@sasaki
2016-01-13T07:43:23.000000Z
字数 4826
阅读 3961
流式计算与Spark Streaming
BigData Spark
版本控制
@Title 流式计算与Spark Streaming@Version v1.0@Timestamp 2016-01-08 12:17@Author Nicholas@Mail redskirt@outlook.com
前言
Spark是一个类似于MapReduce的分布式计算框架,其核心是弹性分布式数据集,提供了比MapReduce更丰富的模型,可以在快速在内存中对数据集进行多次迭代,以支持复杂的数据挖掘算法和图形计算算法。
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
Spark Streaming的优势:
- 能运行在100+的结点上,并达到秒级延迟。
- 使用基于内存的Spark作为执行引擎,具有高效和容错的特性。
- 能集成Spark的批处理和交互查询。
- 为实现复杂的算法提供和批处理类似的简单接口。
一、流式计算的语义
- At-most-once:每条记录最多只能被处理一次
- At-least-once:每条记录最少要被处理一次
- Exactly-once:每条记录有且仅被处理一次
二、技术选型
- Spark Streaming
- Storm
- Heron
Samza
多种技术都对Kafka技术极好,Kafka几乎满足消息队列所有需求。
三、Overview
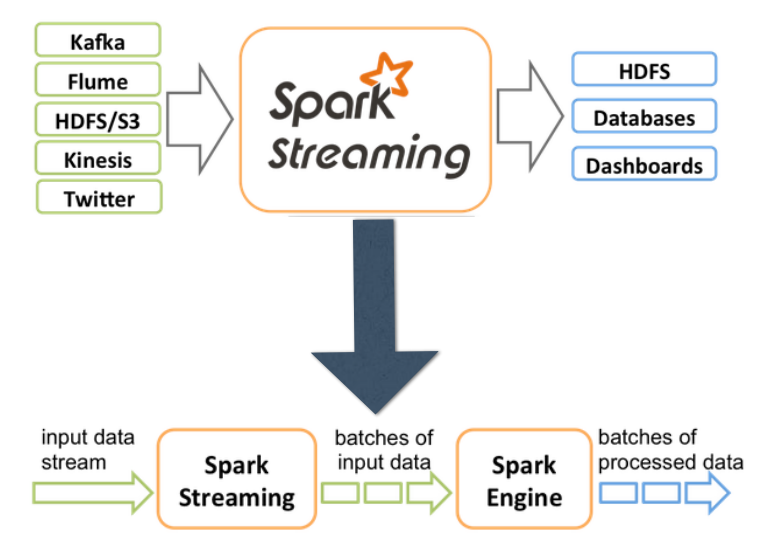
Spark Streaming引擎将数据流切分为batch,每一小块为一个RDD。Spark Streaming本质为Micro Batch(微量的批处理)。
核心概念:DStream(源源不断的消息队列)
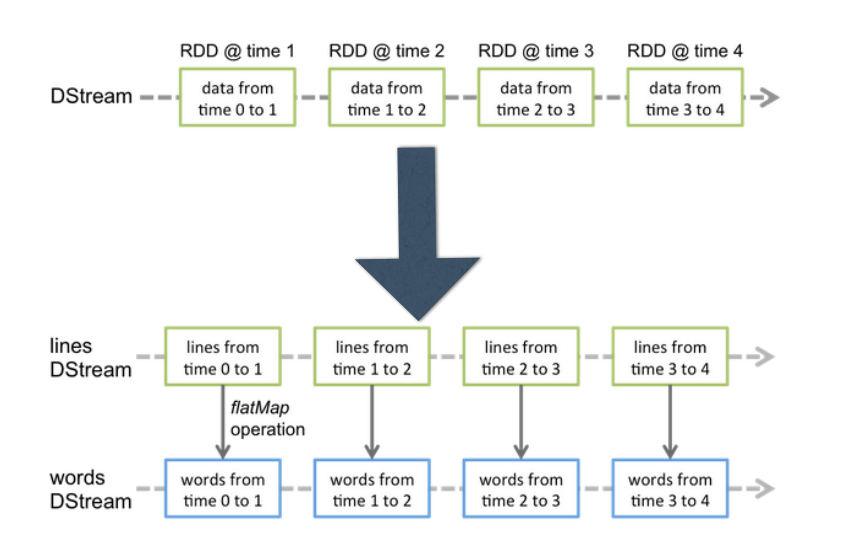
- 连续的流数据
- 可以基于数据源创建
- 可以由另一个DStream生成
- 一系列的RDD
- 将流式计算分解成一系列确定并且较小的批处理作业
- 将失败或者执行较慢的任务在其它节点上并行执行
较强的容错能力(基于Lineage)
DStream会被切割成很多小的RDD,Spark的计算都是基于RDD的。
Spark Streaming入口:StreamingContext
- 只要ctx启动以后,无法在此ctx上新增计算
- ctx被关闭后,无法再被restart
- 同一时间在一个JVM中只能存在一个ctx实例
数据源:
- Kafka
- Flume
- ZeroMQ
- MQTT
- TCP sockets
- Akka actor
- HDFS
- 自定义
Spark Streaming操作:
Transformation-无状态
和Spark语义一致。
reduceByKey, map, flatMap, filter, count, reduce, etc groupByKey, sortByKey, join, etcTransformation-带状态
- updateStateByKey(很常用)
- window操作
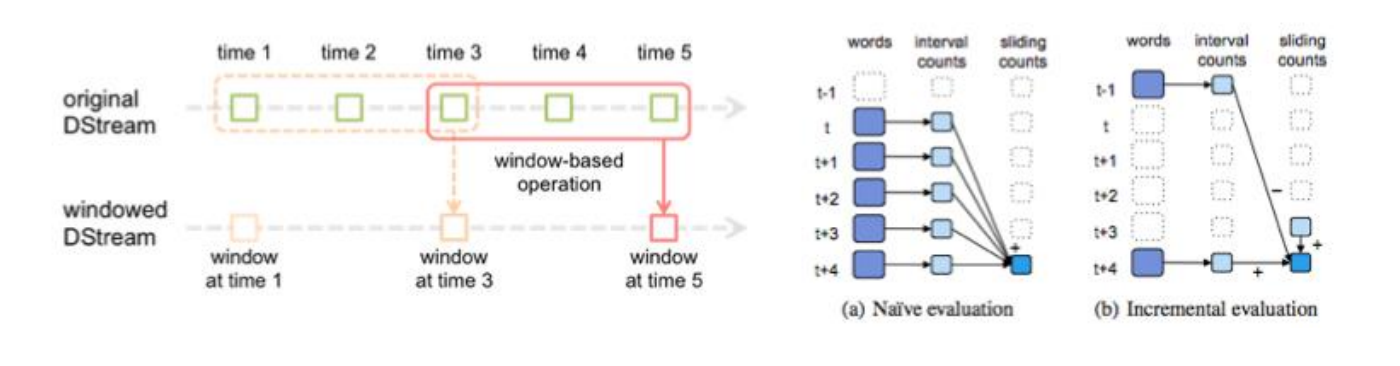
window, countByWindow, reduceByWindow, countByValueAndWindow, reduceByKeyAndWindow
离散数据流(DStream)
离散数据流(DStream)作为Spark Streaming中的一个基本抽象,代表一个数据流,这个数据流即可以从外部获得,也可以通过对输入流的转换获得。
DStream是通过一级时间序列上的连续的RDD来表示的,每一个RDD都包含了特定时间间隔内的数据流。
DStream的操作:
- 转换操作。将一个DStream转换为另一个DStream,并不会提交作业;
