@EtoDemerzel
2018-07-17T12:13:26.000000Z
字数 3111
阅读 2226
NRL论文阅读笔记(一)
NRL paper
CANE:context-Aware Network Embedding for Relation Modeling
传统:
learn a fixed context-free embedding for each vertex.
每一个vertex的embedding是固定的、上下文无关的。
缺点:不能解决一个vertex在与不同neighbor交互时体现的差异;总是要求neighbors的embedding接近,但这个特点并非普适特性。
本工作:
assume that one vertex usually shows different aspects when interacting with different neighbor vertices and show different embeddings respectively.
假设在与不同邻居交互时体现出不同的特性,因此也有不同的embedding。
使用在information network中。Information network具有大量上下文信息,包括文字、标签等。
当和交互时,其embedding来自它们的text information 和 。可用CNN/RNN建立context-free的embedding,要实现context-aware需要引入 之间的mutual attention。
目标函数
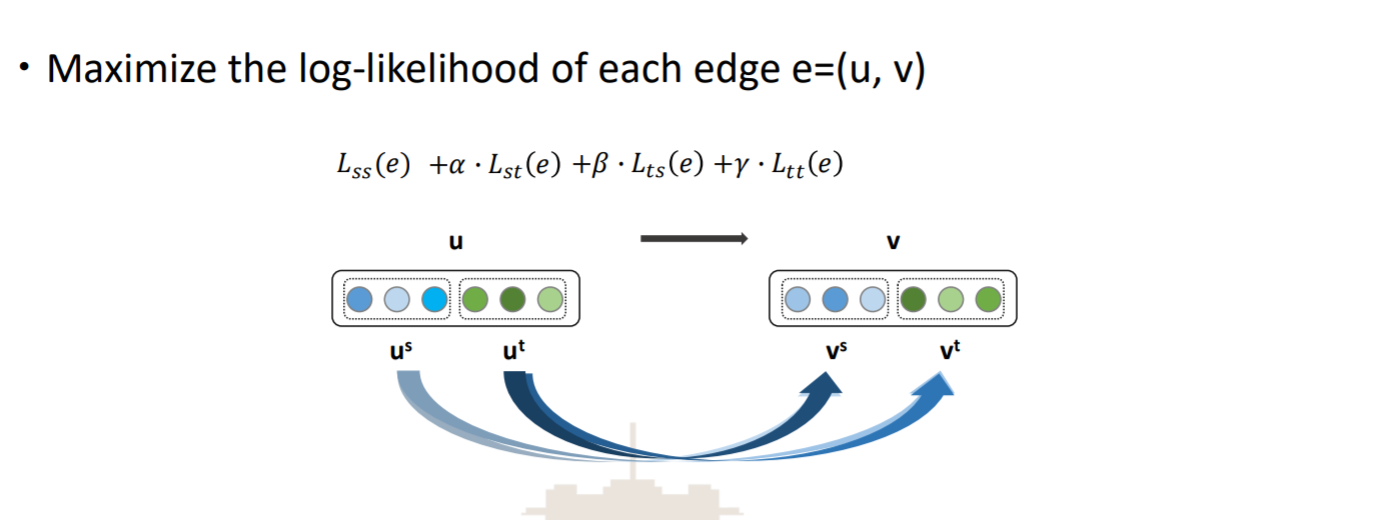
是structure-based的目标函数, 是text-based的目标函数。
其中
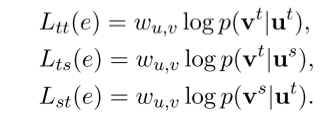
上述的条件概率都是用softmax的方式来描述的,如
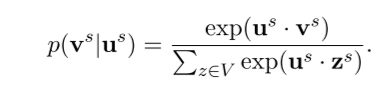
其余几个类似。
structure-base embeddings 与一般的NE算法中一样被当作参数来训练。
text-based embedding是通过CNN获得的。
Context-free embedding
分为三个阶段
Looking up: 把一个词语序列 转换成其embedding序列,其中
Convolution: Sliding window长度为 。
其中 为卷积矩阵, 为第 个window。采用zero padding。这样对于一个结点的text context( 个词语),就可以得到 到 这 个维度为 的向量。
