@songlaf
2016-05-12T20:41:16.000000Z
字数 9854
阅读 1033
作业十【MapReduce高级应用练习】
北风网大数据培训
一)编码实现二次排序
1)MR的运行流程
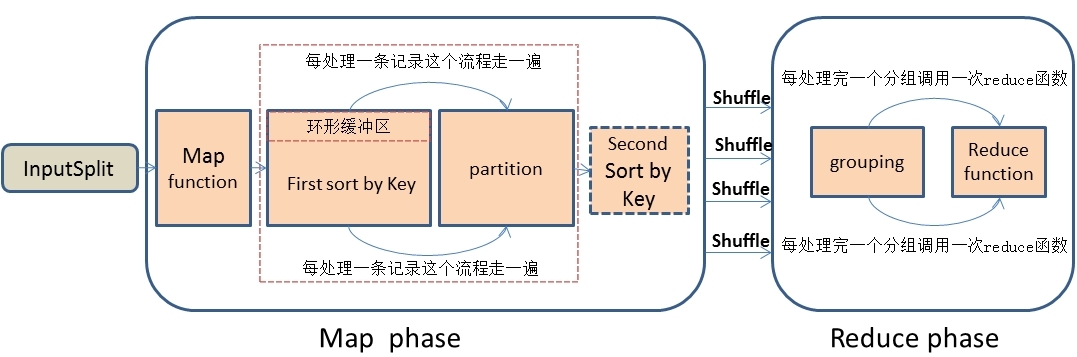
(a)Mapper任务会接收输入分片,调用map函数,对记录进行处理。处理完毕,转换为新的输出。
(b)对map函数输出的调用分区函数进行分区。不同分区的数据会被送到不同的Reducer任务中。
(c)对于不同分区的数据,会按照key进行排序,这里的key必须实现WritableComparable接口。该接口实现了Comparable接口,因此可以进行比较排序。
(d)对于排序后的,会按照key进行分组。如果key相同,那么相同key的就被分到一个组中。最终,每个分组会调用一次reduce函数。
(e)排序、分组后的数据会被送到Reducer节点。
2)二次排序
MR默认会对键进行排序,然而有的时候我们也有对值进行排序的需求。满足这种需求一是可以在reduce阶段排序收集过来的values,但是,如果有数量巨大的values可能就会导致内存溢出等问题,所以我们可以把Key和需要排序的字段组合生成一个新的key,我们可以称之为newKey,再map段用newKey进行处理。
在分区分组的过程中,如果继续是用newKey,那么分区分组的数量就会变得很多,分区分组会消耗大量的资源,这个时候可以修改分区分组的规则,采用原来的key进行分区分组。
3) 实现代码
3.1)自定义newKey
package njt.song.study.hadoop;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;import org.apache.hadoop.io.WritableComparable;public class PairWritable implements WritableComparable<PairWritable> {public PairWritable() {super();}public PairWritable(String first, int second) {super();this.first = first;this.second = second;}public void Set(String first, int second) {this.setFirst(first);this.setSecond(second);}public String getFirst() {return first;}public void setFirst(String first) {this.first = first;}public int getSecond() {return second;}public void setSecond(int second) {this.second = second;}private String first;private int second;@Overridepublic void readFields(DataInput in) throws IOException {// TODO Auto-generated method stubthis.setFirst(in.readUTF());this.setSecond(in.readInt());}@Overridepublic void write(DataOutput out) throws IOException {// TODO Auto-generated method stubout.writeUTF(this.getFirst());out.writeInt(this.getSecond());}@Overridepublic int compareTo(PairWritable o) {int comp = this.getFirst().compareTo(o.getFirst());if(0 != comp){return comp;}return Integer.valueOf(this.getSecond()).compareTo(Integer.valueOf(o.getSecond()));}@Overridepublic String toString() {// TODO Auto-generated method stubreturn this.getFirst() + "," + this.getSecond();}}
3.2)自定义分区类
package njt.song.study.hadoop;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.mapreduce.Partitioner;public class FirstPartitioner extends Partitioner<PairWritable, IntWritable> {@Overridepublic int getPartition(PairWritable key, IntWritable value,int numPartitions) {return (key.getFirst().hashCode() & Integer.MAX_VALUE) % numPartitions;}}
3.3) 自定义分组类
