@1kbfree
2018-09-09T12:02:34.000000Z
字数 2290
阅读 1800
Python Requests库
python
HTTP协议(超文本传输协议)
URL是这样组成的:

URL是什么:

比如www.baidu.com就是一个URL~~
Python Requests是什么
python requests库就是一个网络请求包,也就是爬虫~
爬虫有什么用
- 至于爬虫用处可多了,比如我们一些人渴望研究一些人性之"美"的时候,可以利用爬虫,去爬某站的图片(污污污~~),有些人会问,那不如直接下载呢。不是的,在网络中有线程进程之说,我们人类再快,终究还是二只手,而且机器运行起来不会累,我们人类是会疲惫的,所以说爬虫是可肯定比人快,而且方便,这就是爬虫的好处了。
- 爬虫远远不止这些功能,就好像渗透中,我们常常会遇到sql注入漏洞,在后站中慢慢测试and 1=1;and 1=2 相当麻烦,我们可以写一个工具批量来扫,比如:
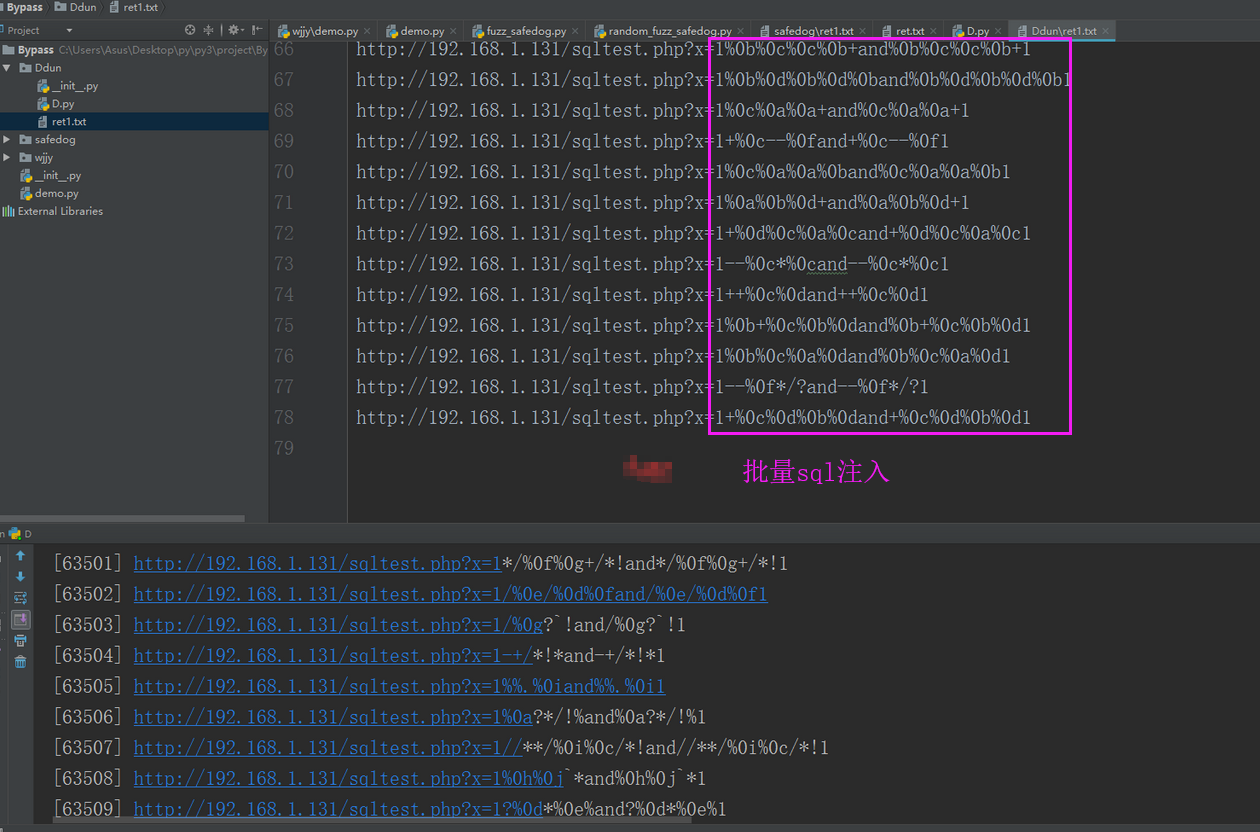 (这是某表哥['ske大佬']写的),所以说爬虫可以写一些渗透脚本,方便我们的测试工作。
(这是某表哥['ske大佬']写的),所以说爬虫可以写一些渗透脚本,方便我们的测试工作。 - 后面我还会写一个简单的渗透脚本,来完成简化我们的渗透工作
- 编不下去了...
