@songlaf
2016-06-17T13:31:28.000000Z
字数 5190
阅读 882
作业二十三【HBase 功能配置及Shell基本使用】
北风网大数据培训
一)HBase和传统的DBMS:
互联网时代,数据库常常经历从一个从单台DB,到主从复制,到垂直分区再到水平分区的痛苦的过程,但是数据越来越大,这个时候传统的关系型数据就不适合了,于是就出现了HBaseh,关系型数据适合数据量不大,需要事务的场合,hbase适合海量的数据。
| 关系型数据库RDBMS | HBase |
|---|---|
| 支持向上扩展。(若需要更多的磁盘、内存和处理能力,需要升级服务器) | 支持向外扩展。(若需要更多的磁盘、内存和处理能力,不需要升级服务器,需要为集群添加新的服务器) |
| 使用SQL查询从表中读取数据 | 使用API和MapReduce来访问HBase表的数据 |
| 面向行(每行数据都是一个连续的页的单元) | 面向列(每列数据都是一个连续的页的单元) |
| 模式更严格 | 模式灵活,不太严格 |
| 具有ACID支持 | 没有内建的对HBase的支持 |
| 适合结构化数据 | 适合结构化和非结构化数据 |
| 传统关系型数据库一般是中心化的 | 通常是分布式的 |
| 一般能保证事务完整性 | HBase不支持事务 |
| 支持JOIN | 不支持JOIN |
| 支持参照完整性 | 没有内置的参照完整性支持 |
Hbase是面向列存储的非结构化的数据库,可伸缩的分布式存储。
| 列存储数据库的优点 | 列存储数据库的缺点 |
|---|---|
| 具有高效和数据压缩的内部支持 | JOIN和多表合并数据的查询性能不好 |
| 支持快速数据检索 | 更新过程中有大量的写入和删除操作,需要频繁合并和分裂,降低了存储效率 |
| 管理和配置简单。支持横向扩展 | 对关系模型支持不好,分区和索引模式设计比较困难 |
| 聚合查询的性能非常高 | |
| 可高效地进行分区 |
二)HBase和HDFS
- HBase是水平扩展的、分布式的、开源有序映射数据库。
- 它运行在Hadoop文件系统HDFS上。它不要求有预定义的模式,可以被看做 弹性扩展的多维表格,通过动态添加列,在数据插入或查询之前修改列结构, 以支持任意的数据结构。
- HBase是一个建立在HDFS上的列存储数据库,具有至此线性扩展(横向扩 展)、自动故障转移、自动分区及模式自由等特性。
| HDFS | Hbase |
|---|---|
| 为分布式存储提供文件系统 | 提供表状的面向列的数据存储 |
| 针对存储大尺寸的文件进行优化,不需要对这些文件进行随机读写 | 针对表状数据的随机读写进行优化 |
| 直接使用文件 | 使用key-value对数据 |
| 数据模型不灵活 | 提供灵活的数据模型 |
| 使用文件系统和处理框架 | 使用表状存储,依赖内置的Hadoop MapReduce支持 |
| 为一次写多次读进行优化 | 为多次读写进行优化 |
三)HBase的结构

3.1)Master:
为HBase的主节点,用来协调客户端应用程序和RegionServer的关系,同时用来监控和记录 元数据的变化和管理。
3.1)RegionServer:
是从节点,用region的形式处理实际的表。region是HBase表的基础单元组件,它存储了分 布式表。所以HBase表和HBase集群利用Master和RegionServer来协同工作,
RegionServer也可以任意加。它运行在DataNode的机器上, 其数量可以跟DataNode一样多。
3.1)ZooKeeper:
- 是一个高性能、集中化、分布式应用程序协调服务,它为HBase提供了分布式同步和组服务。 在HBase中,它用来选举集群主节点Master,以便跟踪可用的在线服务器,同时维护集群的 元数据。一般安装多个,用于提供Master的高可用性。
- 同时他保存Hbase的元数据。
四)HBase的数据模型
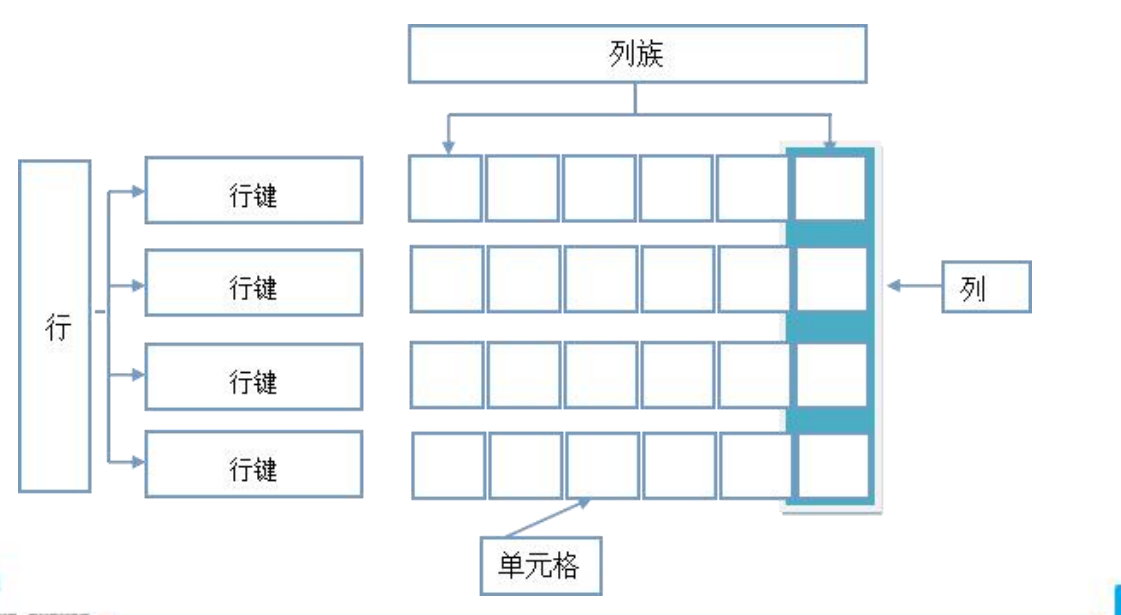
4.1)行键
这是HBase表中每个记录的唯一键,无论选择什么类型数据作为行健,它在内部、
磁盘或内存里,都将转换为字节数组进行存储。表中的每条数据有唯一的标识符,即rowkey,类似于关系型数据库的主键。
4.2)列族
一张HBase表由表的不同列集合在一起。将相同功能或类型的列分类组合在一起,这样做的好处是可以更快的分开存储在HBase磁盘上的列族中检索出所需的列。
