@sasaki
2016-03-23T09:15:39.000000Z
字数 16689
阅读 8636
Flume——分布式日志收集工具
BigData
版本控制
@Title Flume——分布式日志收集工具@Version v1.0@Timestamp 2016-01-28 16:03@Author Nicholas@Mail redskirt@outlook.com
Flume是一个分布式的、可靠的、高可用的海量日志采集、 聚合和传输的系统。
Flume NG是Cloudera提供的一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中。由原来的Flume OG到现在的Flume NG,进行了架构重构,并且现在NG版本完全不兼容原来的OG版本。经过架构重构后,Flume NG更像是一个轻量的小工具,非常简单,容易适应各种方式日志收集,并支持failover和负载均衡。
- 数据流模型:source-channel-sink,topology design
- 事务机制保证消息传递的可靠性
- 内置丰富插件,轻松与其他系统集成
- Java实现,系统框架好,模块分明,易于开发
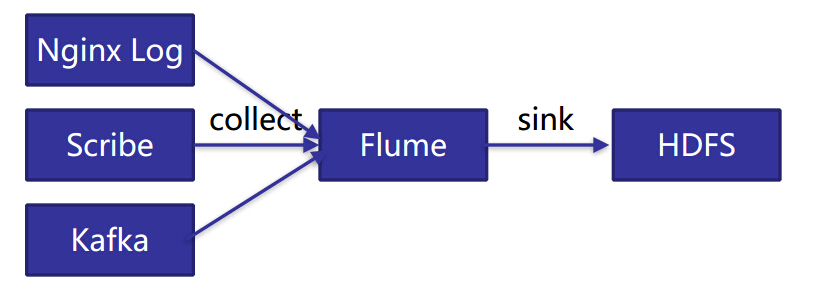
例:使用Flume将Nginx Log、Scribe、Kafka数据导入HDFS
Flume基本组件
- Event:消息的基本单位,由headers和body组成
- Agent:JVM进程,负责将外部来源产生的消息转发到外部的目的地
- Source:从外部来源读入event,并写入channel
- Channel:event暂存组件,source写入后,event将会一直保存,直到被sink成功消费。
- Sink:从channel读入event,并写入目的地
架构

Flume采用了分层架构:分别为agent,collector和storage。其中,agent和collector均由两部分组成:source和sink,source是数据来源,sink是数据去向。
Event:一个数据单元,带有一个可选的消息头
Flow:Event从源点到达目的点的迁移的抽象
Client:操作位于源点处的Event,将其发送到Flume Agent
Agent:一个独立的Flume进程,包含组件Source、Channel、Sink
Source:用来消费传递到该组件的Event
Channel:中转Event的一个临时存储,保存有Source组件传递过来的Event
Sink:从Channel中读取并移除Event,将Event传递到Flow Pipeline中的下一个Agent(如果有的话)
Flume 数据流
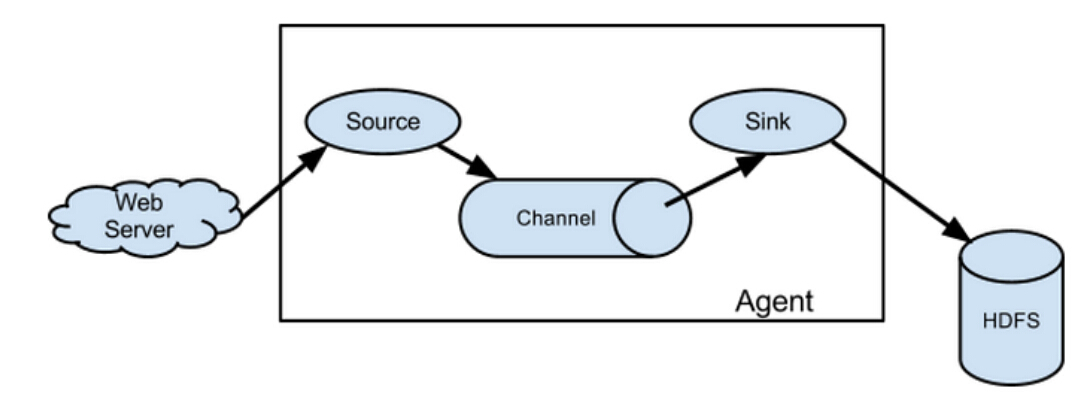
Flume 的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。
Flume 传输的数据的基本单位是 Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。Event 从 Source,流向 Channel,再到 Sink,本身为一个 byte 数组,并可携带 headers 信息。Event 代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。
Flume 运行的核心是 Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是source、channel、sink。通过这些组件,Event 可以从一个地方流向另一个地方。
source 可以接收外部源发送过来的数据。不同的 source,可以接受不同的数据格式。比如有目录池(spooling directory)数据源,可以监控指定文件夹中的新文件变化,如果目录中有文件产生,就会立刻读取其内容。
channel 是一个存储地,接收 source 的输出,直到有 sink 消费掉 channel 中的数据。channel 中的数据直到进入到下一个channel中或者进入终端才会被删除。当 sink 写入失败后,可以自动重启,不会造成数据丢失,因此很可靠。
sink 会消费 channel 中的数据,然后送给外部源或者其他 source。如数据可以写入到 HDFS 或者 HBase 中。
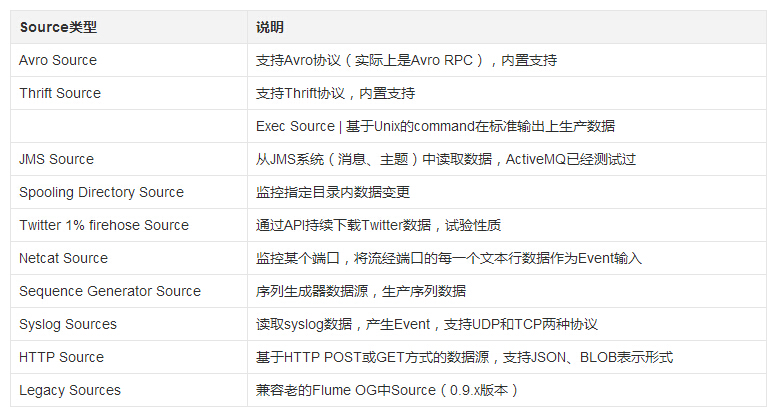
Flume Source 支持的类型
Flume Channel 支持的类型