爬虫的误区
其实爬虫单单只能完成你能做的事情,就好像你无法访问国外的网站,你写的爬虫照样不能访问,爬虫只是单单的帮助你完成你要干的事情,就好像是有一个机器人在无时无刻的帮你操作,直到任务完成
爬虫分类

爬虫的危害
- 对服务器造成困扰
- 可能导致个人隐私泄露
爬虫的限制

请求方式

GET:
POST:
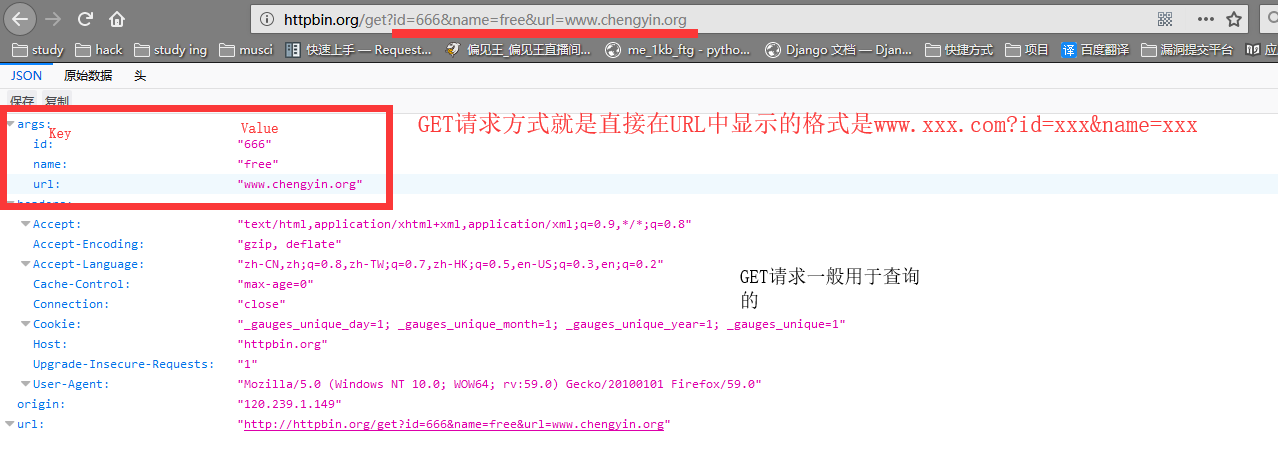
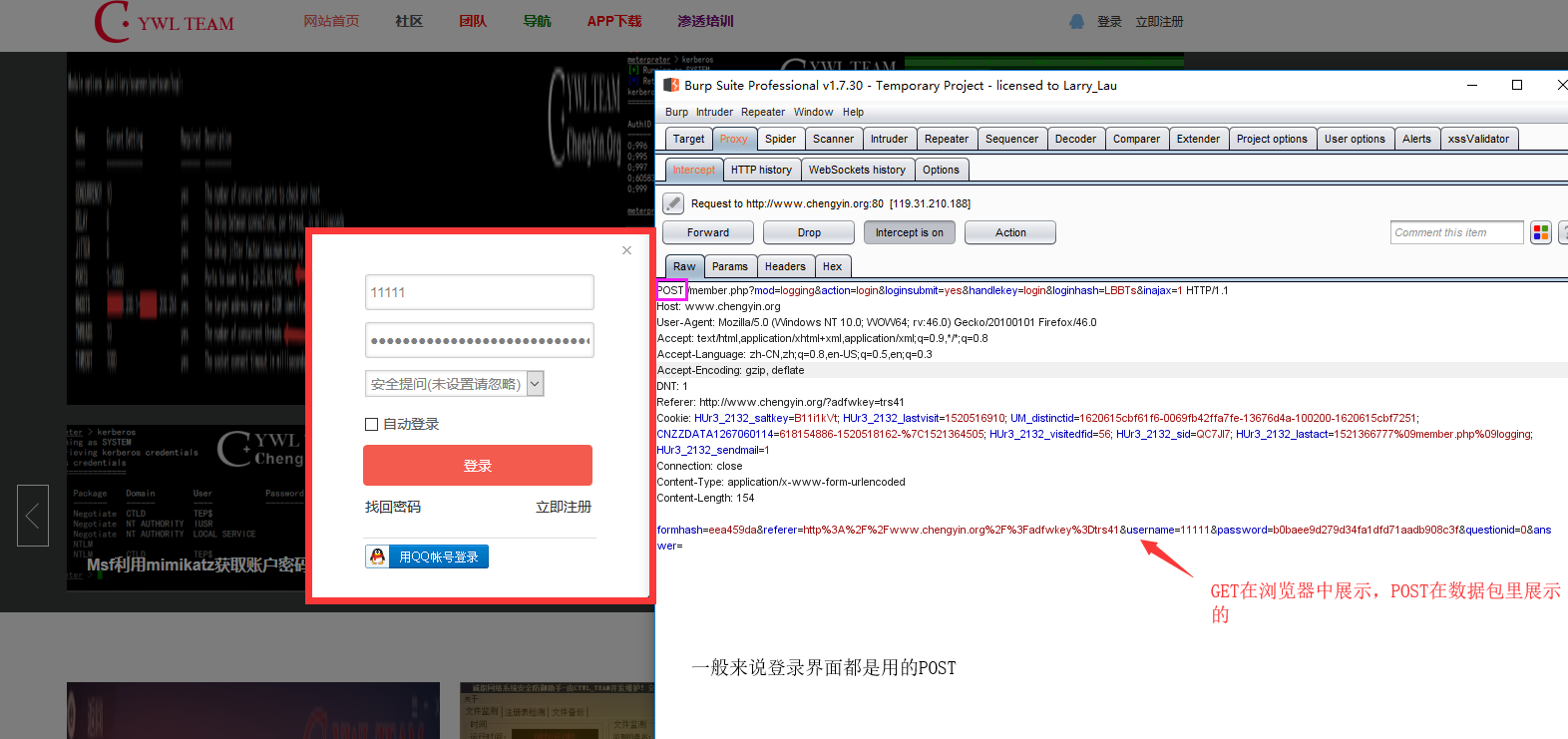
Requests库代码讲解

简单获取网站的内容
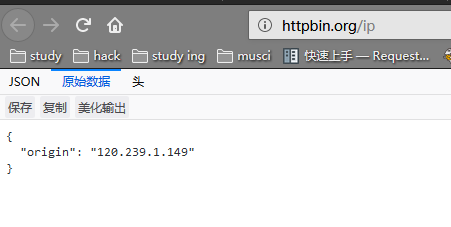
import requestsr = requests.get( #get是请求方式,不明白的看下面"http://httpbin.org/ip")print(r.text