4.3)列
列属于某一个column family列族。
4.4)列时间戳 timestamp
每个cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
五)Hbase的安装
5.1) 前提条件
安装ZK和hadoop
5.2)修改hadoop的配置文件
修改hbase-env.sh
#增加jdk的配置export JAVA_HOME=/opt/modules/jdk1.7.0_67#取消启动默认的zkexport HBASE_MANAGES_ZK=false
修改hbase-site.xml
<property><name>hbase.rootdir</name><value>hdfs://s0.song.com:9000/hbase</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.quorum</name><value>s0.song.com</value></property>
六)Hbase的启动
#启动hdfssbin/hadoop-daemon.sh start namenodesbin/hadoop-daemon.sh start datanodesbin/yarn-daemon.sh start resourcemanagersbin/yarn-daemon.sh start nodemanagersbin/mr-jobhistory-daemon.sh start historyserver#启动zk./zkServer.sh start#启动hbase#启动masterbin/hbase-daemon.sh start master#启动regionserverbin/hbase-daemon.sh start regionserver
#hbase命令的帮助bin/hbase
Usage: hbase [<options>] <command> [<args>]Options:--config DIR Configuration direction to use. Default: ./conf--hosts HOSTS Override the list in 'regionservers' fileCommands:Some commands take arguments. Pass no args or -h for usage.shell Run the HBase shellhbck Run the hbase 'fsck' toolhlog Write-ahead-log analyzerhfile Store file analyzerzkcli Run the ZooKeeper shellupgrade Upgrade hbasemaster Run an HBase HMaster noderegionserver Run an HBase HRegionServer nodezookeeper Run a Zookeeper serverrest Run an HBase REST serverthrift Run the HBase Thrift serverthrift2 Run the HBase Thrift2 serverclean Run the HBase clean up scriptclasspath Dump hbase CLASSPATHmapredcp Dump CLASSPATH entries required by mapreducepe Run PerformanceEvaluationltt Run LoadTestToolversion Print the versionCLASSNAME Run the class named CLASSNAME
七)Hbase的web访问地址
http://s0.song.com:60010/master-status
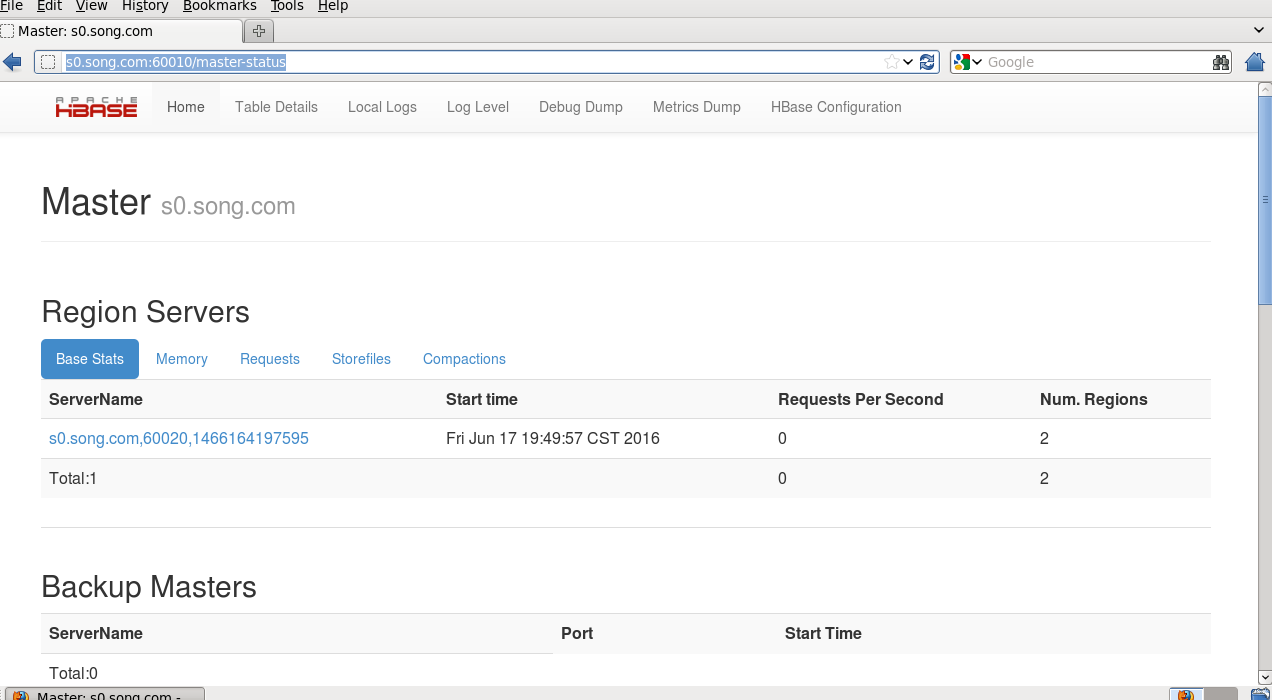
八)Hbase shell命令行的访问
基本的命令:
| 名称 | 命令表达式 |
|---|---|
| 创建表 | create '表名称', '列名称1','列名称2','列名称N' |
| 添加记录 | put '表名称', '行名称', '列名称:', '值' |
