@sasaki
2016-04-22T03:25:14.000000Z
字数 5594
阅读 4108
Hive——数据分析系统
BigData
版本控制
@Title Hive——数据分析系统@Version v1.0@Timestamp 2016-01-20 18:08@Author Nicholas@Mail redskirt@outlook.com
一、Hive背景及应用场景
Hive简介
- Hive由facebook开源,最初用于解决海量结构化的日志数据统计问题,ETL(Extraction-Transformation-Loading)工具;
- 构建在Hadoop之上的数据仓库,数据计算使用MR,数据存储使用HDFS;
- Hive 定义了一种类 SQL 查询语言——HQL,类似SQL, 但不完全相同;
- 通常用于进行离线数据处理(采用MapReduce);
- 可认为是一个HQL->MR的语言翻译器。
Hive典型应用场景
- 日志分析
|- 统计网站一个时间段内的pv、uv
|- 多维度数据分析
|- 大部分互联网公司使用Hive进行日志分析,包括百度、淘宝等 - 其他场景
|- 海量结构化数据离线分析
|- 低成本进行数据分析(不直接编写MR)
- 日志分析
Hive的特性
- 简单,容易上手
|- 提供了类SQL查询语言HQL; - 为超大数据集设计的计算/扩展能力
|- MR作为计算引擎, HDFS作为存储系统 - 统一的元数据管理(HCalalog)
|- 可与Pig、 Presto等共享
- 简单,容易上手
Hive的缺陷
- Hive的HQL表达的能力有限
|- 迭代式算法无法表达
|- 有些复杂运算用HQL不易表达 - Hive效率较低
|- Hive自动生成MapReduce作业,通常不够智能;
|- HQL调优困难,粒度较粗
|- 可控性差
- Hive的HQL表达的能力有限
二、Hive基本架构
