@JunQiu
2018-09-18T10:15:37.000000Z
字数 3756
阅读 2846
airflow(desc、use)
summary_2018/09 tools
1、日常
1.1、airflow的简介和使用
2、技术
2.1、airflow的简介和使用
2.1.1、airflow的简介
- Airflow 是 Airbnb 开源的一个用 Python 编写的任务调度工具。于 2014 年启动,2015 年春季开源,2016 年加入 Apache 软件基金会的孵化计划。
- 工作流的设计是基于有向非循环图 (Directed Acyclical Graphs, DAG) ,用于设置任务依赖关系和时间调度。可以让我们将一个大型任务拆分为多个独立的任务,再整体作为一个逻辑整体。
- 提供美观、功能多样的可视化界面,比如每一个DAG中task的运行情况,日志等等。
- DAG图

- DAG列表

- 名词介绍:
- DAG:意为有向无循环图,在 Airflow 中则定义了整个完整的作业。同一个 DAG 中的所有 Task 拥有相同的调度时间。
- Task:Task 为 DAG 中具体的作业任务,它必须存在于某一个 DAG 之中。Task 在 DAG 中配置依赖关系,跨 DAG 的依赖是可行的,但是并不推荐。跨 DAG 依赖会导致 DAG 图的直观性降低,并给依赖管理带来麻烦。
- DAG Run:当一个 DAG 满足它的调度时间,或者被外部触发时,就会产生一个 DAG Run。可以理解为由 DAG 实例化的实例。
- Task Instance:当一个 Task 被调度启动时,就会产生一个 Task Instance。可以理解为由 Task 实例化的实例。
2.1.2、服务构成和工作流程
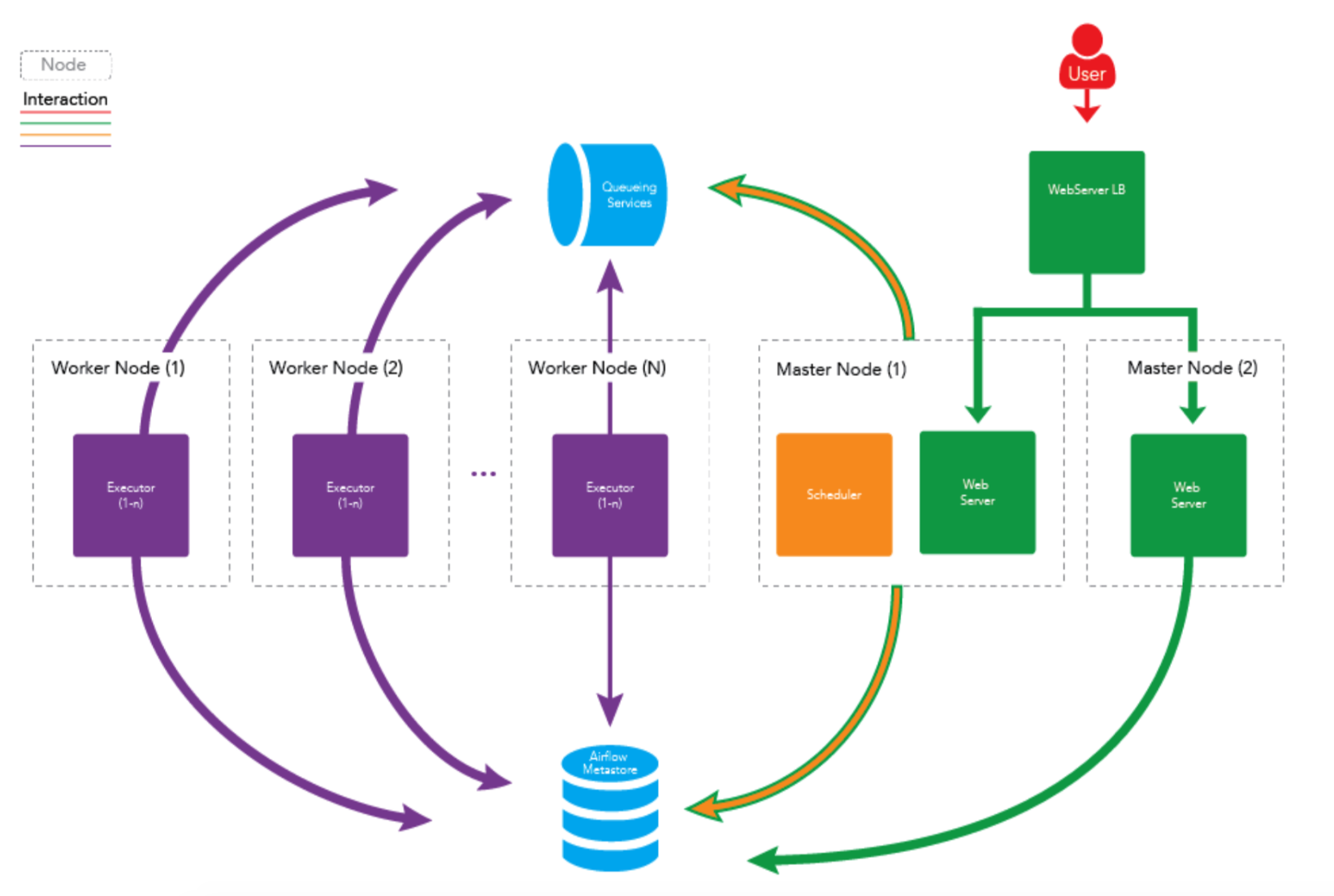
- 服务构成
// WebServerAirflow 提供了一个可视化的 Web 界面。启动 WebServer 后,就可以在 Web 界面上查看定义好的 DAG 并监控及改变运行状况。也可以在 Web 界面中对一些变量进行配置。// Worker一般来说我们用 Celery Worker 来执行具体的作业。Worker 可以部署在多台机器上,并可以分别设置接收的队列。当接收的队列中有作业任务时,Worker 就会接收这个作业任务,并开始执行。Airflow 会自动在每个部署 Worker 的机器上同时部署一个 Serve Logs 服务,这样我们就可以在 Web 界面上方便的浏览分散在不同机器上的作业日志了。// Scheduler整个 Airflow 的调度由 Scheduler 负责发起,每隔一段时间 Scheduler 就会检查所有定义完成的 DAG 和定义在其中的作业,如果有符合运行条件的作业,Scheduler 就会发起相应的作业任务以供 Worker 接收。// FlowerFlower 提供了一个可视化界面以监控所有 Celery Worker 的运行状况。这个服务并不是必要的。
- 工作流程
1、airflow启动时,会将DAG中的相关信息写入数据库。2、scheduler会按照指定频次查询数据库,检测是否有需要触发的任务。3、当scheduler检测到需要触发的任务时,会向消息队列发送一条Message。4、Celery会定时查询消息队列中是否有Message。当检测到Message时,会将Message中包含的任务信息下发给Worker,由Worker执行具体任务// Celery:分布式消息队列
- 多节点集群:
2.1.3、安装和实现DAG任务
- airflow安装参考
- 可能会有很多环境问题
- DAG实例:官方文档
# Importing Modulesfrom airflow import DAGfrom airflow.operators.bash_operator import BashOperatorfrom datetime import datetime, timedelta# some arguments for task# start_date DAG == schedule_interval is best waydefault_args = {'owner': 'airflow','depends_on_past': False,'start_date': datetime.now(),'email': ['airflow@example.com'],'email_on_failure': False,'email_on_retry': False,'retries': 1,'retry_delay': timedelta(minutes=5),# 'queue': 'bash_queue',# 'pool': 'backfill',# 