@JunQiu
2018-09-18T13:12:45.000000Z
字数 2950
阅读 1710
kafka
summary_2018/08 messageQueue tools
1、日常
1.1、kafka
2、技术
2.1、kafka
2.1.1、kafka简介
- Kafka是一种分布式的,基于发布/订阅的消息系统。
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输
- 同时支持离线数据处理和实时数据处理
2.1.2、kafka系统架构
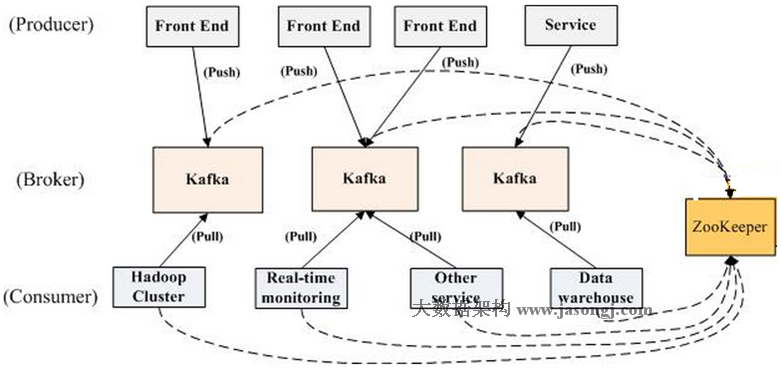
定义:// BrokerKafka集群包含一个或多个服务器,这种服务器被称为broker// Topic每条发布到Kafka集群的消息都有一个类别,这个类别被称为topic。(物理上不同topic的消息分开存储,逻辑上一个topic的消息虽然保存于一个或多个broker上但用户只需指定消息的topic即可生产或消费数据而不必关心数据存于何处)// Partitionparition是物理上的概念,每个topic包含一个或多个partition,创建topic时可指定parition数量。每个partition对应于一个文件夹,该文件夹下存储该partition的数据和索引文件// Producer负责发布消息到Kafka broker// Consumer消费消息。每个consumer属于一个特定的consumer group(可为每个consumer指定group name,若不指定group name则属于默认的group)。使用consumer high level API时,同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。
2.1.3、 Push & Pull
作为一个messaging system,Kafka遵循了传统的方式,选择由producer向broker push消息并由consumer从broker pull消息。push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
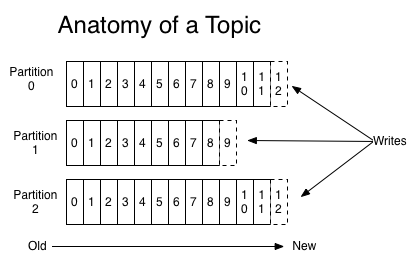
2.1.4、 Topic & Partition
Topic在逻辑上可以被认为是一个queue。每条消费都必须指定它的topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以水平扩展,物理上把topic分成一个或多个partition,每个partition在物理上对应一个文件夹,该文件夹下存储这个partition的所有消息和索引文件。Tips1:每个分区都是一个有序的序列Tpis2:对于传统的message queue而言,一般会删除已经被消费的消息,而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据(实际上也没必要),因此Kafka提供两种策略去删除旧数据。一是基于时间,二是基于partition文件大小。例如可以通过配置$KAFKA_HOME/config/server.properties,让Kafka删除一周前的数据,也可通过配置让Kafka在partition文件超过1GB时删除旧数据.Tips3:因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除文件与Kafka性能无关,选择怎样的删除策略只与磁盘以及具体的需求有关。另外,Kafka会为每一个consumer group保留一些metadata信息–当前消费的消息的position,也即offset。这个offset由consumer控制。正常情况下consumer会在消费完一条消息后线性增加这个offset。当然,consumer也可将offset设成一个较小的值,重新消费一些消息。因为offet由consumer控制,所以Kafka broker是无状态的,它不需要标记哪些消息被哪些consumer过,不需要通过broker去保证同一个consumer group只有一个consumer能消费某一条消息,因此也就不需要锁机制,这也为Kafka的高吞吐率提供了有力保障。
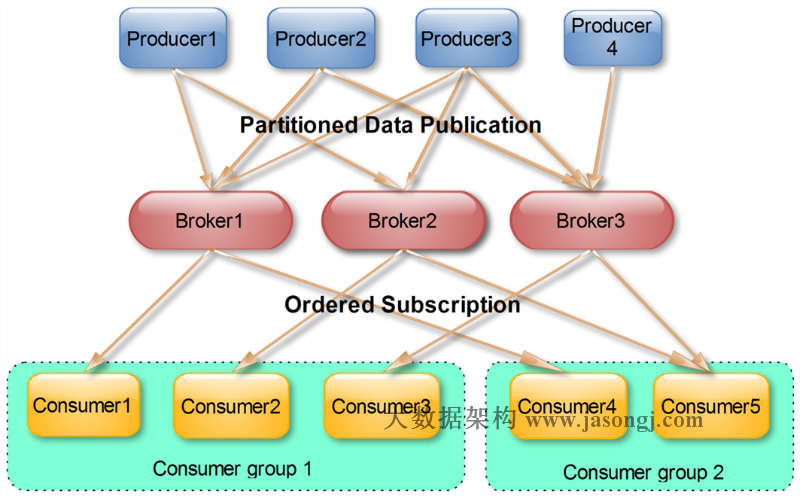
2.1.5、 Consumer group(consumer hight level API)
- 每一个consumer实例都属于一个consumer group,一个主题的每一条消息只会被同一个consumer group里的一个consumer实例消费。(不同consumer group可以同时消费同一条消息)
2.1.6、 Replication
- Kafka从0.8开始提供partition级别的replication,replication的数量可在server.properties中配置。允许Kafka在群集中的服务器发生故障时自动故障转移到这些partition副本。
- 每个partition都有一个唯一的leader,所有的读写操作都在leader上完成,follower批量从leader上pull数据。zookeeper维护一个”in sync” list(ISR)。(replica.lag.max.messages设置为4,这意味着只要跟随者在领导者后面不超过3条消息,它就不会从ISR中删除。和replica.lag.time.max.ms 设置为500毫秒,这意味着只要关注者每500毫秒或更早地向领导者发送一个获取请求,它们就不会被标记为死亡,也不会从ISR中删除。)
- 重要问题:当leader宕机了,怎样在follower中选举出新的leader:majority vote
- 参考文档
- 当生产者将下一条消息发送给领导者,同时跟随者3进入GC暂停状态,他们看起来像这样:

2.1.7、 Consumer Rebalance
- Kafka保证同一consumer group中只有一个consumer会消费某条消息,实际上,Kafka保证的是稳定状态下每一个consumer实例只会消费某一个或多个特定partition的数据,而某个partition的数据只会被某一个特定的consumer实例所消费。这样设计的劣势是无法让同一个consumer group里的consumer均匀消费数据,优势是每个consumer不用都跟大量的broker通信,减少通信开销,同时也降低了分配难度,实现也更简单。另外,因为同一个partition里的数据是有序的,这种设计可以保证每个partition里的数据也是有序被消费。
-
- 官方文档:范围分区基于每个主题。对于每个主题,我们按字母顺序排列可用分区,按字典顺序排列使用者线程。
Kafka的默认“范围”分配算法以循环方式单独分配每个主题,而不是在整个消费者群中循环遍历所有主题的分区。
- 参考文献
- Kafka深度解析
- Kafka Replication
- Consumer Rebalance
- 官方文档
