@songlaf
2016-05-18T17:54:34.000000Z
字数 1721
阅读 1050
作业十二、【Hive功能架构】
北风网大数据培训
一)Hive概念
Hive是在Hadoop基础之上数据仓库工具,它把HDFS的结构化的数据映射成一系列的表,提供类似于Sql的功能来读取和分析HDFS上的数据,用MapReduce来计算,资源分配是通过Yarn来执行。
Hive本身是没有专门的数据存储格式,也没有为数据建立索引,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。所以往Hive表里面导入数据只是简单的将数据移动到表所在的目录中(如果数据是在HDFS上;但如果数据是在本地文件系统中,那么是将数据复制到表所在的目录中)。
特点:
- 使用HDFS来存储数据,Hive本身本身是不存储数据。
- Hive没有专门的数据存储格式
- 主要的存储结构包括:数据库,文件,表,视图
- Hive默认可以加载文本文件,SequenceFile,RCFile
- 创建表时,指定Hive数据的列分隔符和行分隔符,Hive既可解析数据。
二)Hive的架构
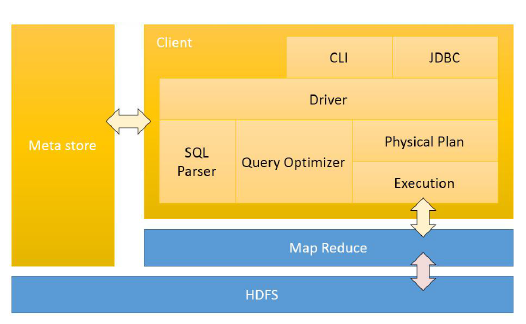
- 客户端通过CLI或者JDBC来访问和计算数据,Hive客户端把任务丢给MapReduce来处理,所以Hive不存在集群的概念,可以把Hive当做一个服务端,让别的程序来调用。
- 元数据,包括数据库名,表明,字段等,一般是放在关系型号数据库。元数据记录Hive对HDFS数据的定义,当客户端提交一条Hive SQL语句的时候,根据元数据把语句翻译成MapReduce程序,丢给MarpReduce来执行
- HDFS,负责存储数据。
三)Hive的数据模型
Hive中主要包含以下几种数据模型:Table(表),External Table(外部表),Partition(分区),Bucket(桶)(本博客会专门写几篇博文来介绍分区和桶)。
3.1)表
Hive中的表和关系型数据库中的表在概念上很类似,每个表在HDFS中都有相应的目录用来存储表的数据,这个目录可以2过${HIVE_HOME}/conf/hive-site.xml配置文件中的hive.metastore.warehouse.dir属性来配置,这个属性默认的值是/user/hive/warehouse(这个目录在HDFS上),我们可以根据实际的情况来修改这个配置。如果我有一个表wyp,那么在HDFS中会创建/user/hive/warehouse/wyp目录(这里假定hive.metastore.warehouse.dir配置为/user/hive/warehouse);wyp表所有的数据都存放在这个目录中。这个例外是外部表。
3.2)外部表
该外部表所指向的数据是不会被删除的,它只会删除外部表对应的元数据;而如果你要删除表,该表对应的所有数据包括元数据都会被删除。
3.3)分区
在Hive中,表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中。比如wyp表有dt和city两个分区,则对应dt=20131218,city=BJ对应表的目录为/user/hive/warehouse/dt=20131218/city=BJ,所有属于这个分区的数据都存放在这个目录中。
3.4)桶
对指定的列计算其hash,根据hash值切分数据,目的是为了并行,每一个桶对应一个文件(注意和分区的区别)。比如将wyp表id列分散至16个桶中,首先对id列的值计算hash,对应hash值为0和16的数据存储的HDFS目录为:/user/hive/warehouse/wyp/part-00000;而hash值为2的数据存储的HDFS 目录为:/user/hive/warehouse/wyp/part-00002。
四)Hive的优点
- 操作接口类似SQL语法,可以快速开发。
-避免用Java开发MapReduce代码。
-统一的元数据管理,可与impala/sparak等共享数据。
-易于扩展,HDFS+MapReduce可以扩展集群规模,可以自定义数据(UTF)
-数据离线处理;比如日志分析,海量结构化数据的离线分析,
-Hive执行的延迟比较高,因此Hive场用于数据分析,对实时性要求不高的场景。
-Hive的优势在于处理大数据,对小的数据没有优势。
