list or set)**# 或者登陆Redis时直接授权[root@master ~]# redis-cli -a honey
主从复制:Redis主从复制配置和使用都非常简单。通过主从复制可以允许多个slave server拥有和master server相同的数据库副本。
主从复制特点:
- master可以拥有多个slave
- 多个slave可以连接同一个master外,还可以连接到其他slave
- 主从复制不会阻塞master,在同步数据时,master可以继续处理client请求
- 提高系统的伸缩性
redis主从复制过程:
当配置好slave后,slave与master建立连接,然后发送sync命令。无论是第一次连接还是重新连接,master都会启动一个后台进程,将数据库快照保存到文件中,同时master主进程会开始收集新的写命令并缓存。后台进程完成写文件后,master就发送文件给slave,slave将文件保存到硬盘上,再加载到内存中,接着master就会把缓存的命令转发给slave,后续master将收到的写命令发送给slave。如果master同时收到多个slave发来的同步连接命令,master只会启动一个进程来写数据库镜像,然后发送给所有的slave。配置主从服务器
[root@slave01 ~]# cd /usr/redis-3.0.6/[root@slave01 redis-3.0.6]# vim redis.conf...slaveof master 6379masterauth honey# 在主数据库中设置key[root@master ~]# redis-cli -a honey127.0.0.1:6379> flushall10025:M 26 Jan 15:35:50.769 * DB saved on diskOK127.0.0.1:6379> set key testsyncOK# 从数据库中会自动同步[root@slave01 redis-3.0.6]# redis-cli -a honey127.0.0.1:6379> keys *1) "key"127.0.0.1:6379> get key"testsync"# info查看主从信息127.0.0.1:6379> info...# Replicationrole:slavemaster_host:mastermaster_port:6379master_link_status:upmaster_last_io_seconds_ago:1master_sync_in_progress:0
事务处理
redis目前还是支持比较简单的事务处理,redis只能保证一个client发起的事务中的命令连续执行,而中间不会插入其他client的命令。
一个client在一个连接中发起multi命令,这个链接会进入事务的上下文,该链接后续的命令不会被立即执行;而是先放到一个队列中,当执行exec命令后,redis会顺序执行队列中的命令。
如果不行执行这个事务的话,可以用discard命令取消事物;队列中的命令会被取消,事务回滚掉。# multi开启一个事务127.0.0.1:6379> multiOK127.0.0.1:6379> set age 10QUEUED127.0.0.1:6379> set age 100QUEUED127.0.0.1:6379> exec1) OK2) OK127.0.0.1:6379> get age"100"# discard取消一个事务127.0.0.1:6379> get age"100"127.0.0.1:6379> multiOK127.0.0.1:6379> set age 10QUEUED127.0.0.1:6379> set age 23QUEUED127.0.0.1:6379> discardOK127.0.0.1:6379> get age"100"# Redis只支持较简单的事务,事务过程中若有异常,整个事务不会回滚127.0.0.1:6379> multiOK127.0.0.1:6379> incr ageQUEUED127.0.0.1:6379> set name honeyQUEUED127.0.0.1:6379> incr nameQUEUED127.0.0.1:6379> exec1) (integer) 1012) OK3) (error) ERR value is not an integer or out of range127.0.0.1:6379> get age"101"
Redis乐观锁的复杂事务
乐观锁大多是基于数据版本(Version)记录机制实现。何谓数据版本?即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个“version”字段来实现。读取出数据时,将此版本号一同读出,之后更新时,对此Version+1。此时,将提交数据的版本数据与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据。# 乐观锁实例:对于一个key为name,我们开2个session对这个key进行赋值# session1中127.0.0.1:6379> set name honeyOK127.0.0.1:6379> get name"honey"127.0.0.1:6379> watch nameOK127.0.0.1:6379> multiOK127.0.0.1:6379> set name honey_QUEUED# session2中127.0.0.1:6379> set name nicholasOK127.0.0.1:6379> get name"nicholas"# 返回session1提交事务127.0.0.1:6379> exec(nil)127.0.0.1:6379> get name"nicholas"