package njt.song.study.hadoop;import org.apache.hadoop.io.RawComparator;import org.apache.hadoop.io.WritableComparator;public class FirstGroupCompair implements RawComparator<PairWritable> {@Overridepublic int compare(PairWritable o1, PairWritable o2) {// TODO Auto-generated method stubreturn o1.getFirst().compareTo(o2.getFirst());}@Overridepublic int compare(byte[] b1, int s1, int l1, byte[] b2, int s2,int l2) {return WritableComparator.compareBytes(b1, 0, l1 -4, b2, 0, l2-4);}}
3.4) MR程序
package njt.song.study.hadoop;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;public class WordCount extends Configured implements Tool {public static class WordCountMapper extends Mapper<Object,Text,PairWritable,IntWritable> {private IntWritable outPutValue = new IntWritable();private PairWritable outPutKey = new PairWritable();protected void map(Object key, Text value, Context context)throws IOException, InterruptedException {String line = value.toString();String[] words = line.split(",");outPutKey.Set(words[0], Integer.valueOf(words[1]));outPutValue.set(Integer.valueOf(words[1]));context.write(outPutKey, outPutValue);}}public static class WordCountReducer extends Reducer<PairWritable,IntWritable,Text,IntWritable> {private Text outPutkey = new Text();@Overrideprotected void reduce(PairWritable key, Iterable<IntWritable> values,Context context)throws IOException, InterruptedException {outPutkey.set(key.getFirst());for(IntWritable value:values){context.write(outPutkey, value);}}}public static void main(String[] args) throws Exception{Configuration conf = new Configuration();int status = ToolRunner.run(conf, new WordCount(),args);System.exit(status);}public int run(String[] args) throws Exception {Configuration configuration = super.getConf();Job job = Job.getInstance(configuration,this.getClass().getSimpleName());job.setJarByClass(WordCount.class);Path inPath = new Path(args[0]);FileInputFormat.addInputPath(job, inPath);job.setMapperClass(WordCountMapper.class);job.setMapOutputKeyClass(PairWritable.class);job.setMapOutputValueClass(IntWritable.class);job.setPartitionerClass(FirstPartitioner.class);job.setGroupingComparatorClass(FirstGroupCompair.class);job.setReducerClass(WordCountReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);Path outPath = new Path(args[1]);FileOutputFormat.setOutputPath(job, outPath);boolean isSuccess = job.waitForCompletion(true);return isSuccess ? 0 : 1;}}
