@sasaki
2016-01-21T03:05:29.000000Z
字数 4060
阅读 10480
谈谈Spark运行模式
BigData Spark
版本控制
@Title 谈谈Spark运行模式@Version v1.0@Timestamp 2015-12-25 18:34@Author Nicholas@Mail redskirt@outlook.com
在部署完成Spark集群并通过几种方式运行Demo之后,一直苦恼于对Spark运行模式的理解,查了资料发现不同人有不同的划分,要想对一个点完全吃透,还是必须花功夫转换为自己的东西才行。
在学技术的路上,一直陷入“发现问题-->寻找别人的解决方法-->解决问题”的僵局,殊不知靠自己的理解把问题研究透。重要的不是知识本身,而是自己对知识的理解,哪怕理解偏差,也比总是看着别人写的思想要好些。
一、Spark基本工作流程
关于Spark On YARN,教程讲解的老师是这样说的:
根据Driver运行的位置分为
- yarn-cluster (YarnClusterScheduler)
- yarn-client (YarnClientClusterScheduler)
回顾YARN:
- ApplicationMaster:
- ResourceManager
- NodeManager
- Container
Spark运行组件:
- SparkContext:由用户程度启动,通过资源调试模块和Executor通信
- Executor:执行任务,运行Executor的节点称为Worker
Spark会分别创建:
- DAGScheduler:作业调度模块(高层调度)
- TaskScheduler:任务调度模块(不同运行模式的主要区别)
Spark运行时,每个SparkContext有一个ApplicationMaster,每个Executor对应一个Container。
二、Spark运行模式
Spark的运行模式多种多样,在单机上可以以Local和伪分布式模式运行;部署在集群上时有Spark内建的Standalone模式及对于外部框架的支持,有Mesos模式和Spark On YARN模式,这两者主要区别是资源管理交由谁负责。
Local模式
本地运行,不加任何配置,默认为Local模式。Local模式下运行SparkPi
[root@master ~]# ./bin/run-example org.apache.spark.examples.SparkPi local
Standalone模式
Standalone模式中Spark集群中Master和Worker节点构成。用户程序通过与Master节点交互,申请所需资源,Worker节点负责具体Executor的启动运行。
部署Standalone模式的集群仅需把编译好的Spark发布版本分发到各节点,部署路径尽量一致,且配置文件相同。
[root@master ~]# ./sbin/stark-all.sh # 启动集群[root@master ~]# ./bin/run-example org.apache.spark.examples.SparkPi spark://master:7077 # 运行测试
Local Cluster模式
Local Cluster即伪分布式模式,是基于Standalone模式实现的,启动Master(主进程)和Worker(工作进程)的位置全部在本地。YARN Standalone/YARN Cluster模式
通过Hadoop YARN框架来调度Spark应用所需资源。YARN Client
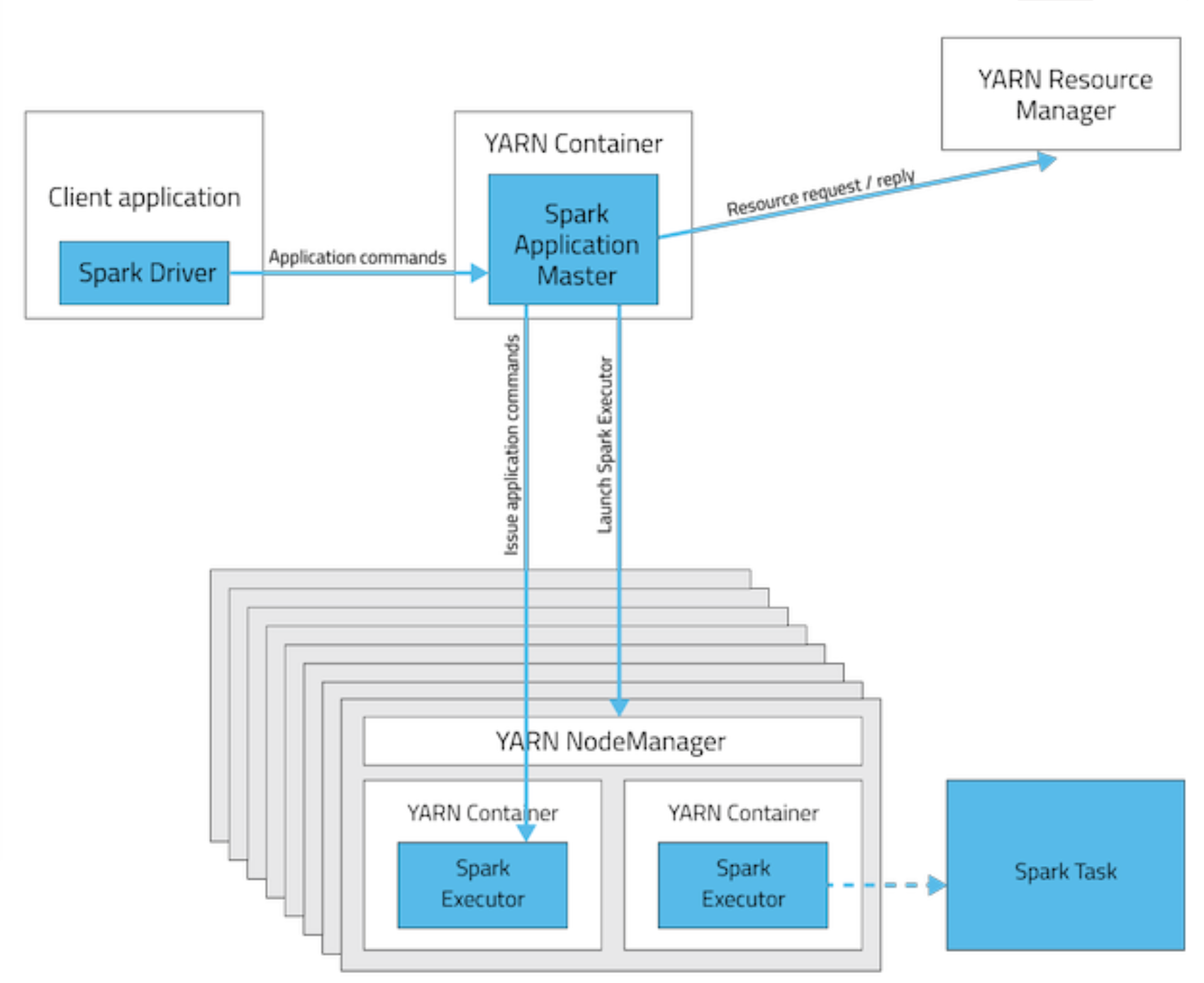
- Driver在任务提交机上执行
- ApplicationMaster只负责向ResourceManager申请executor需要的资源
- 基于yarn时,spark-shell和pyspark必须要使用yarn-client模式
例1:spark-shell
启动YARN Client:
YARN Client中--master 赋值为 yarn-client 或 yarn 写法相同[root@master hadoop]# export HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/hadoop/etc/hadoop[root@master hadoop]# spark-shell --master yarn-client --executor-memory 200m --driver-memory 300m --num-executors 4[root@master hadoop]# spark-shell --master yarn --executor-memory 200m --driver-memory 300m --num-executors 4
在spark-shell中运行WordCount:
scala> sc.textFile("hdfs://master:8020//user/root/wordcount/input/spark-env.sh").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect
例2:yarn-client中提交Pi计算程序
# 所有节点导入SPARK_JAR和HADOOP_CONF_DIR变量[root@master /]# cd /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/spark/bin[root@master hadoop]# export HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/hadoop/etc/hadoop[root@master hadoop]# SPARK_JAR=/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/jars/spark-assembly-1.2.0-cdh5.3.8-hadoop2.5.0-cdh5.3.8.jar# 提交任务到yarn-client[root@master hadoop]# ./spark-class org.apache.spark.deploy.yarn.Client --jar /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/spark/lib/spark-examples-1.2.0-cdh5.3.8-hadoop2.5.0-cdh5.3.8.jar --class org.apache.spark.examples.SparkPi --num-workers 3 --master-memory 512m --worker-memory 512m
- YARN Cluster
Driver运行在ApplicationMaster中,应用在生产过程中。

Spark On YARN提交常用参数:

- Driver以及资源申请都在AppMaster执行
- Client提交任务之后即不再需要执行
例1:yarn-cluster中提交Pi计算程序
[root@master /]# cd /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/spark/bin[root@master hadoop]# export HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/hadoop/etc/hadoop[root@master hadoop]# SPARK_JAR=/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/jars/spark-assembly-1.2.0-cdh5.3.8-hadoop2.5.0-cdh5.3.8.jar[root@master bin]# spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --driver-memory 300m --executor-memory 200m /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/spark/lib/spark-examples-1.2.0-cdh5.3.8-hadoop2.5.0-cdh5.3.8.jar 10
设置Spark yarn-cluster运行时参数
[root@master conf.dist]# pwd/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/etc/spark/conf.dist[root@master conf.dist]# vim spark-defaults.confspark.master spark://master:7077spark.eventLog.enabled truespark.eventLog.dir hdfs://master:8020/user/root/applicationHistory#set spark executor memoryspark.executor.memory 500mspark.driver.memory 500mspark.yarn.historyServer.address master:18080spark.history.fs.logDirectory hdfs://master:8020/root/applicationHistory
Container是YARN分配资源的基本单位。
yarn-client主要用于与用户交互模式,yarn-cluster主要用于集群生产模式,二者主要区别是Driver的运行位置。
Spark Yum 安装
CDH Spark安装后主要配置文件目录为/etc/spark/conf