) #r.text就是获取r请求的那个网站的内容看下面截图'''返回结果{"origin": "120.239.1.149"}'''
传递URL参数(GET请求)
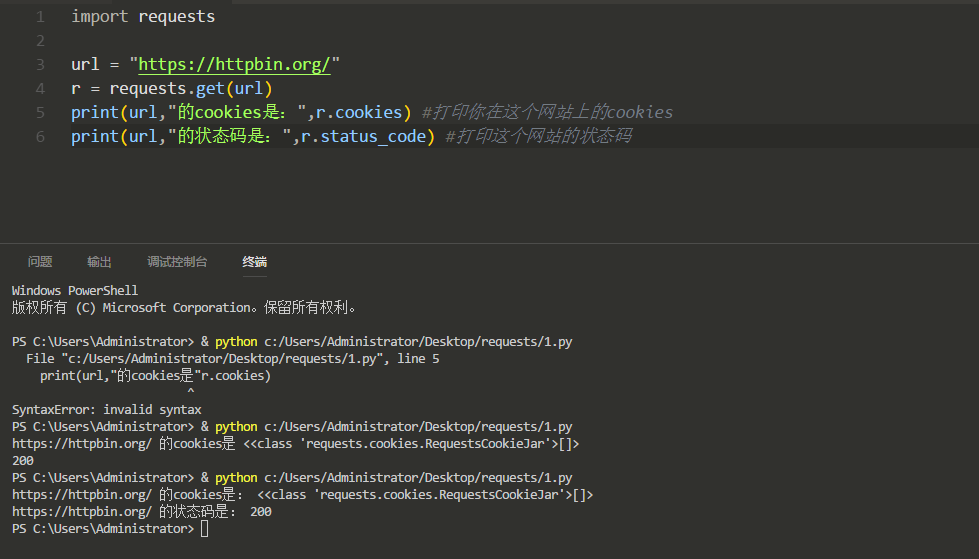
首先,我们先了解一下,什么是URL参数呢,我们以我们的论坛为例子。
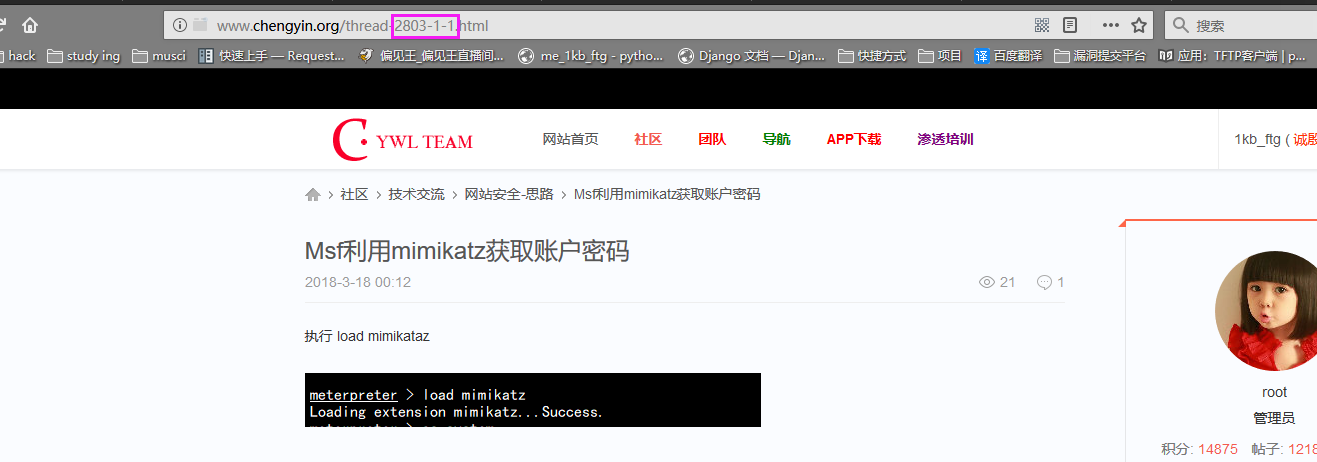
------华丽的分割线------
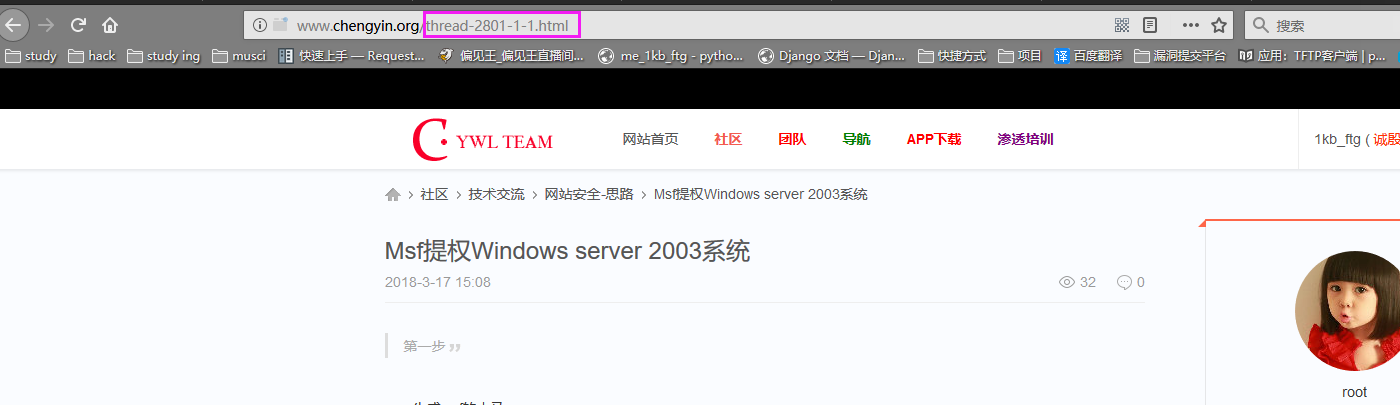
我们可以看到2801、2803可能就是文章的ID,这个ID也可以称为参数吧,如果没看懂我们拿百度再来举一个例子(其实论坛是拿来宣传一波的)
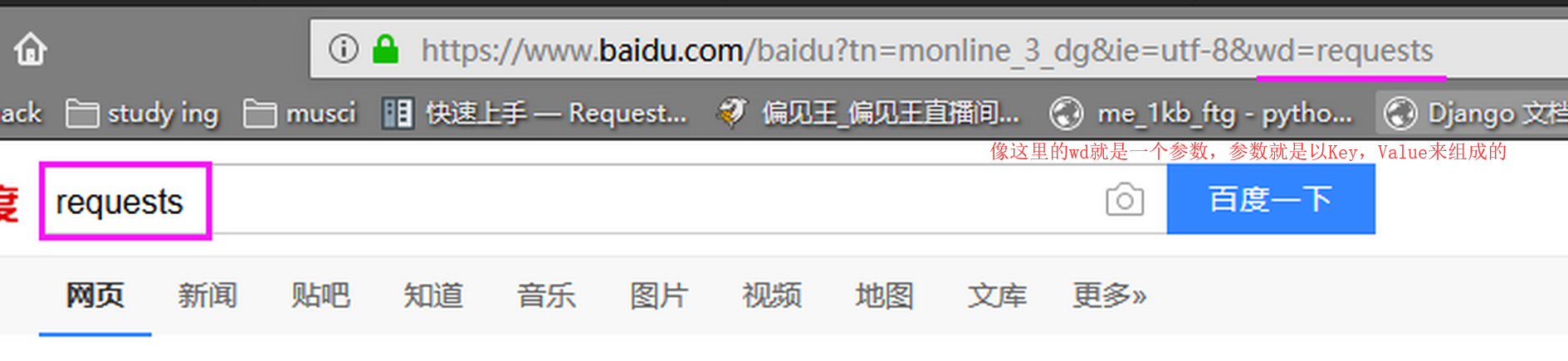
百度:
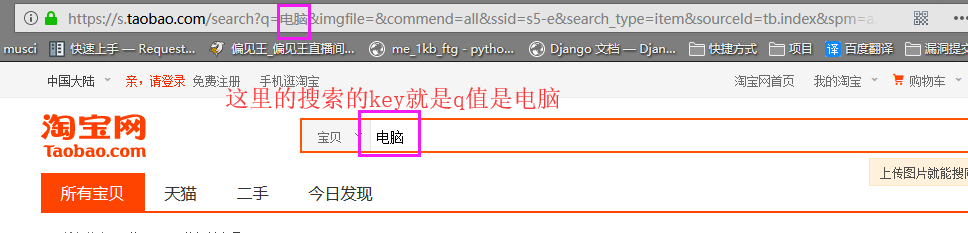
淘宝:
所以我们可以用Requests来写一个百度的搜索引擎,当然淘宝,京东之类也可以,案例待会讲
我们来看看Requests是如何来给百度传参的:
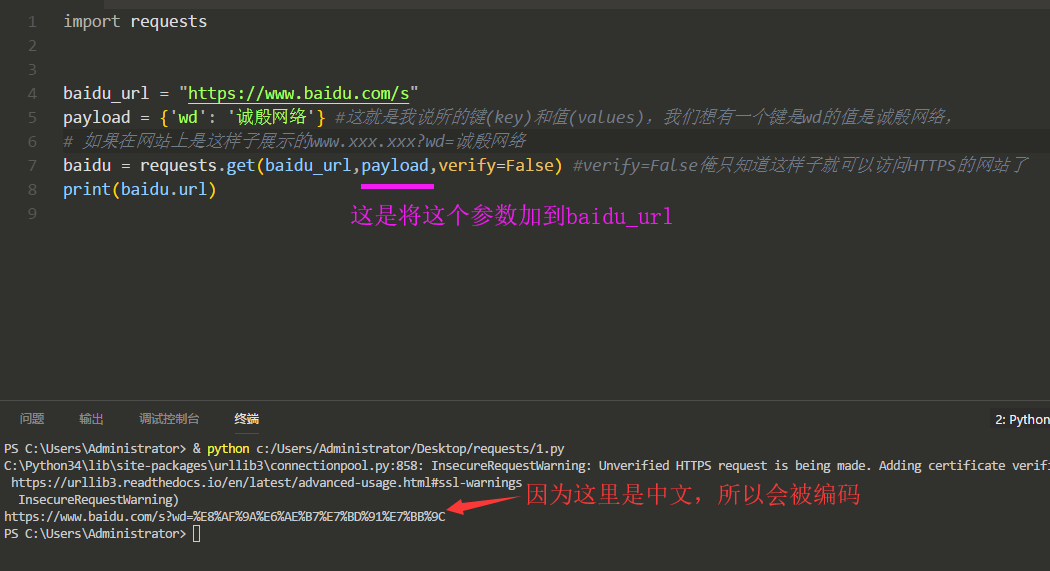
然后我们把这个URL放到浏览器来访问以下,看是否有返回有关诚殷网络的内容:

这是代码各位可以试一试
# 给百度传参import requestsbaidu_url = "https://www.baidu.com/s"payload = {'wd': '诚殷网络'} #这就是我说所的键(key)和值(values),我们想有一个键是wd的值是诚殷网络,# 如果在网站上是这样子展示的www.xxx.xxx?wd=诚殷网络baidu = requests.get(baidu_url,payload,verify=False) #verify=False俺只知道这样子就可以访问HTTPS的网站了print("url:",baidu.url)
我们来看看Requests是如何来给淘宝传参的:
其实思路都是一样的,只是key值value值不同
在上面淘宝那张截图我们看到了淘宝的搜索key是q,直接上代码:
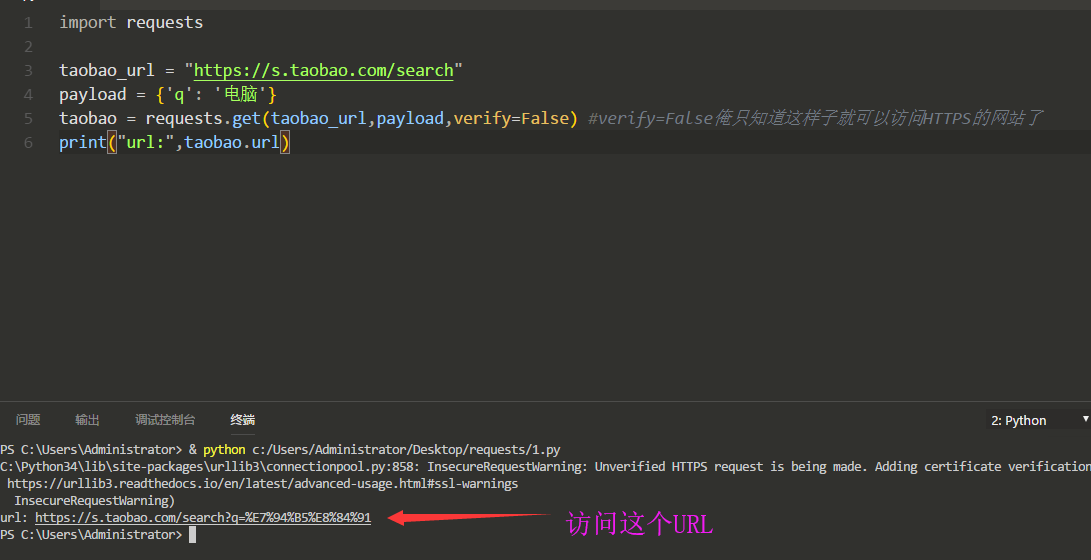
我们将URL复制到浏览器中访问一下:
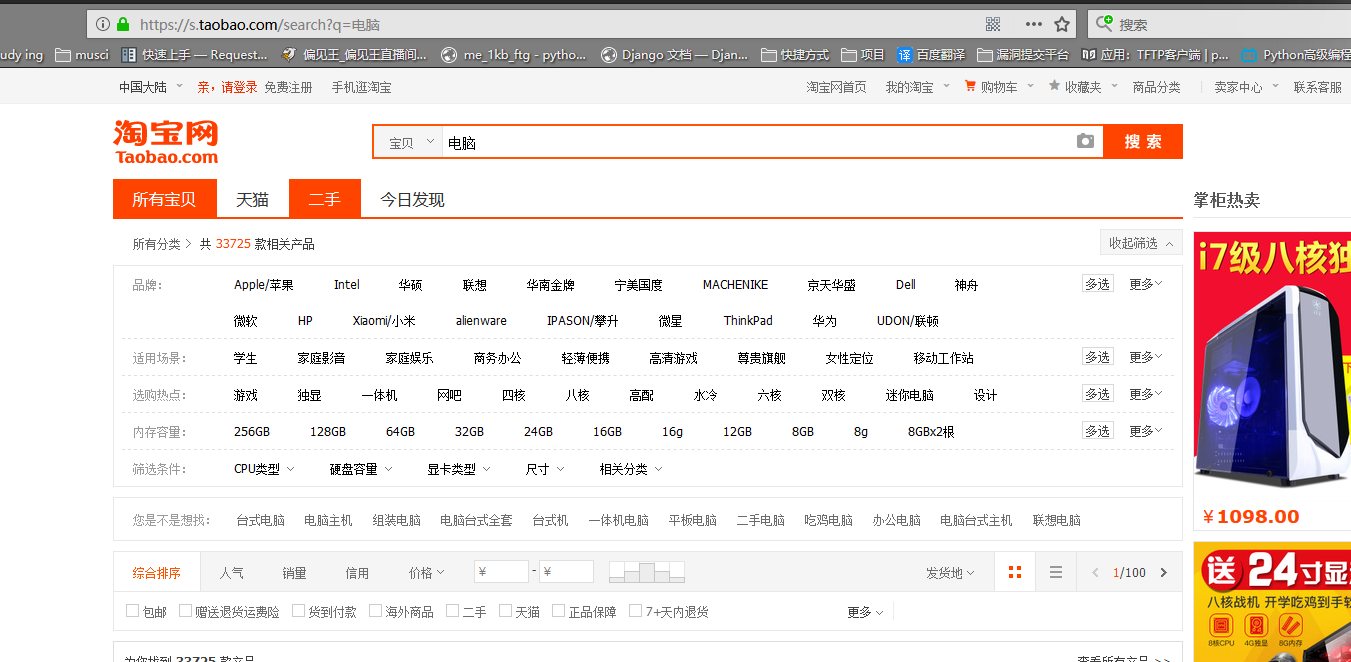
这是POST传参:

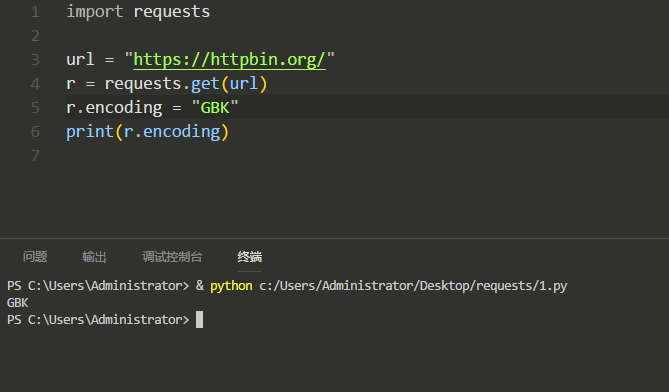
打印出网站的编码(比如UTF-8、GBK):
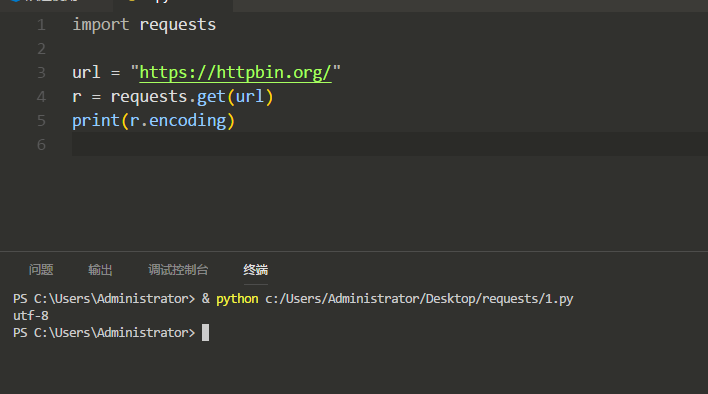
修改网站编码:
and