Hive基本架构
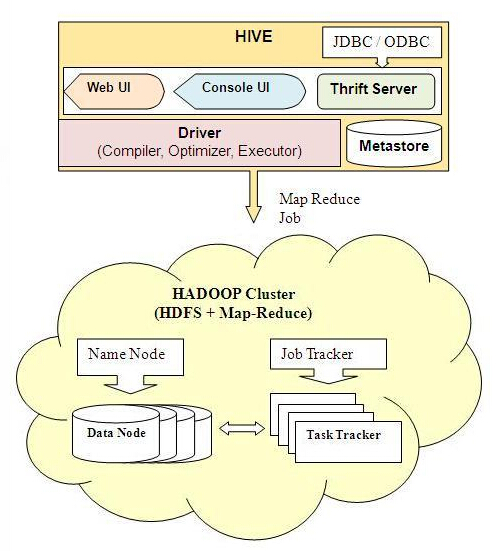
Hive主要模块
- 用户接口
|- 包括CLI,JDBC/ODBC,WebUI - 元数据存储(metastore)
|- 默认存储在自带的数据库derby中,线上使用时一般换为MySQL - 驱动器(Driver)
|- 解释器、编译器、优化器、执行器 - Hadoop
|- 用MapReduce进行计算,用HDFS进行存储
- 用户接口
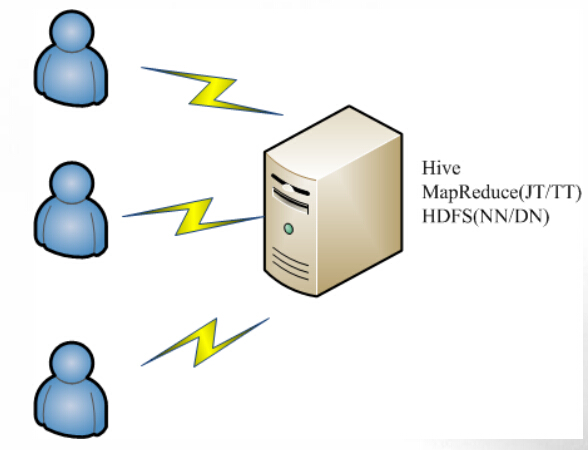
部署Hive实验环境(单机)
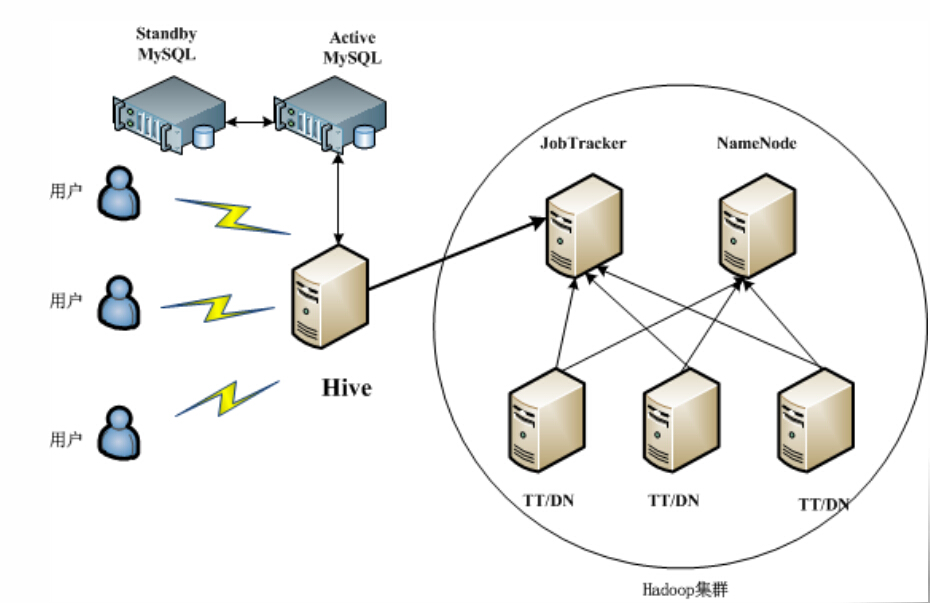
部署Hive生产环境(集群)
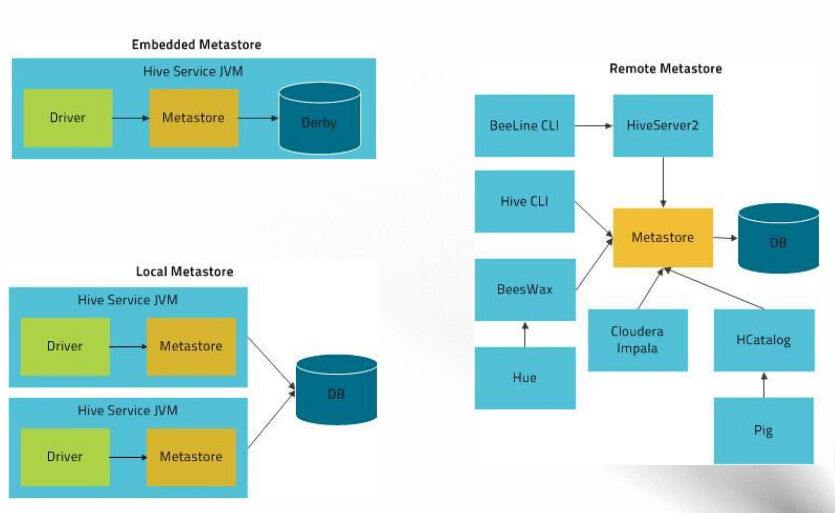
部署Hive metastore服务
三、Hive使用方式
- 命令行模式
${HIVE_HOME}/bin/hive --help Hive外部资源
- 外部资源:HQL运行时需要的jar包、二进制文件、文本文件、压缩文件等,外部资源需分发到集群的各个节点上使用
- 三种外部资源:
FILE:普通文件,Hadoop不会进行任何处理
JAR:jar包,Hadoop自动将其加入CLASSPATH中
ARCHIVE:归档文件,Hadoop可识别“.tgz”、“.tar.gz”、“.zip”等结尾的文件,并自动解压 - 三种操作
ADD { FILE[S] | JAR[S] | ARCHIVE[S] } <filepath1> [<filepath2>]*LIST { FILE[S] | JAR[S] | ARCHIVE[S] } [<filepath1> <filepath2> ..]DELETE { FILE[S] | JAR[S] | ARCHIVE[S] } [<filepath1> <filepath2> ..]