'priority_weight': 10,'schedule_interval': timedelta(days=1),'end_date': datetime(2018, 9, 4),}dag = DAG('qj_airflow_test', default_args=default_args)# t1, t2 and t3 are examples of tasks created by instantiating operatorst1 = BashOperator(task_id='print_date',bash_command='date',dag=dag)t2 = BashOperator(task_id='sleep',bash_command='sleep 5',retries=3,dag=dag)templated_command = """{% for i in range(5) %}echo "{{ ds }}"echo "{{ macros.ds_add(ds, 7)}}"echo "{{ params.my_param }}"{% endfor %}"""t3 = BashOperator(task_id='templated',bash_command=templated_command,params={'my_param': 'Parameter I passed in'},dag=dag)t4 = BashOperator(task_id='print_date1',bash_command='date',dag=dag)# Setting up Dependenciest2.set_upstream(t1)t3.set_upstream(t1)t4.set_upstream([t2, t3])// 一些字段介绍## DAG要配置一个 DAG 自然需要一个 DAG 实例。在同一个 DAG 下的所有作业,都需要将它的 dag 属性设置为这个 DAG 实例。在实例化 DAG 时,通过传参数可以给这个 DAG 实例做一些必要的配置。# dag_id给 DAG 取一个名字,方便日后维护。# default_args默认参数,当属于这个DAG实例的作业没有配置相应参数时,将使用 DAG 实例的 default_args 中的相应参数。# schedule_interval配置 DAG 的执行周期,语法和 crontab 的一致。## TaskAirflow 提供了很多 Operator, BashOperator 则会执行 bash_command 参数所指定的 bash 指令,PythonOperator执行 Python callables,或者GoogleCloudStorageToBigQueryOperator、kubernetes_pod_operator(可以使用docker image,Tips:startup_timeout_seconds (int) – timeout in seconds to startup the pod(默认120))。Tips:如果在 DAG 中有设置 default_args 而在 Operator 中没有覆盖相应配置,则会使用 default_args 中的配置。# dag传递一个 DAG 实例,以使当前作业属于相应 DAG。# task_id给作业去一个名字,方便日后维护。# owner作业的拥有者,方便作业维护。另外有些 Operator 会根据该参数实现相应的权限控制。# start_date作业的开始时间,即作业将在这个时间点以后开始调度。## 依赖的配置除了可以使用作业实例的 set_upstream 和 set_downstream 方法外,还可以使用类似:task1 << task2 << task3task3 >> task4## 区分几个时间start date: 在配置中,它是作业开始调度时间。而在谈论执行状况时,它是调度开始时间。schedule interval: 调度执行周期。execution date: 执行时间,在 Airflow 中称之为执行时间,但其实它并不是真实的执行时间。# 举个例子:假设我们配置了一个作业的 start date 为 2017年10月1日,配置的 schedule interval 为 **00 12 * * *** 那么第一次执行的时间将是 2017年10月2日 12点 而此时记录的 execution date 为 2017年10月1日 12点。因此 execution date 并不是如其字面说的表示执行时间,真正的执行时间是 execution date 所显示的时间的下一个满足 schedule interval 的时间点。
2.1.4、总结
- airflow对复杂的、特别是依赖十分复杂、或着比较大型的调度任务管理十分有用。