Max pooling:
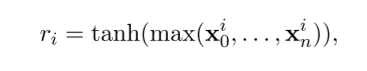
按上图中方式进行max pooling以及非线性化的处理。
Context-aware embedding
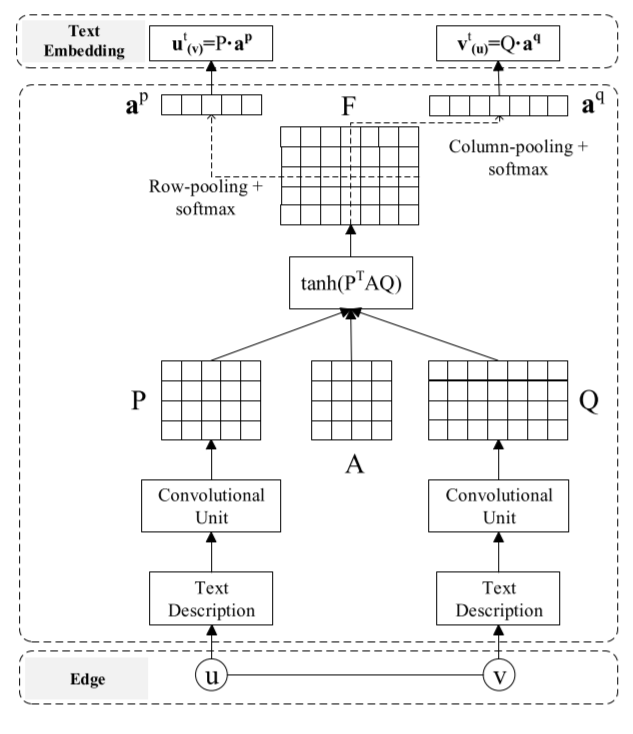
, 和 ,再引入一个
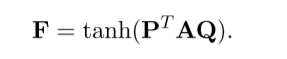
对 的行和列分别进行average pooling并进行softmax,最后的text-based embedding就通过如下方式产生:
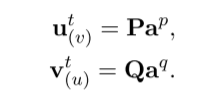
完整的embedding就是structure-based embedding和text-based embedding拼接而成。
Optimization of CANE
negative sampling + Adam。
总体上说主要是力图对一个结点与不同结点相互作用时体现出的不同特性进行了建模;同时在考虑两点的作用时除去它们之间边的权重外还引入了text-based information的考虑(不知道这个是不是他们的创新因为现在论文看的还不够多。。)。只是paper中能处理的information仅限于文字而尚未提到图片、标签等。
实验的部分,是考察了link prediction和vertex classification两个方面。其中vertex classification按理是应该通过全局的embedding来分类的,而本文中一个结点对其他结点的embedding都是不同的。这里的处理是对它们求均值,并且按照这个embedding来做的效果还不错,实验中的效果应该是仅次于CENE。
Enhancing the Network Embedding Quality with Structural Similarity
传统: 专注Neighborhood information,但通过neighborhood不能反映结构信息。理论和实践表明,random-walk based 的采样策略无法完整捕捉结构相关的性质。
本工作:提出SNS,使用结构信息来提高embedding质量。
Structural similarity:
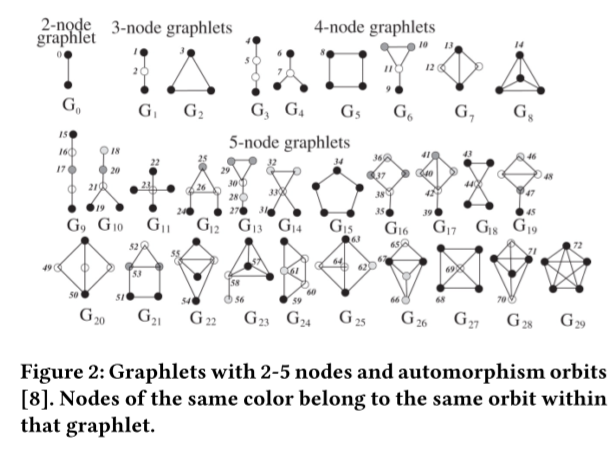
如上图,在2-5个结点的graphlet(共30个)中,共有73个轨道。定义Graphlet Degree Vector(GDV)为一个73维的向量,第 维( shouldn't it be a typo? 72 instead?)的数字表示此结点出现这个轨道的次数。