# 启动Kafks集群监控软件java -cp KafkaOffsetMonitor-assembly-0.2.0.jar \com.quantifind.kafka.offsetapp.OffsetGetterWeb \--zk master \--port 8082 \--refresh 10.seconds \--retain 2.days &[root@slave01 flume-ng]# flume-ng agent -c /etc/flume-ng/conf -f /etc/flume-ng/conf/flume.propervities -Dflume.root.logger=INFO,console -n agent-1# 创建Flume项目,监控TCP端口收集日志# Flume文件示例[root@master conf]# pwd/usr/git-repo/bootcamp/flume-tutorial/test_flume/src/main/java/cn/chinahadoop/flume/conf[root@master conf]# cat example.conf# example.conf: A single-node Flume configuration# Name the components on this agenta1.sources = r1a1.sinks = k1a1.channels = c1# Describe/configure the sourcea1.sources.r1.type = netcata1.sources.r1.bind = localhosta1.sources.r1.port = 44444# Describe the sinka1.sinks.k1.type = logger# Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Bind the source and sink to the channela1.sources.r1.channels = c1a1.sinks.k1.channel = c1[root@slave01 conf]# pwd/usr/git-repo/bootcamp/flume-tutorial/test_flume/src/main/java/cn/chinahadoop/flume/conf[root@slave01 conf]# cp example.conf /etc/flume-ng/conf/# 启动flume-ng 注意--name a1要与example.conf中定义的agent名相同[root@slave01 ~]# flume-ng agent --conf conf --conf-file /etc/flume-ng/conf/example.conf --name a1 -Dflume.root.logger=INFO,console# 启动另一个客户端,查看4444端口已被监控[root@slave01 ~]# netstat -antp|grep 44444tcp 0 0 ::ffff:127.0.0.1:44444 :::* LISTEN 25220/java# 用telnet工具接入44444端口,发送数据[root@slave01 ~]# telnet localhost 44444Trying 127.0.0.1...Connected to localhost.Escape character is '^]'.hello flumeOKthis is a log......................OK# 在flume-ng console中可以查看收到的日志数据# 一条消息为一个Event16/01/29 14:27:14 INFO sink.LoggerSink: Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 0D hello flume. }16/01/29 14:28:39 INFO sink.LoggerSink: Event: { headers:{} body: 74 68 69 73 20 69 73 20 61 20 6C 6F 67 2E 2E 2E this is a log... }
Flume Interceptor
Interceptor:events在写入channel前,会先经过interceptor chain 进行处理,可以修改或丢弃event
在example.conf文件中加入以下拦截器配置
#interceptora1.sources.r1.interceptors = i1 i2 i3a1.sources.r1.interceptors.i1.type = timestampa1.sources.r1.interceptors.i2.type = hosta1.sources.r1.interceptors.i3.type = statica1.sources.r1.interceptors.i3.key = datacentera1.sources.r1.interceptors.i3.value = NEW_YORK
注:type可为alias或类名,参考InterceptorType.java
再次发送日志,查看日志收集情况