3.5)运行
#打包成SecondSortjar.jarbin/yarn jar /home/sjf/SecondSortjar.jar /input/word1.txt /Out21
#执行之前内容i,20b,1c,40a,10b,20c,300#执行之后内容a 10b 1b 20c 40c 300i 20
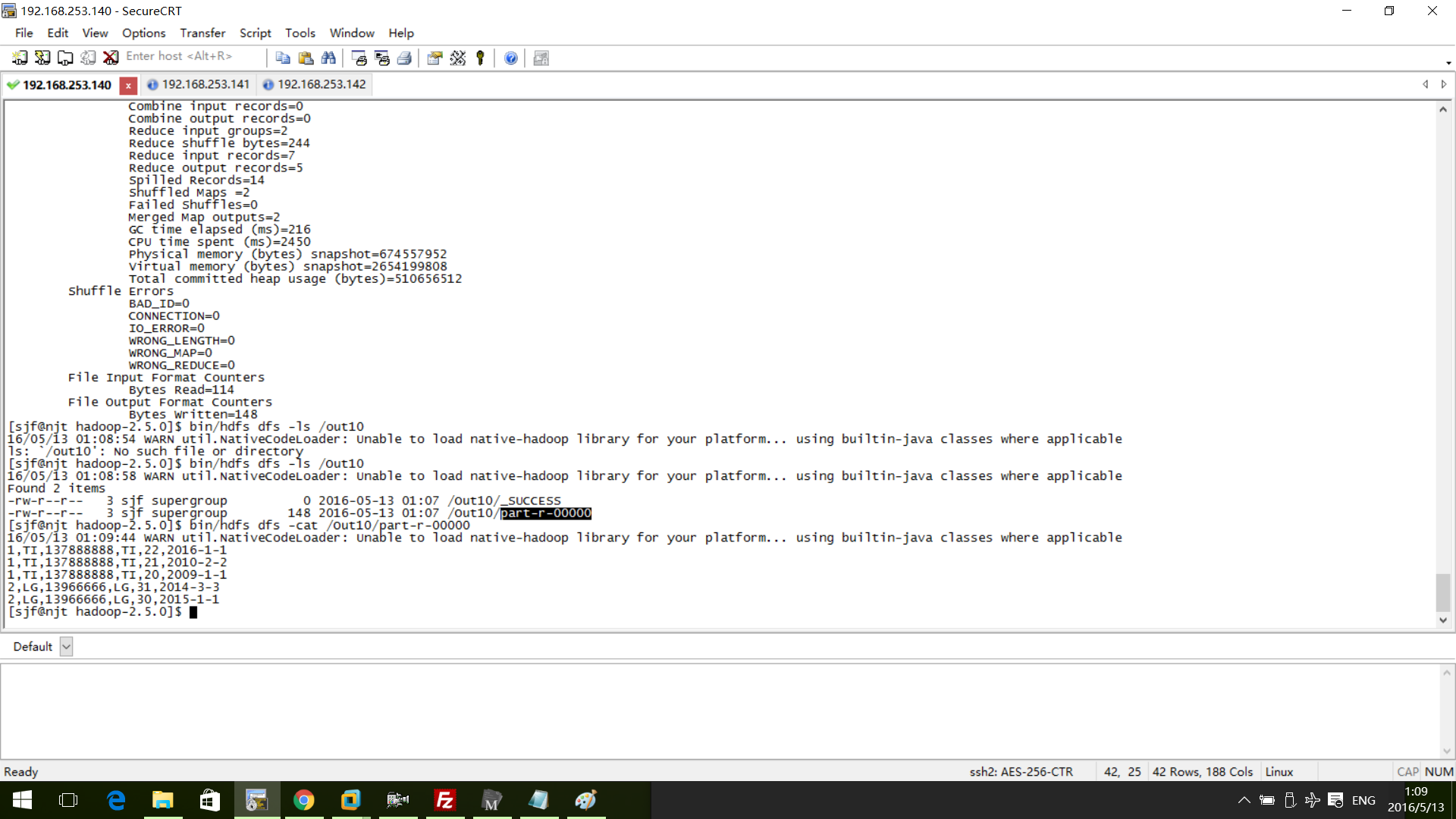
执行过程截图:
二)编码实现Join
1)Join的三种方式
1.1) reduce join
连接在Reduce端进行,适合大表对大表的连接,根据key把来自于不同文件的数据根据相同的Key,把Value连接在一起。
1.2) map join
在map段进行,两个文件一大一小,小的占用的资源比较少,可以放到内存中执行,采用DistributedCache来实现。遍历大表,从内存中的小表根据key找到匹配的数据,在reduce几乎没有任何改变。
1.3) Semi Join
SemiJoin,也叫半连接,综合Reduce join和Map join的优点,map端和reduce端都用到。对于reduce端的join,跨机器的数据传输量非常大,为了提高性能,先在map端滤掉不参加Join的数据,留下那些需要Join的数据到Reduce端进行处理。reduce端的处理和reduce join几乎相同。
2)Join的代码实现
2.1)实现原理
在map阶段,map函数同时读取多个文件,为了区分来多个文件的Key/Value,对每条数据打一个标签(tag),在reduce阶段,reduce函数根据tag区分来自不同文件的数据,然后根据相同的Key对value list进行Join连接。
2.2)实现代码
2.2.1) Tag类
package njt.song.study.hadoop;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;import org.apache.hadoop.io.Writable;public class DataJoinWritable implements Writable {private String tag;private String data;public DataJoinWritable() {super();}public void Set(String tag, String data) {this.tag = tag;this.data = data;}public String getTag() {return tag;}public void setTag(String tag) {this.tag = tag;}public String getData() {return data;}public void setData(String data) {this.data = data;}@Overridepublic String toString() {// TODO Auto-generated method stubreturn "DataJoinWritabble Tag = [" + this.getTag() + "],Data =[" + this.getData() + "]";}@Overridepublic void readFields(DataInput in) throws IOException {// TODO Auto-generated method stubthis.setTag(in.readUTF());this.setData(in.readUTF());}@Overridepublic void write(DataOutput out) throws IOException {// TODO Auto-generated method stubout.writeUTF(this.getTag());out.writeUTF(this.getData());}}
2.2.2) MR程序
package njt.song.study.hadoop;import java.io.IOException;import java.util.ArrayList;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;public class WordCount extends Configured implements Tool {public static class WordCountMapper extends Mapper<LongWritable,Text,LongWritable,DataJoinWritable> {private DataJoinWritable outPutValue = new DataJoinWritable();private LongWritable outPutKey = new LongWritable();protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {String[] words = value.toString().split(",");if(words.length != 3 && words.length != 