@songlaf
2016-12-02T02:49:39.000000Z
字数 1153
阅读 795
Spark的安装
Spark
spark的安装

val rdd = sc.textFile("/input/a.txt")

spark读取数据是一行一行的读取到rdd,而mr是读取成key,value对
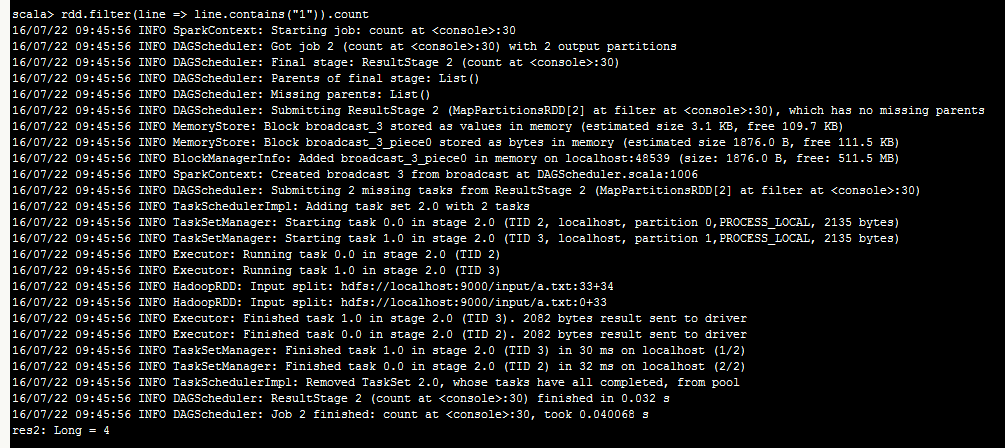
rdd.filter(line => line.contains("1")).count
读取数据\处理数据\输出数据
测试wordcout
读取数据 val rdd = sc.textFile("/input/mapred-env.sh")
process
val wordCountRdd = rdd.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey((a, b) => (a + b))
output
wordCountRdd.saveAsTextFile("/output1")
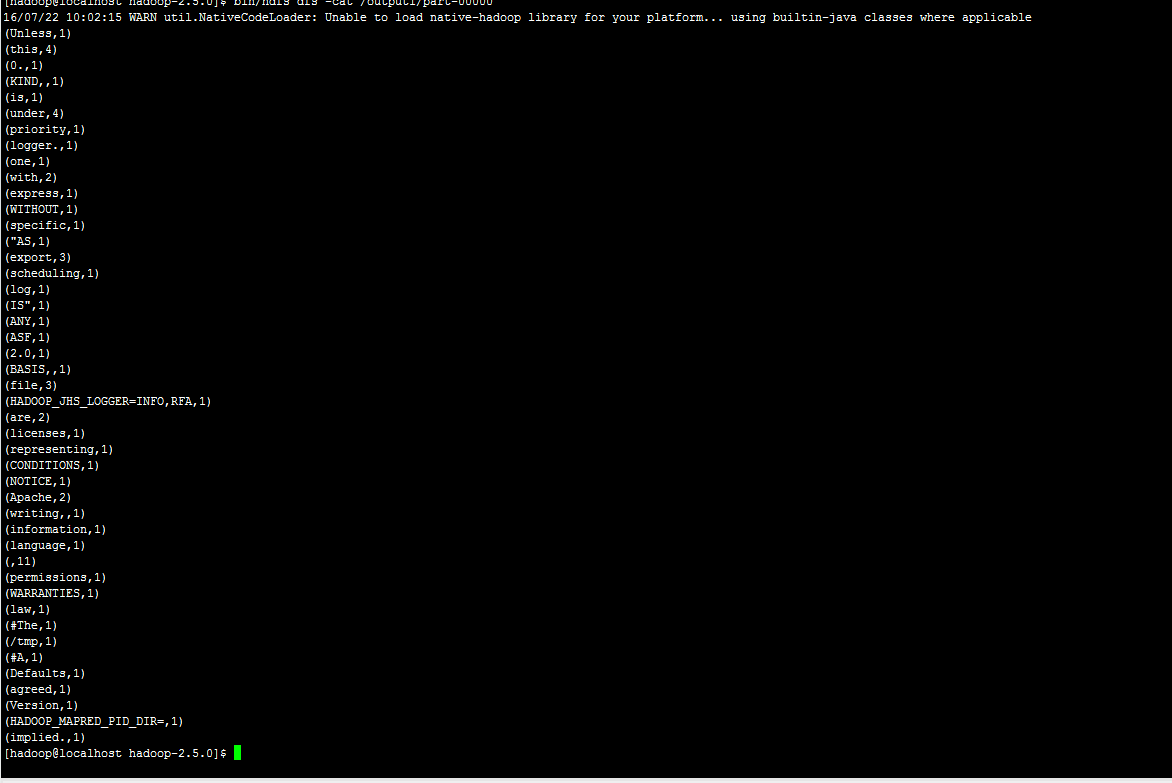
查看结果
bin/hdfs dfs -cat /output1/part-00000
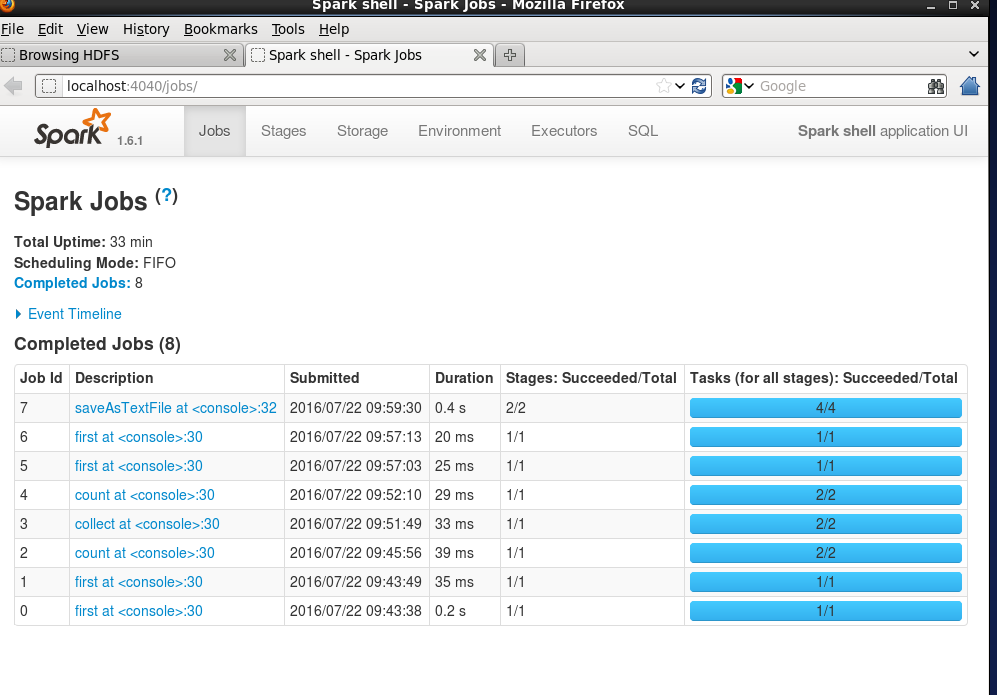
hdfs查看运行状况的4040窗口
目前spark的运行方式
1)目前Spark程序运行到YARN上.
2)standone
自带带分布式资源管理和任务调度.
主节点master,相当于resourcemanager
从节点works相当于nodemanager
SPARK_MASTER_IP=localhost
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=2
SPARK_WORKER_MEMORY=2g
SPARK_WORKER_PORT=7078
SPARK_WORKER_PORT=8081
SPARK_WORKER_INSTANCES=1
可以运行多个work每个work的端口加1
start-slaves.sh
启动所有的从节点,也就是Work
注意:
使用此命令时,运行此命令的机器,必须要配置与其他机器的SSH无密钥登录,否则启动的时候会出现一些问题,比如说输入密码之类的。
启动主节点 sbin/start-master.sh
执行在集群上执行spark-shell
bin/spark-shell --master spark://s1.hd.com:7077
对于Spark Application
两部分组成:
-1,Driver Program -> 4040 4041 4042
运行spark应用(main方法),,里面有个,所有任务的调度都通过SparkContext来运行.
-2,每个应用有个自己的Executor,其实就是JVM进程,包含一些资源.
JVM(进程)
运行我们Job的Task
Spark Application有很多job,然后每个job划分成很多个stage,而每个stage划分成很多的task,每个task的业务都是相同,只是处理的数据不同.