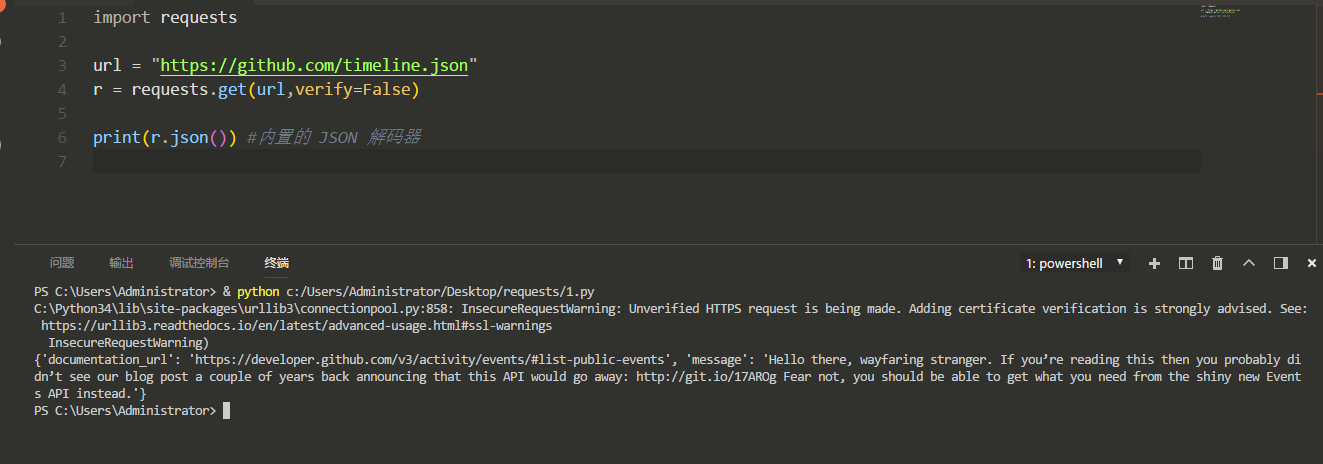
如果 JSON 解码失败, r.json() 就会抛出一个异常。例如,响应内容是 401 (Unauthorized),尝试访问 r.json() 将会抛出 ValueError: No JSON object could be decoded 异常。
需要注意的是,成功调用 r.json() 并**不**意味着响应的成功。有的服务器会在失败的响应中包含一个 JSON 对象(比如 HTTP 500 的错误细节)。这种 JSON 会被解码返回。要检查请求是否成功,请使用 r.raise_for_status() 或者检查 r.status_code 是否和你的期望相同。
用Reuqests下载网络图片
首先我们看一下这是要下载的图片地址:
可看到content是来返回这个网站的二进制响应内容的:

我们将这个图片下传到本地来:
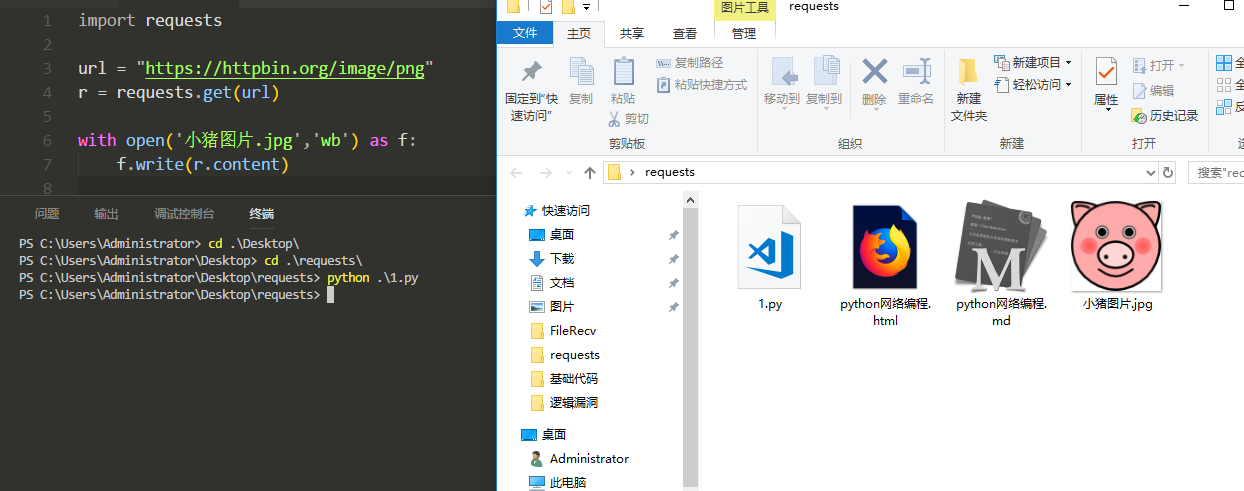
有人会问我,为什么是wb而不只是w,因为这里是二进制数据,我们必须使用wb写才可以,否则会报错的。
代码:
import requestsurl = "https://httpbin.org/image/png"r = requests.get(url)with open('小猪图片.jpg','wb') as f:f.write(r.content)
自定义请求的请求头
请求头有什么用,我来演示一下,首先我们不加任何东西去访问一下知乎网:
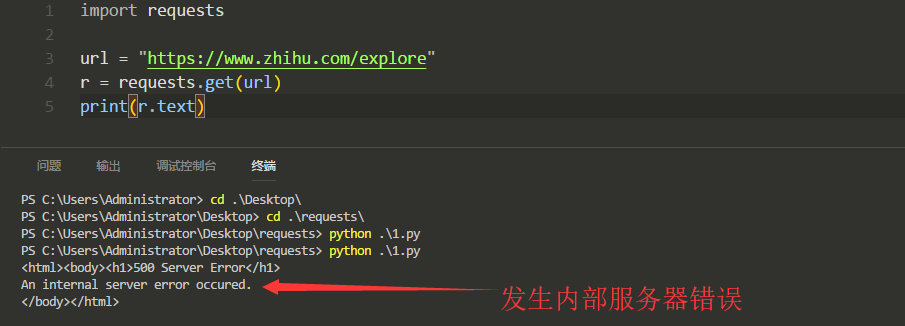
我们是无法访问的:
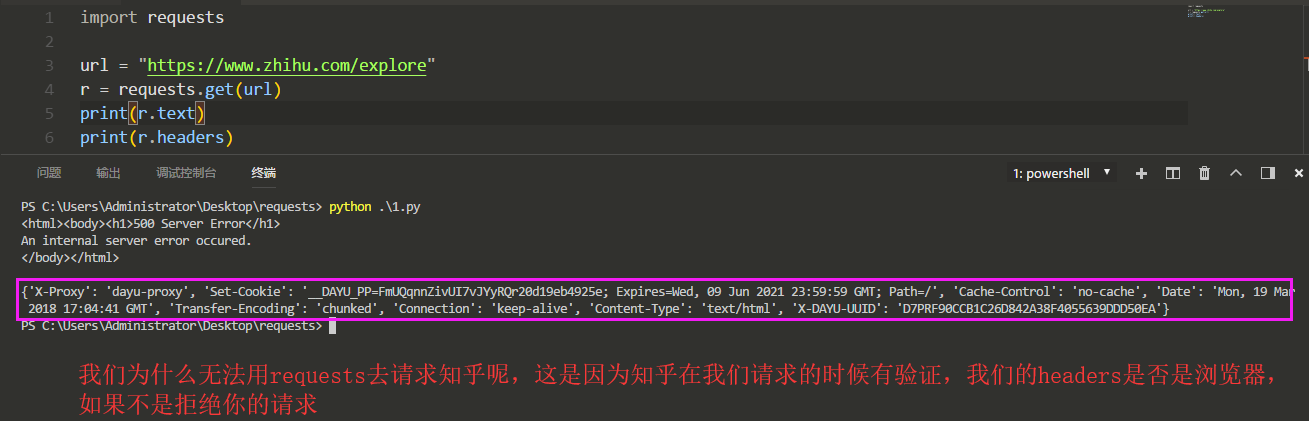