[root@slave01 conf]#flume-ng agent --conf conf --conf-file /etc/flume-ng/conf/flume_kafka.conf --n producer -Dflume.root.logger=INFO,console...test interceptor log.............OK...16/01/29 14:51:48 INFO sink.LoggerSink: Event: { headers:{timestamp=1454050308809, host=192.168.53.231, datacenter=NEW_YORK} body: 74 65 73 74 20 69 6E 74 65 72 63 65 70 74 6F 72 test interceptor }
内置Interceptor:timestamp、host、static、uuid、regex_filter、
regex_extractor
自定义Interceptor:实现Interceptor接口,参考TimestampInterceptor.java
# maven编译[root@master flume-ng]# scp /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/flume-ng/lib/test_flume-0.0.1-SNAPSHOT.jar root@slave01:/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/flume-ng/libtest_flume-0.0.1-SNAPSHOT.jar
flume分发(fan out)的两种策略
- Replication(defaults):Event发送到所有channel当中
- Multiplexing:Event根据配置规则选择发送到对应的channel当中
一个简单的Case:Flume --> Kafka --> HDFS
准备Kafka集群
Flume NG收集日志导入Kafka。
1)配置flume-kafka.properties
[root@master tmp]# ls flumeng-kafka-plugin.jarflumeng-kafka-plugin.jar[root@master conf]# cp /usr/application/tmp/flumeng-kafka-plugin.jar /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/flume-ng/lib/[root@slave01 data]# pwd/usr/git-repo/bootcamp/practise/sogouquery/data[root@slave01 conf]# vim flume-kafka.properties# agentproducer.sources = sources1producer.channels = channel1producer.sinks = sink1# flume spooldir方式,监控日志产生目录producer.sources.sources1.type = spooldirproducer.sources.sources1.channels = channel1producer.sources.sources1.spoolDir = /usr/git-repo/bootcamp/practise/sogouquery/data/generatedproducer.sources.sources1.fileHeader = true# 配置Flume的Sink数据流向,flume sink消息发送方,也即kafka producer消息生产者#producer.sinks.r.type = org.apache.flume.sink.kafka.KafkaSink#producer.sinks.r.type = cn.chinahadoop.flume.KafkaSink#producer.sinks.r.type = com.flume.flume2kafka.Flume2Kafkaproducer.sinks.sink1.type = org.apache.flume.plugins.KafkaSink#producer.sinks.r.metadata.broker.list=192.168.53.230:9092,192.168.53.231:9092,192.168.53.232:9092,192.168.53.233:9092producer.sinks.sink1.metadata.broker.list = 192.168.53.230:9092#producer.sinks.r.kafkaSink.brokerList=192.168.53.230:9092producer.sinks.sink1.partitioner.class = org.apache.flume.plugins.SinglePartitionproducer.sinks.sink1.serializer.class = kafka.serializer.StringEncoderproducer.sinks.sink1.key.serializer.class = kafka.serializer.StringEncoderproducer.sinks.sink1.request.required.acks = 0producer.sinks.sink1.max.message.size = 100000000producer.sinks.sink1.producer.type = asyncproducer.sinks.sink1.custom.encoding = UTF-8producer.sinks.sink1.custom.topic.name = topic1producer.sinks.sink1.channel = channel1# Channelproducer.channels.channel1.type = memoryproducer.channels.channel1.capacity = 1000# 启动Flume[root@slave01 conf]# flume-ng agent -n producer -c conf -f /etc/flume-ng/conf/flume-kafka.properties -Dflume.root.logger=INFO,console
由于使用了自定义Sink producer.sinks.sink1.type = org.apache.flume.plugins.KafkaSink,将下载的flumeng-kafka-plugin.jar放入/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/flume-ng/lib/目录,否则会提示找不到类的错误以致flume-ng启动失败。
2)准备日志生成脚本,每运行一次脚本将在/usr/git-repo/bootcamp/practise/sogouquery/data/generated目录中生成两个日志文件
# 开启另一个终端[root@slave01 log-generator]# pwd/usr/git-repo/bootcamp/practise/sogouquery/log-generator[root@slave01 log-generator]# vim log-generator.sh#!/bin/bashbin=`dirname "$0"`export bin=`cd "$bin"; pwd`export datadir=$bin/../dataexport data=$datadir/SogouQ.reducedexport generateddir=$datadir/generatedrm -rf $generateddir/*mkdir $generateddirecho genrateddir is $generateddiri=0surfix="20150601"while(($i<2))doecho generate the $i file.sleep 5echo "cat $data > $generateddir/SogouQ.reduced.$surfix"cat $data > $generateddir/SogouQ.reduced.$surfixsecond=`date -d "$surfix" +%s`second=$(($second+86400))surfix=`date -d @"$second" +%Y%m%d`i=$(($i+1))done
3)启动日志生成脚本,在Flume监控的终端中将看到日志已被收集并装入Kafka
[root@slave01 generated]# pwd/usr/git-repo/bootcamp/practise/sogouquery/data/generated[root@slave01 generated]# ../../log-generator/log-generator.shmkdir: cannot create directory `/usr/git-repo/bootcamp/practise/sogouquery/log-generator/../data/generated': File existsgenrateddir is /usr/git-repo/bootcamp/practise/sogouquery/log-generator/../data/generatedgenerate the 0 file.cat /usr/git-repo/bootcamp/practise/sogouquery/log-generator/../data/SogouQ.reduced > /usr/git-repo/bootcamp/practise/sogouquery/log-generator/../data/generated/SogouQ.reduced.20150601generate the 1 file.cat /usr/git-repo/bootcamp/practise/sogouquery/log-generator/../data/SogouQ.reduced > /usr/git-repo/bootcamp/practise/sogouquery/log-generator/../data/generated/SogouQ.reduced.20150602