4){return;}Long id = Long.valueOf(words[0]);outPutKey.set(id);String name = words[1];if(words.length == 3){String phone = words[2];outPutValue.Set("customer", name + "," + phone);}else if(words.length == 4) {String price = words[2];String date = words[3];outPutValue.Set("order", name + "," + price + "," + date);}System.out.print("****Map********" + outPutKey.toString());context.write(outPutKey, outPutValue);}}public static class WordCountReducer extends Reducer<LongWritable,DataJoinWritable,NullWritable,Text> {private Text outPutValue = new Text();@Overrideprotected void reduce(LongWritable key,Iterable<DataJoinWritable> values, Context context)throws IOException, InterruptedException {String customerInfo = new String();ArrayList<String> orderList = new ArrayList<String>();for(DataJoinWritable value :values){System.out.print("****Reduce********" + value.toString());if(value.getTag().equals("customer")){customerInfo = value.getData();}else if(value.getTag().equals("order")){orderList.add(value.getData());}}for(String order:orderList){outPutValue.set(key.toString()+","+customerInfo+"," + order);context.write(NullWritable.get(), outPutValue);}}}public static void main(String[] args) throws Exception{Configuration conf = new Configuration();int status = ToolRunner.run(conf, new WordCount(),args);System.exit(status);}public int run(String[] args) throws Exception {Configuration configuration = super.getConf();Job job = Job.getInstance(configuration,this.getClass().getSimpleName());job.setJarByClass(WordCount.class);Path inPath = new Path(args[0]);FileInputFormat.addInputPath(job, inPath);job.setMapperClass(WordCountMapper.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(DataJoinWritable.class);job.setReducerClass(WordCountReducer.class);job.setOutputKeyClass(NullWritable.class);job.setOutputValueClass(Text.class);Path outPath = new Path(args[1]);FileOutputFormat.setOutputPath(job, outPath);boolean isSuccess = job.waitForCompletion(true);return isSuccess ? 0 : 1;}}
2.2.3) 运行
#打包成jar文件,然后执行bin/yarn jar /home/sjf/datajoin.jar /orderinfo /Out10
执行之前的数据
#customer数据1,TI,1378888882,LG,13966666#order数据1,TI,20,2009-1-11,TI,21,2010-2-21,TI,22,2016-1-12,LG,30,2015-1-12,LG,31,2014-3-3#执行结果1,TI,137888888,TI,22,2016-1-11,TI,137888888,TI,21,2010-2-21,TI,137888888,TI,20,2009-1-12,LG,13966666,LG,31,2014-3-32,LG,13966666,LG,30,2015-1-1
执行过程