Hive客户端程序
方法1:提供JDBC/ODBC访问方式
方法2:采用开源软件Thrift实现C/S模型,支持任何语言编写客户端程序
四、HQL查询语句
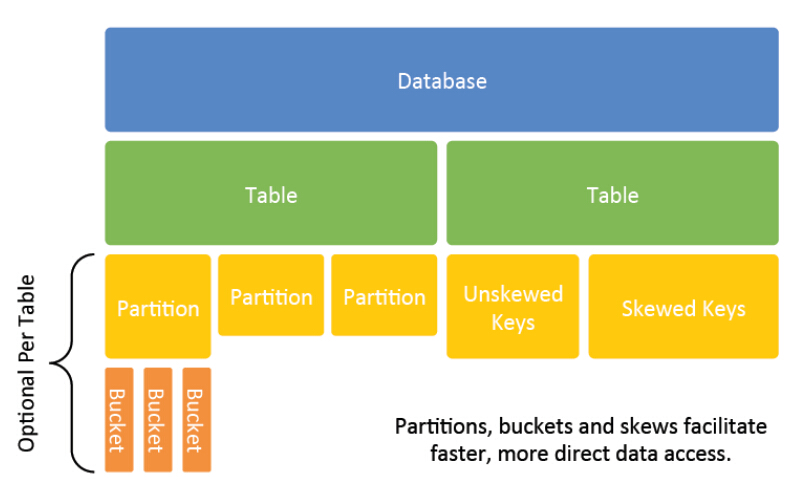
数据模型
数据类型

Hive特有的数据类型

数据定义语句( DDL)
- Create/Drop/Alter Database
- Create/Drop/Truncate Table
- Alter Table/Partition/Column
- Create/Drop/Alter View
- Create/Drop/Alter Index
- Create/Drop Function
- Create/Drop/Grant/Revoke Roles and Privileges
- Show
- Describe
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name(col_name data_type, ...)[PARTITIONED BY (col_name data_type, ...)][CLUSTERED BY (col_name, col_name, ...) [SORTED BY(col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS][SKEWED BY (col_name, col_name, ...)][ [ROW FORMAT row_format] [STORED AS file_format] ][LOCATION hdfs_path]
内部表与外部表示例
create external table sogouqueryfish(time varchar(8),userid varchar(30),query string,pagerank int,clickrank int,site string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'location 'hdfs://master:8020/data/SogouQtmp';
create table sogouqueryfish(time varchar(8),userid varchar(30),query string,pagerank int,clickrank int,site string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'location 'hdfs://master:8020/data/SogouQtmp';drop table sogouqueryfish;
Hive创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
# 在HDFS中准备数据[root@master tmp]# hadoop fs -tail /user/root/sogo/SogouQ.reduced# 启动Hive CLI[root@master hive]# hive16/01/21 17:17:08 WARN conf.HiveConf: DEPRECATED: Configuration property hive.metastore.local no longer has any effect. Make sure to provide a valid value for hive.metastore.uris if you are connecting to a remote metastore.Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/jars/hive-common-0.13.1-cdh5.3.8.jar!/hive-log4j.propertieshive> show tables;OKTime taken: 0.111 seconds# 创建外部表示例# location后面跟的是目录,不是文件,hive会把整个目录下的文件都加载到表中hive> create external table test_sogo(time varchar(8), userid varchar(30), query string, pagerank int, clickrank int, site string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location 'hdfs://master:8020/user/root/sogo/';OKTime taken: 0.065 secondshive> show tables;OKtest_sogoTime taken: 0.022 seconds, Fetched: 1 row(s)# 创建内部表示例hive> create table test_sogo_(time varchar(8), userid varchar(30), query string, pagerank int, clickrank int, site string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location 'hdfs://master:8020/user/root/sogo/';OKTime taken: 0.059 seconds# 分别进行删除hive> show tables; OKtest_sogotest_sogo_Time taken: 0.023 seconds, Fetched: 2 row(s)hive> drop table test_sogo;OKTime taken: 0.098 secondshive> drop table test_sogo_;OKTime taken: 0.132 secondshive> show tables;OKTime taken: 0.023 seconds
Partitions
传统数据库常常使用“天表”、“月表”、“年表”的方式组织数据库以避免单表过大导致的性能问题。
Hive使用partitions概念解决该问题,比如,相较于“天表”,Hive每天创建一个新的partition。当使用partitions时,可以在不扫描整个表的情况下操作必要的数据。
CREATE TABLE sogouqueryfish(time varchar(8), userid varchar(30), query string, pagerank int,clickrank int, site string) PARTITIONED BY (day STRING) ROW FORMAT DELIMITED FIELDSTERMINATED BY '\t';LOAD DATA INPATH '/data/SogouQ/SogouQ.sample' INTO TABLE sogouqueryfishPARTITION(day='2014-01-01');
将会在Hdfs 中 page_view文件夹中创建按日期命名的文件夹
../sogouqueryfish/day=2014-01-01/..../sogouqueryfish/day=2014-01-02/....../sogouqueryfish/day=2014-01-06/..
注意事项:
- 只对离散字段建partition
- 尽管在表中创建分区有很多好处,但过度使用可能带来害处。
- Hive为一张表创建一个分区后,必须为每一个分区维护额外的元数据来重定向查询。
- 最好在完全理解数据的查询类型后,再选择合适的列进行分区,这非常重要。因为分区有可能在提高部分查询的性能的同时降低其他查询的性能。
Bucket
Bucket类似于Partition。 Buckets根据查询常用的关键字的哈希值将数据分不到到用户自定义集合中。当需要做分区的列为连续值时,适合使用Bucket。
假设,在user_id列上执行查询 ,在user_id列上使用buckets。
CREATE TABLE page_views_old(user_id INT, session_id INT, url STRING) PARTITIONED BY(day INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';LOAD DATA INPATH '/data/PageView/pageview.sample' INTO TABLE page_views_old PARTITION(day=1);set hive.enforce.bucketing = true;CREATE TABLE page_views(user_id INT, session_id INT, url STRING) PARTITIONED BY(day INT) clustered by(user_id) into 10 buckets ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';from page_views_old insert overwrite table page_views partition(day=1) select user_id,session_id,url where day=1;
通过以上语句,表中的数据将会根据user_id的哈希数分成10个buckets。因此,当查询确定的user_id时,程序首先计算user_id的哈希数然后只查找对应的bucket。
进一步理解bucket的细节。假定以下是要向page_view表插入的数据:
(user_id, session_id, url)(1, 1111, http://example.com/page/1)(2, 354, http://example.com/page/1)(22, 76764, http://example.com/page/1)(21, 74747, http://example.com/page/1)..(63, 64646, http://example.com/page/1)
假设,哈希值的算法是对user_id的值对10取模。然后在加载数据时,程序会计算每个user_id的哈希值,并根据哈希排列每条记录。
对于第一条记彔,根据user_id= 1计算哈希值1 modulus 10 = 1
对于user_id=22的记彔,其哈希值是2 (22 modulus 10 = 2)
对于user_id=63的记彔,其哈希值是3 (63 modulus 10 = 3)

因此所有的数据将会被分配到名为0-9的bucket中,当检索user_id=89的数据时,程序只会到Bucket 9查找。这样就丌会为了查找这个id而扫描整个表,节省了很多时间。