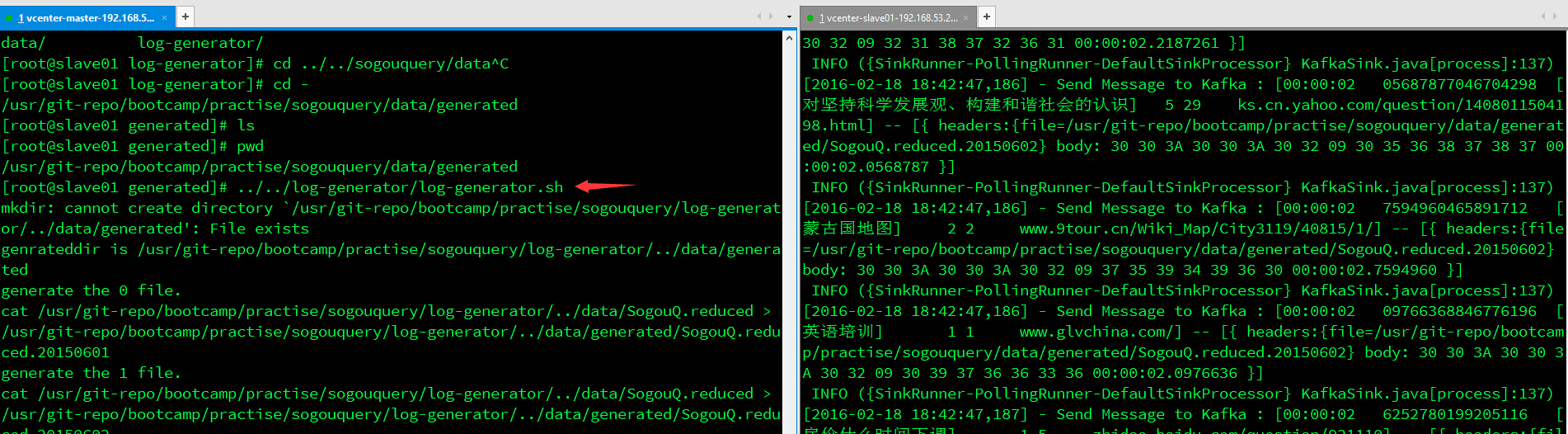
备注:演示环境为一个Flume的Sink收集日志并装入一个Kafka的Producer,不难设想在集群环境中也是同样道理,Kafka会根据Flume中配置的producer.sinks.sink1.custom.topic.name = topic1来区分消息。
4)另开启一个终端,用Kafka工具消费Topic
# 查看Topic详细信息[root@slave01 kafka_2.10-0.8.2.0]# /usr/kafka_2.10-0.8.2.0/bin/kafka-topics.sh --describe --zookeeper master:2181 --topic topicTopic:topic PartitionCount:1 ReplicationFactor:1 Configs:Topic: topic Partition: 0 Leader: 1 Replicas: 1 Isr: 1[root@slave01 kafka_2.10-0.8.2.0]# /usr/kafka_2.10-0.8.2.0/bin/kafka-console-consumer.sh --zookeeper master:2181 --topic topicthis is a topic......[root@slave01 generated]# pwd/usr/git-repo/bootcamp/practise/sogouquery/data/generated[root@slave01 generated]# lsSogouQ.reduced.20150601.COMPLETED test.COMPLETEDSogouQ.reduced.20150602.COMPLETED
可以看到,只要在Flume监控的目录下新建一个文件,内容都会邮Flume收集并导入Kafka,最终在Console消费。
Flume中收集日志
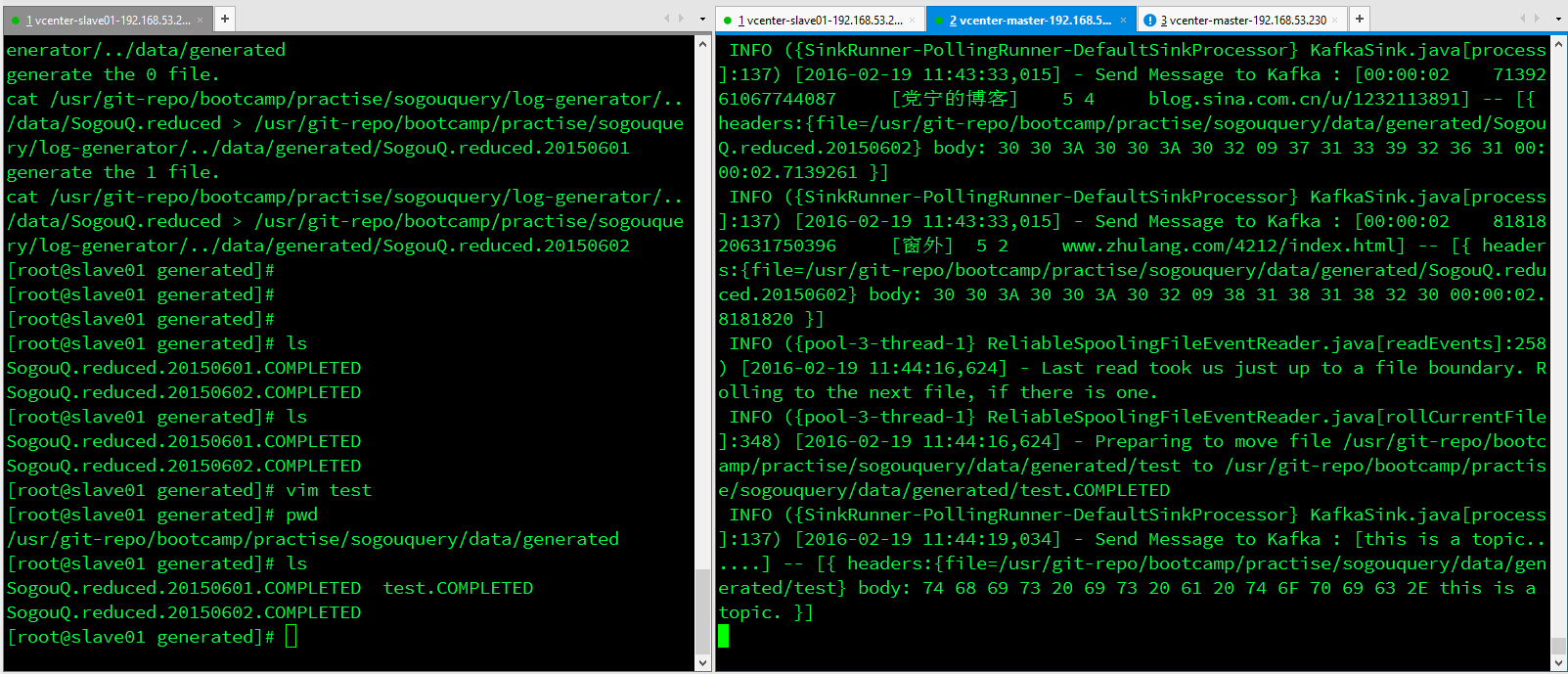
Kafka Console Consumer消费日志
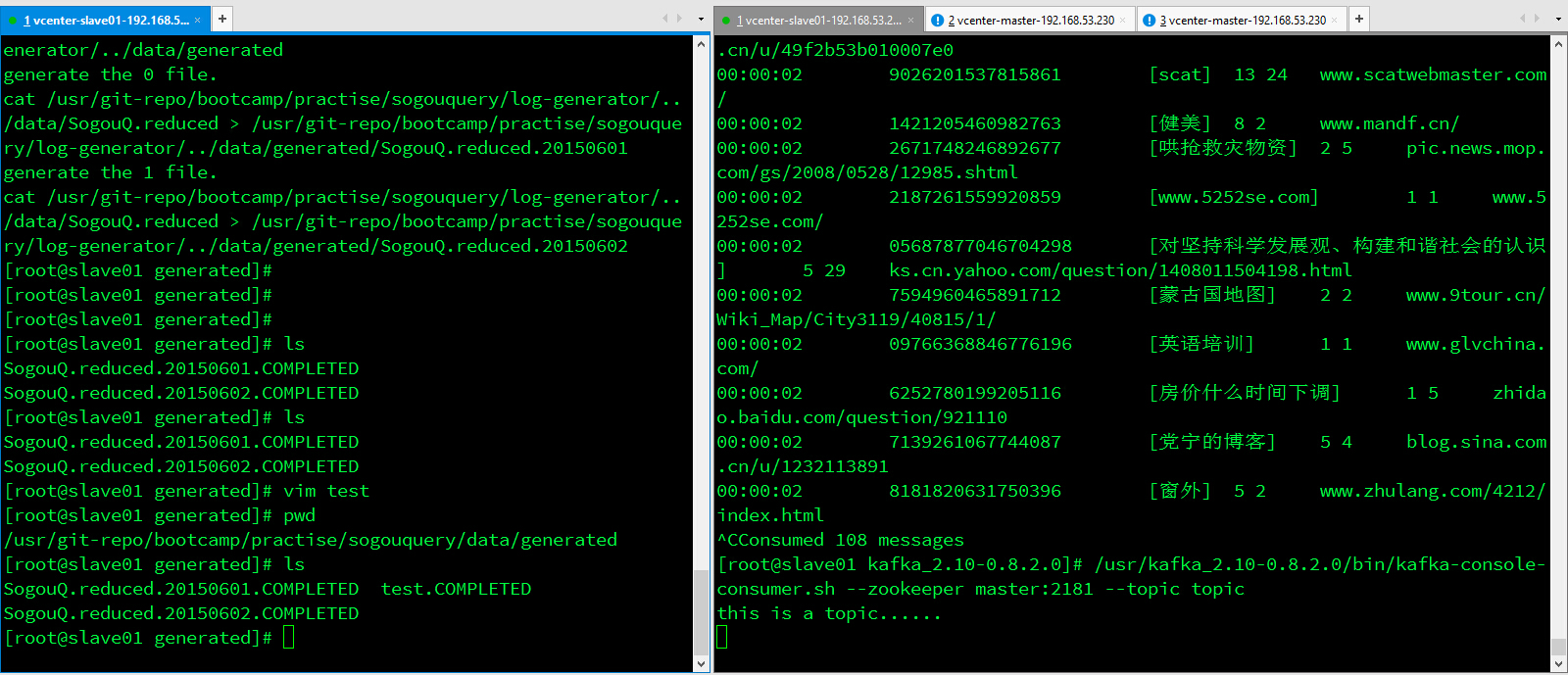
5)使用Kafka API消费Topic
代码结构
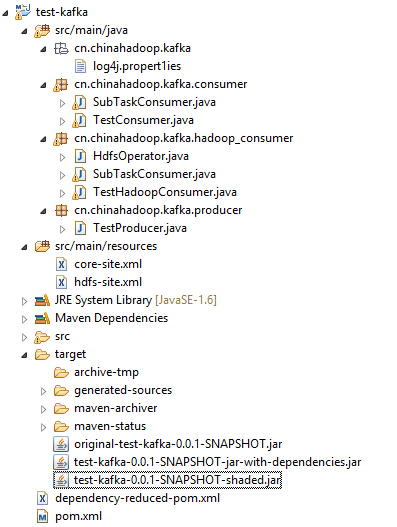
参数介绍
- zookeeper.connect:存储消费一个特定的主题和分区信息的偏移量
- group.id:consumer group由消费者组成的组
- zookeeper.session.timeout:毫秒为单位,kafka等待zookeeper的请求超时时间
- auto.commit.interval.ms:设置间隔时间,更新在zookeeper上的topic已经消费的偏移量
测试Consumer类
package cn.chinahadoop.kafka.consumer;import kafka.consumer.ConsumerConfig;import kafka.consumer.KafkaStream;import kafka.javaapi.consumer.ConsumerConnector;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.Properties;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;public class TestConsumer {private final ConsumerConnector consumer;private final String topic;private ExecutorService executor;public TestConsumer(String a_zookeeper, String a_groupId, String a_topic) {consumer = kafka.consumer.Consumer.createJavaConsumerConnector(createConsumerConfig(a_zookeeper, a_groupId));this.topic = a_topic;}public void shutdown() {if (consumer != null)consumer.shutdown();if (executor != null)executor.shutdown();}// 调用run方法,在内部启用子进程public void run(int a_numThreads) {Map<String, Integer> topicCountMap = new HashMap<String, Integer>();topicCountMap.put(topic, new Integer(a_numThreads));Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);List<KafkaStream<byte[], byte[]>> streams = consumerMap.get(topic);// 启动所有线程executor = Executors.newFixedThreadPool(a_numThreads);// 开始消费消息int threadNumber = 0;for (final KafkaStream stream : streams) {executor.submit(new SubTaskConsumer(stream, threadNumber));threadNumber++;}}// 准备配置文件,配置Zookeeperprivate static ConsumerConfig createConsumerConfig(String a_zookeeper, String a_groupId) {Properties props = new Properties();props.put("zookeeper.connect", a_zookeeper);props.put("group.id", a_groupId);props.put("zookeeper.session.timeout.ms", "60000");props.put("auto.commit.interval.ms", "1000");props.put("auto.offset.reset", "smallest");return new ConsumerConfig(props);}public static void main(String[] args) throws Exception {String zooKeeper = "192.168.53.230:2181";String topic = "topic";String groupId = "group";int threads = Integer.parseInt("1");TestConsumer example = new TestConsumer(zooKeeper, groupId, topic);example.run(threads);}}
执行的子进程
package cn.chinahadoop.kafka.consumer;import kafka.consumer.ConsumerIterator;import kafka.consumer.KafkaStream;// 子进程负责遍历数据public class SubTaskConsumer implements Runnable {private KafkaStream m_stream;private int m_threadNumber;public SubTaskConsumer(KafkaStream a_stream, int a_threadNumber) {m_threadNumber = a_threadNumber;m_stream = a_stream;}@Overridepublic void run() {ConsumerIterator<byte[], byte[]> it = m_stream.iterator();while (it.hasNext()){byte[] by = it.next().message();System.out.println("Thread " + m_threadNumber + ": " + new String(by) +"-id:"+Thread.currentThread().getId());}System.out.println("Shutting down Thread: " + m_threadNumber);}}
# 执行准备好的程序,也可看到消费的Topic[root@master]# java -cp test-kafka-0.0.1-SNAPSHOT.jar cn.chinahadoop.kafka.consumer.TestConsumerlog4j:WARN No appenders could be found for logger (kafka.utils.VerifiableProplog4j:WARN Please initialize the log4j system properly.[2016-02-19 14:25:24,600] INFO Closing socket connection to /192.168.53.230. cessor)Thread 0: akdjsfwqer-id:18Thread 0: -id:18
6)使用Hadoop Consumer,将Kafka消息导出HDFS
package cn.chinahadoop.kafka.hadoop_consumer;import java.io.IOException;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.Properties;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import kafka.consumer.ConsumerConfig;import kafka.consumer.KafkaStream;import kafka.javaapi.consumer.ConsumerConnector;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.hdfs.HdfsConfiguration;/*** 初始化HDFS文件对象* @author sasaki**/public class TestHadoopConsumer {private final ConsumerConnector consumer;private final String topic;private ExecutorService executor;private FileSystem hdfs;public TestHadoopConsumer(String a_zookeeper, String a_groupId, String a_topic) {consumer = kafka.consumer.Consumer.createJavaConsumerConnector(createConsumerConfig(a_zookeeper, a_groupId));this.topic = a_topic;try {hdfs = FileSystem.get(new HdfsConfiguration());} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}public void shutdown() {if (consumer != null)consumer.shutdown();if (executor != null)executor.shutdown();}public void run(int a_numThreads) {Map<String, Integer> topicCountMap = new HashMap<String, Integer>();topicCountMap.put(topic, new Integer(a_numThreads));Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);List<KafkaStream<byte[], byte[]>> streams = consumerMap.get(topic);// 启动所有线程executor = Executors.newFixedThreadPool(a_numThreads);// 开始消费消息int threadNumber = 0;for (final KafkaStream stream : streams) {executor.submit(new SubTaskConsumer(stream, threadNumber, hdfs));threadNumber++;}}private static ConsumerConfig createConsumerConfig(String a_zookeeper, String a_groupId) {Properties props = new Properties();props.put("zookeeper.connect", a_zookeeper);props.put("group.id", a_groupId);props.put("zookeeper.session.timeout.ms", "60000");props.put("zookeeper.sync.time.ms", "2000");props.put("auto.commit.interval.ms", "1000");props.put("auto.offset.reset", "smallest");return new ConsumerConfig(props);}public static void main(String[] args) throws Exception {String zooKeeper = "192.168.53.230:2181";String topic = "topic";String groupId = "group";int threads = Integer.parseInt("1");TestHadoopConsumer example = new TestHadoopConsumer(zooKeeper, groupId, topic);example.run(threads);}}