| 查看记录 | get '表名称', '行名称' |
| 查看表中的记录总数 | count '表名称' |
| 删除记录 | delete '表名' ,'行名称' , '列名称' |
| 删除一张表 | 先要屏蔽该表,才能对该表进行删除,第一步 disable '表名称' 第二步 drop '表名称' |
| 查看所有记录 | scan "表名称" |
| 查看某个表某个列中所有数据 | scan "表名称" , ['列名称:'] |
| 更新记录 | 就是重写一遍进行覆盖 |
例如如下的表:
学生表student,有两个列族:
- classinfo,班级信息,有两个列,classid和classname
- userinfo,个人信息,有两个列,name和age
运行bin/hbase shell进入shell模式
8.1)帮助信息
help命令
• 连接好HBase之后可使用help命令,回车后,屏幕上会显示HBase shell命令的一些基本用法,并有几个命令组。命令组(COMMAND GROUPS)包括:- 普通组:包含状态信息,表的帮助信息,帮助信息等方面的命令- ddl组:包括修改、创建、删除等数据定义语言方面的命令- dml组:包括添加、计数、删除、查询所有,获取部分信息等方面的数据操作语言方面的命令- namespace组:包括修改、创建、描述、删除命名空间等方面的命令- tools组:工具组命令- replication组命令- snapshots快照命令- security安全命令:包括授予、取消权限、用户许可方面的命令- visibility labels命令:包括添加label,清除、获取、设置认证等命令
8.2) 建表
create 'student','classinfo', 'userinfo'
8.3) 显示表信息
使用list命令来显示已创建好的所有表格信息或指定表格名的表格信息
语法格式如下:list 或list '表名'
例:list 'student'
8.4) 显示表格描述信息
语法格式如下:describe '表名'
例:describe 'student'
8.5) 显示表格描述信息
语法格式如下:describe '表名'
例:describe 'student'
8.6) 插入数据
#语法格式如下:put '表名','行键','列族:列名','值'#插入用户列族10001,班级1put 'student','10001','classinfo:classid','1'#插入用户列族10001,姓名zhangsanput 'student','10001','userinfo:name','zhangsan'put 'student','10002','userinfo:age','200'
8.7) 数据查询
8.7.1)依据rowkey使用get命令查询
#语法格式:get '表名','行键名'get 'student','10001'#语法格式:get '表名','行键名','列族:列名'get 'student','10002','userinfo:age'
8.7.2)使用scan命令全表查询
#语法格式如下:scan '表名'scan 'student'
8.7.3)使用scan命令查询表格中某范围数据
#语法格式如下:scan '表名',{COLUMN=>['列族:列名','列族:列名']}scan 'student',{COLUMN=>['classinfo:classid','userinfo:age']}#语法格式如下:scan '表名',{STARTROW=>'',ENDROW=>''}#STARTROW必须,ENDROW可以省略scan 'student',{STARTROW=>'10001',STARTROW=>'10002'}
8.7.4)删除命令
#删除表中某行键下的某列信息#语法格式如下:语法格式:delete '表名','行键名','列族:列名'delete 'student','10001','classinfo:classid'#删除表中某行键下的所有列信息#语法格式如下:语法格式:deleteall '表名','行键'deleteall 'student','10001'
8.7.4)删除表
#第一步 disable '表名称' 第二步 drop '表名称'disable 'student'drop 'student'
例如: get 'student','10001'