- 基于窗口的转换操作。将一些转换操作与窗口操作合并;
输出操作。
Spark的本质是对RDD进行操作,对DStream的操作最终会被映射到内部的RDD上。
print
- foreachRDD
- saveAsObjectFiles
- saveAsTextFiles
- saveAsHadoopFiles
应用场景:
- 处理网络数据源
- 指定目录处理(本地或HDFS)
- Window操作
- Kafka数据源
构建一个Spark Streaming程序主要分为以下步骤:
1)创建StreamingContext对象
val ssc = new StreamingContext(args(0), "NetworkWordCount", Seconds(1))
2)创建InputStream
val lines = ssc.socketTextStream(args(1), args(2).toInt)
SparkStreaming支持多种不同的数据源,包括socketTextStream、kafkaStream、flumeStream、fileStream、networkStream等。
3)操作DStream
4)启动Spark Streaming
时间和窗口
批处理间隔(batch duration)
Spark Streaming中处理数据的单位是一批而非一条,而数据采集是逐条进行的。Spark Streaming系统会设置间隔使得数据汇总到一定的量后再一并操作,这个间隔为批处理间隔。
批处理间隔决定了Spark Streaming提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能。滑动间隔(slide duration)和窗口间隔(window duration)
默认情况下滑动间隔被设置为与批处理间隔相同,而窗口间隔可以设置为更大的时间窗口。
滑动间隔和窗口间隔的设置必须是批处理的整数倍。
例1. 运行NetwordCount例子
Spark example目录中包含多种Streaming测试例子,取其中NetworkWordCount拷贝内容到自己的Scala项目中打成jar包。
[root@master streaming]# pwd /usr/application/tmp/spark-1.3.0/dist/examples/src/main/scala/org/apache/spark/examples/streaming[root@master streaming]# cat NetworkWordCount.scalapackage org.apache.spark.examples.streamingimport org.apache.spark.SparkConfimport org.apache.spark.streaming.{Seconds, StreamingContext}import org.apache.spark.storage.StorageLevelobject NetworkWordCount {def main(args: Array[String]) {if (args.length < 3) {System.err.println("Usage: NetworkWordCount <hostname> <port> <seconds>")System.exit(1)}// StreamingExamples.setStreamingLogLevels()val sparkConf = new SparkConf().setAppName("NetworkWordCount")val ssc = new StreamingContext(sparkConf, Seconds(args(3).toInt))val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)val words = lines.flatMap(_.split(" "))val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)wordCounts.print()ssc.start()ssc.awaitTermination()}}