package cn.chinahadoop.kafka.hadoop_consumer;import java.io.IOException;import org.apache.hadoop.fs.FSDataOutputStream;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import kafka.consumer.ConsumerIterator;import kafka.consumer.KafkaStream;public class SubTaskConsumer implements Runnable {private KafkaStream m_stream;private int m_threadNumber;FileSystem hdfs;public SubTaskConsumer(KafkaStream a_stream, int a_threadNumber,FileSystem fs) {m_threadNumber = a_threadNumber;m_stream = a_stream;hdfs = fs;System.out.println("come in 11111111");}/*** 启动子进程读取遍历数据*/@Overridepublic void run() {Path path = new Path("/user/root/kafka/consumer.txt");try {FSDataOutputStream dos = hdfs.create(path);ConsumerIterator<byte[], byte[]> it = m_stream.iterator();while (it.hasNext()){byte[] by = it.next().message();dos.write(by);System.out.println("Thread " + m_threadNumber + ": " + new String(by) +"-id:"+Thread.currentThread().getId());}System.out.println("Shutting down Thread: " + m_threadNumber);dos.flush();dos.close();hdfs.close();} catch (IOException e) {e.printStackTrace();}}}
[root@master tmp]# java -cp test-kafka-0.0.1-SNAPSHOT.jar cn.chinahadoop.kafka.hadoop_consumer.TestHadoopConsumer
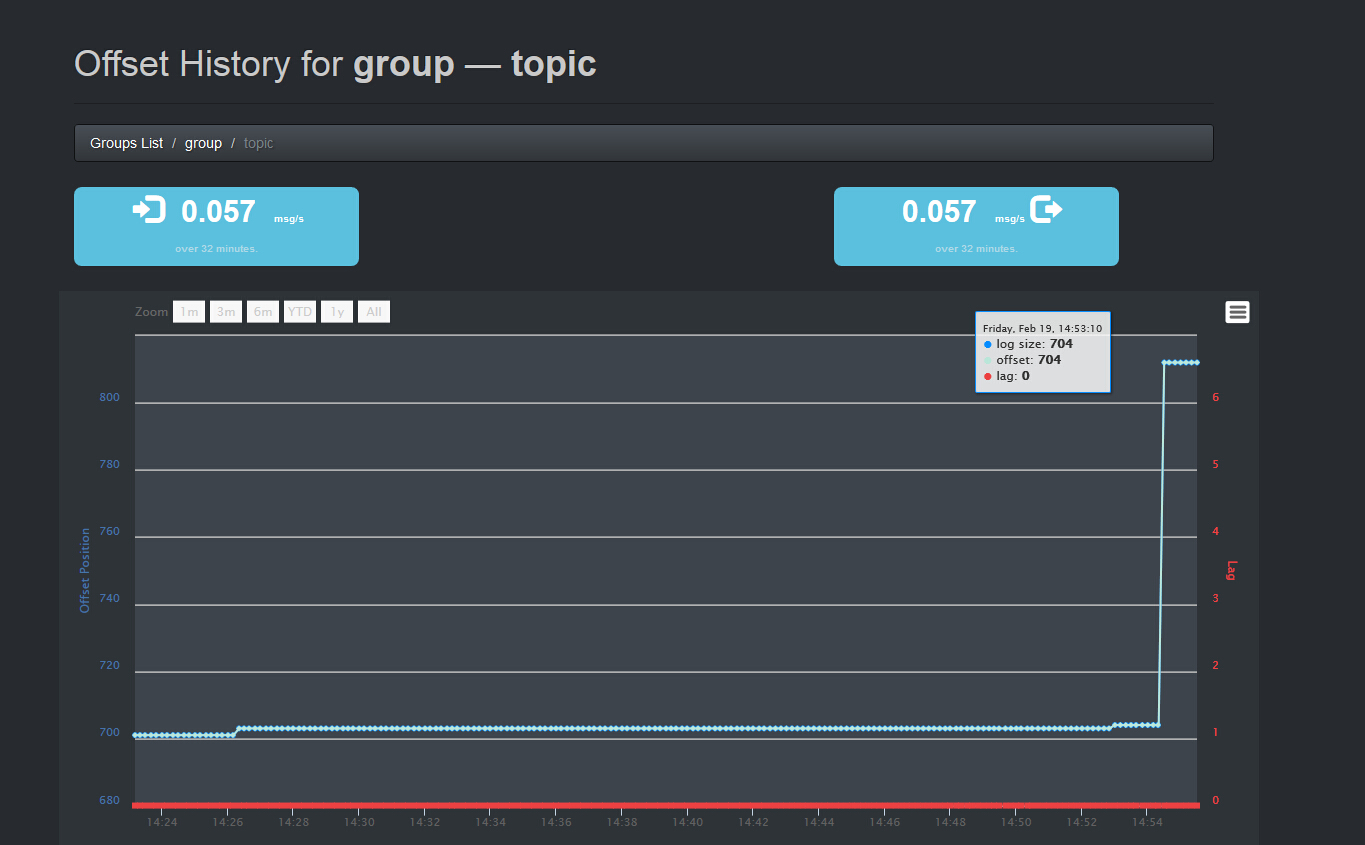
在Kafka监控页面中查看消息
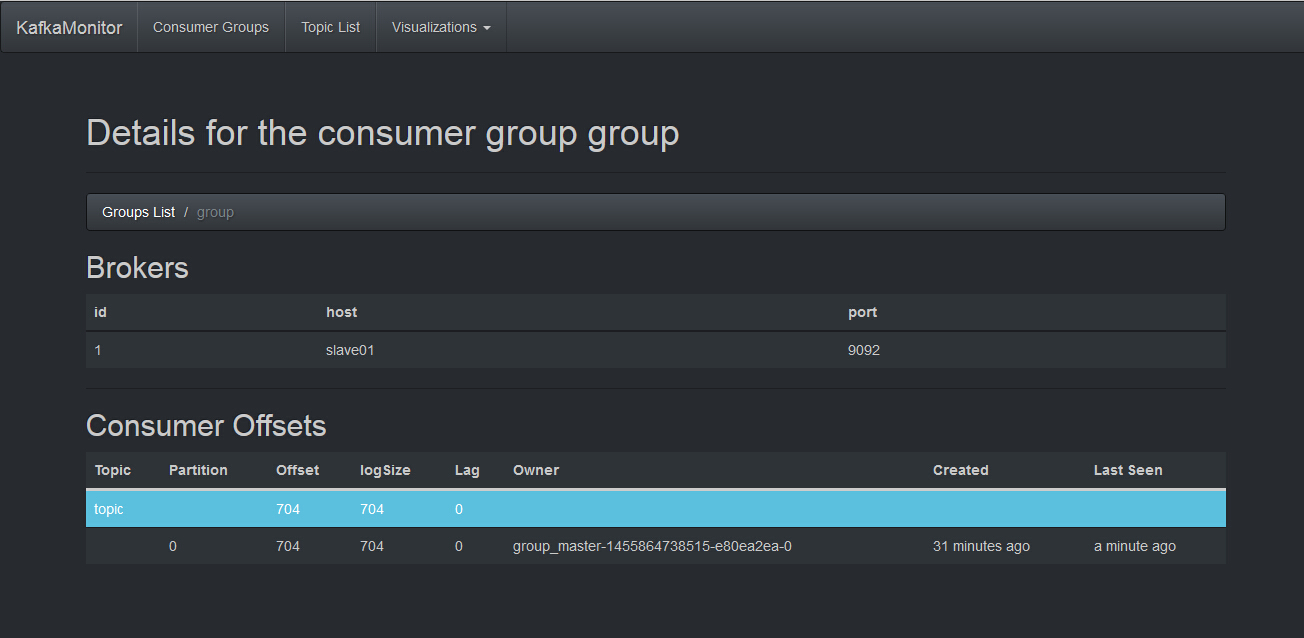
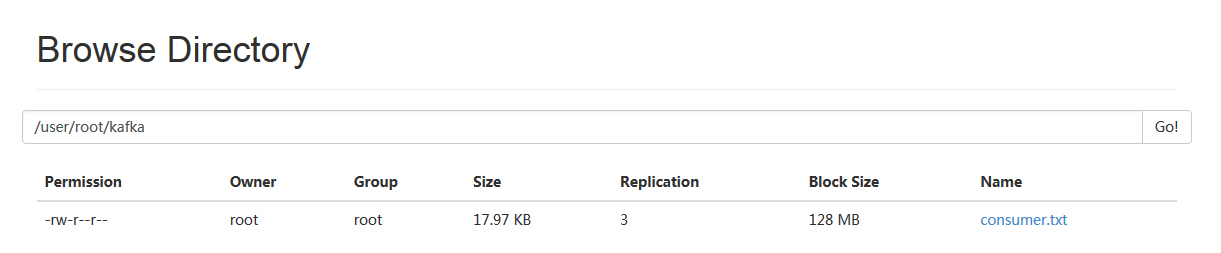
HDFS中目标文件已生成
# 查看HDFS中最终文件[root@slave01 kafka_2.10-0.8.2.0]# hadoop fs -tail /user/root/kafka/consumer.txtd=9621&star=100:00:01 7812322229275207 [link:jejie.cn] 1 3 jejie.cn/00:00:01 9998054335177979 [sj+c中文首站] 2 9 chinasj.ifensi.com/archiver/?tid-5992.html00:00:02 7332328301924345 [女犯鞭刑] 6 8 blog.sina.com.cn/u/49f2b53b010007e000:00:02 9026201537815861 [scat] 13 24 www.scatwebmaster.com/00:00:02 1421205460982763 [健美] 8 2 www.mandf.cn/00:00:02 2671748246892677 [哄抢救灾物资] 2 5 pic.news.mop.com/gs/2008/0528/12985.shtml00:00:02
注意:即使程序正确无误,Kafka也可能不会立即将消息写入HDFS,当消息达到一定量或者关闭程序时才将消息写入文件。
其他收集与参考链接
flume和kafka整合
1.下载flume-kafka-plus: https://github.com/beyondj2ee/flumeng-kafka-plugin
2.提取插件中的flume-conf.properties文件
修改该文件:#source section
producer.sources.s.type = exec
producer.sources.s.command = tail -f -n+1 /mnt/hgfs/vmshare/test.log
producer.sources.s.channels = c
修改所有topic的值改为test
将改后的配置文件放进flume/conf目录下
Kafka实战-Flume到Kafka http://www.open-open.com/lib/view/open1435884136903.html
高可用Hadoop平台-Flume NG实战图解篇 http://www.cnblogs.com/smartloli/p/4468708.html
http://www.cnblogs.com/xfly/p/3825804.html