watch命令会监视给定的key,当exec的时候如果该key在watch后发生过变化的话,则整个事物就会失败;也可以调用watch对多个key进行监视,这样就可以对多个key加乐观锁了。注意watch指定的key只对整个连接有效的,事务也是如此;若连接断开,监视会自动删除。
悲观锁正如其名,具有强烈的独占和排他特性。它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。
持久化机制
redis持久化方式有两种:
1)snapshotting,默认方式
默认redis是会以快照的形式将数据持久化到磁盘的(一个二进制文件,dump.rdb,这个文件名字可以指定),在配置文件(redis.conf)中的格式是:save N M表示在N秒之内,redis至少发生M次修改则redis抓快照到磁盘。当然我们也可以手动执行save或者bgsave(异步)做快照。# Redis会把数据持久化到dump.rdb文件中[root@master redis-3.0.6]# ll dump.rdb-rw-r--r--. 1 root root 18 Jan 26 14:12 dump.rdb
2)aof(Append-only file)方式
filesnapshotting方法在redis异常死掉时,最近的数据会丢失(丢失数据的多少视你save策略的配置),所以这是它最大的缺点,当业务量很大时,丢失的数据是很多的。Append-only方法可以做到全部数据不丢失,但redis的性能就要差些。AOF就可以做到全程持久化,只需要在配置文件中开启(默认是no),appendonly yes开启AOF之后,redis每执行一个修改数据的命令,都会把它添加到aof文件中,当redis重启时,将会读取AOF文件进行“重放”以恢复到redis关闭前的最后时刻。
AOF文件刷新的方式,有三种,在redis.conf参考配置参数appendfsync:
appendfsync always每提交一个修改命令都调用fsync刷新到AOF文件,非常非常慢,但也非常安全;
appendfsync everysec每秒钟都调用fsync刷新到AOF文件,很快,但可能会丢失一秒以内的数据;
appendfsync no依靠OS进行刷新,redis不主动刷新AOF,这样最快,但安全性就差。默认并推荐每秒刷新,这样在速度和安全上都做到了兼顾。消息发布订阅(pub/sub)
消息发布订阅是一种消息通信模式,主要的目的是解耦消息发布者和消息订阅者之间的耦合,这点和设计模式中的观察者模式比较相似。pub /sub不仅仅解决发布者和订阅者直接代码级别耦合也解决两者在物理部署上的耦合。
redis作为一个pub/sub server,在订阅者和发布者之间起到了消息路由的功能。订阅者可以通过subscribe和psubscribe命令向redis server订阅自己感兴趣的消息类型,redis将消息类型称为通道(channel)。当发布者通过publish命令向redis server发送特定类型的消息时。订阅该消息类型的全部client都会收到此消息。这里消息的传递是多对多的。一个client可以订阅多个 channel,也可以向多个channel发送消息。# session1127.0.0.1:6379> subscribe tv1Reading messages... (press Ctrl-C to quit)1) "subscribe"2) "tv1"3) (integer) 11) "message"2) "tv1"3) "message1"1) "message"2) "tv1"3) "hello....."# session2127.0.0.1:6379> subscribe tv1 tv2Reading messages... (press Ctrl-C to quit)1) "subscribe"2) "tv1"3) (integer) 11) "subscribe"2) "tv2"3) (integer) 21) "message"2) "tv1"3) "message1"1) "message"2) "tv1"3) "hello....."# session3127.0.0.1:6379> publish tv1 message1(integer) 2127.0.0.1:6379> publish tv1 hello.....(integer) 2127.0.0.1:6379> publish tv2 hello.....(integer) 1
虚拟内存
Redis的虚拟内存与os的虚拟内存不同,但是思路和目的都是相同的。就是暂时把不经常访问的数据从内存交换到磁盘中,从而腾出宝贵的 内存空间用于其他需要访问的数据。尤其是对于redis这样的内存数据库,内存总是不够用的。除了可以将数据分割到多个redis server外。另外的能够提高数据库容量的办法就是使用vm把那些不经常访问的数据交换的磁盘上。如果我们的存储的数据总是有少部分数据被经常访问,大 部分数据很少被访问,对于网站来说确实总是只有少量用户经常活跃。当少量数据被经常访问时,使用vm不但能提高单台redis server数据库的容量,而且也不会对性能造成太多影响。