提交Spark Streaming程序。
(spark-submit是提交到standalone集群的方式)
[root@master /]# cd /opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/spark/bin[root@master hadoop]# export HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/lib/hadoop/etc/hadoop[root@master hadoop]# SPARK_JAR=/opt/cloudera/parcels/CDH-5.3.8-1.cdh5.3.8.p0.5/jars/spark-assembly-1.2.0-cdh5.3.8-hadoop2.5.0-cdh5.3.8.jar[root@master bin]# ./bin/spark-submit \--class org.apache.spark.examples.streaming.NetworkWordCount \--master spark://192.168.53.230:7077 \--executor-memory 512m \--total-executor-cores 1 \/usr/application/tmp/NetworkWordCount.jar 192.168.53.230 9999 10# 此处提交时遇到如下问题,怀疑是[root@master spark-1.3.1-bin-hadoop2.6]# ./bin/spark-submit \> --class org.apache.spark.examples.streaming.NetworkWordCount \> --master spark://master:7077 \> --executor-memory 512m \> --total-executor-cores 1 \> /usr/application/tmp/NetworkWordCount.jar master 9999 10Exception in thread "main" java.lang.NoSuchMethodException: org.apache.spark.examples.streaming.NetworkWordCount.main([Ljava.lang.String;)at java.lang.Class.getMethod(Class.java:1670)at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:554)at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:166)at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:189)at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:110)at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties[root@master ~]# nc -lk 9999# spark-submit提交方式./bin/spark-submit \--class <main-class>--master <master-url> \--deploy-mode <deploy-mode> \# other options<application-jar> \[application-arguments]