我们用欧式距离来刻画结构相似。
计算GDV的方式,参考这篇论文,实现的代码在这里可以找到。
分析Random-walk based sampling的特点和不足
1. DeepWalk:任意两个结点 和 同时出现的概率由路径上结点的度决定,与 的度无关。而路径长度又受到窗口大小的限制。
2. 两个结点之间短路径越多(strong),中间结点的度越小(direct),这两个结点共同出现的概率就越高。
3. node2vec中引入的两个参数p和q分别代表着strong和direct两个方面。
4. random-walk based sampling只捕捉目标结点附近的高阶相似度。
5. 缺点:strength和directness并不能被视为结构上的关联;并且窗口之外的拓扑信息无法捕捉。
Pre-processing step:
太多特征容易导致过拟合,并且并非所有轨道对任务的贡献都相同。
使用随机森林分析73个轨道的相对重要性:
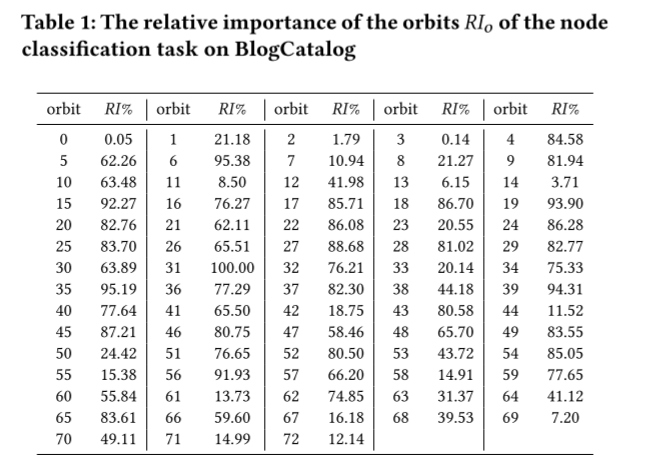
A general idea:对任何graphlet,外围轨道(度更大)比核心轨道(度更小)更重要。故在计算GDV时,外围轨道的权重应该更大。
Limit the scope of similar nodes: 由实际任务决定。在一些情况下,相互连接的结点更有可能标签相同;另一些情况下结构类似才是主要因素。因此maximum steps数量 会有所不同。
在预处理阶段,graphlet counting算法先计算每个结点的GDV;然后对每一个结点计算K个最近的邻居。注意结构相似的结点需要限制在 阶内,即距离目标结点距离不能超过 .
结果保存在稀疏矩阵 中, 如果 在 的 K个最近邻居之列, 为其similarity score;否则为0。并且 .
Network embedding powered by structural similarity:
这里使用CBOW + negative sampling。
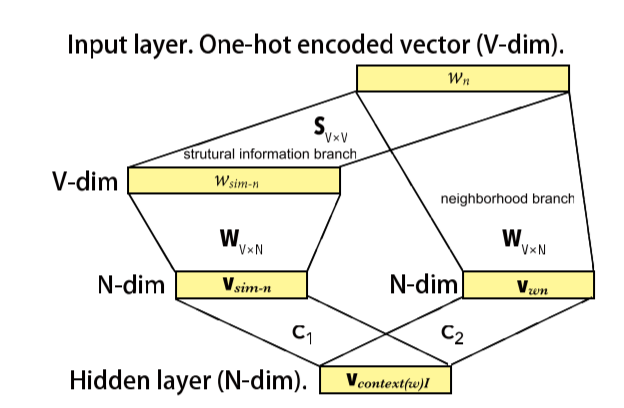
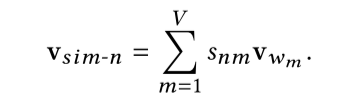

对于度数较大的结点来说,neighborhood能提供更多信息,而度数较小的结点更依赖于结构信息;因此 对于前者, 应该更大,而后者 更大。通常把结点按度数逆序排列,分为 个等级,同一级别的结点使用同样的参数。
主要贡献在于在random-walk based的方法之基础上,加入结构信息的考虑。