那我们如何来访问呢?设置请求头(headers),但是我们必须找到请求头才可以伪造,所以我们正常访问知乎,并且用Burp将请求包头全部复制下来:
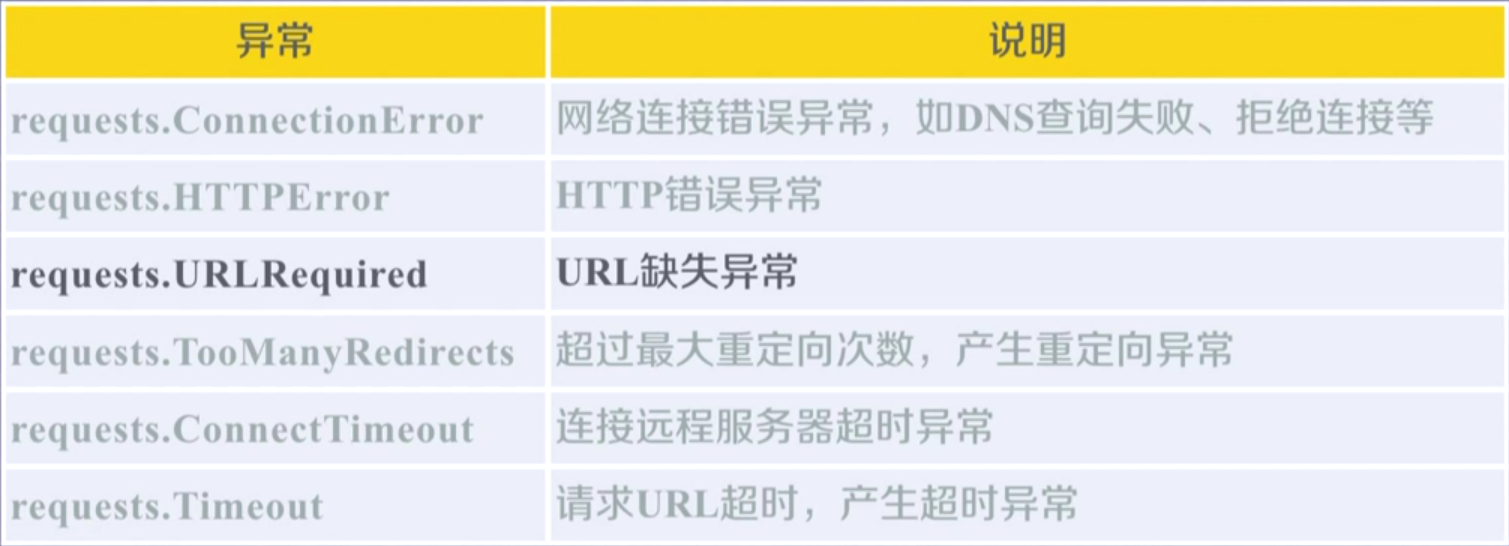
Requests 异常

设置超时:
requests.get("https://www.baidu.com",timeout = 6)就是说如果我们访问百度的话,6秒内没有访问成功,就会报错,所以我们可以这样子:
out_time = 6 #设置超时时间url = "https://www.xxx.xxx"try:requests.get(url,timeout = out_time)except:print(url,"访问失败,因为已经超时{out_time}秒了~".format(out_time = out_time))
给将信息写在文件里传输:

设置代理:

