@songlaf
2016-05-29T04:25:45.000000Z
字数 3970
阅读 938
Hadoop笔记
Hadoop
一)hadoop
1.1)Name Node,Data Node
| NameNode | DataNode |
|---|---|
| 存储元数据 | 存储文件内容 |
| 元数据保存在内存中 | 文件内容保存在磁盘中 |
| 保存文件、block、datanode之间的映射关系 | 维护了block id到datanode本地文件的映射关系 |
- 一个NameNode和多个DataNode
- 数据复制(冗余机制)--存放位置,机架感知策略
- 故障检测
--数据节点
心跳包(检测是否宕机)
块报告(安全模式下检测)
数据完整性检测(检测和比较)
--名称节点(日志文件,镜像文件)
- 空间回收机制
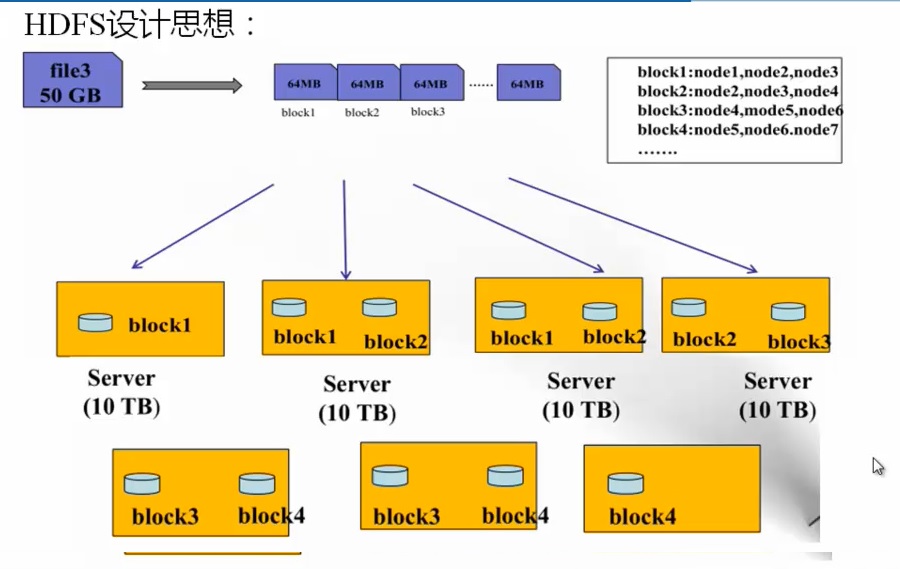
1.2)HDFS设计思想
1.3)HDFS的设计架构
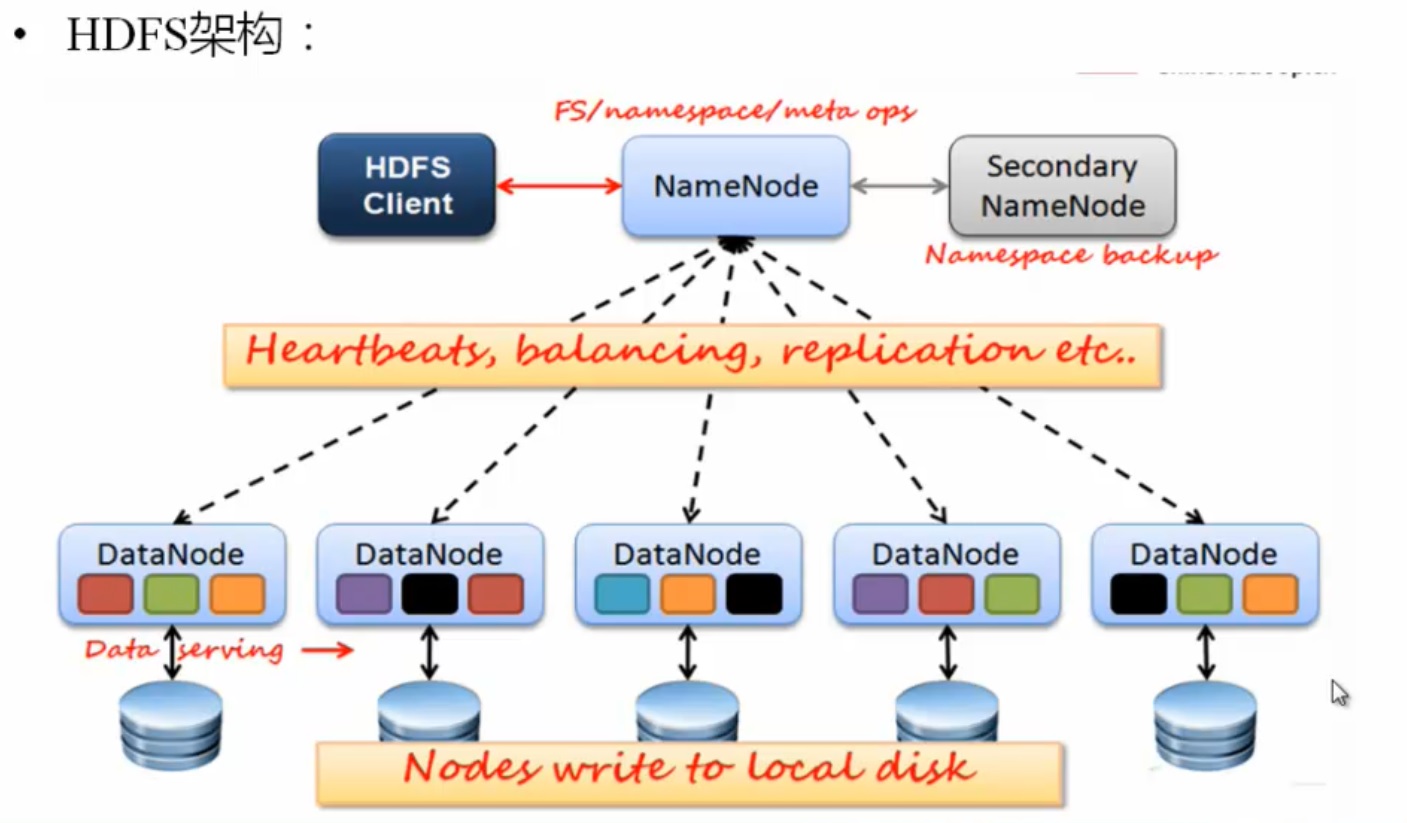
1.3.1)NameNode (NN)
--主要功能:接受客户端的读写服务
--保存的元数据信息包括,
i)文件的owership和permissions
ii)文件包含哪些块
iii)Block保存在那个DataNode(由DataNode上报)
--NameNode的元数据信息启动时候回加载到内存
i)metadata存储到磁盘文件名fsimage,
dn不会存在文件名,只存在 block。
ii)block位置信息不会保存到fsimage,重启之后dn会报告。
iii)edits记录对应metadata的操作日志,新增或者删除的文件,是保存到edits文件,某段时间跟fsimage和edit文件合并。
1.3.2)Secondary NameNode (SNM)
i)不是NM的备份(但可以做备份),主要是帮助NM合并edits log,减少NM启动时间
ii)SNM的合并时间
a)根据配置文件的时间间隔fs.checkpoint.perios,默认3600秒
b)根据配置文件edits log的大小fs.checkpoint.size规定edits文件的大小,默认值是64M
合并的流程
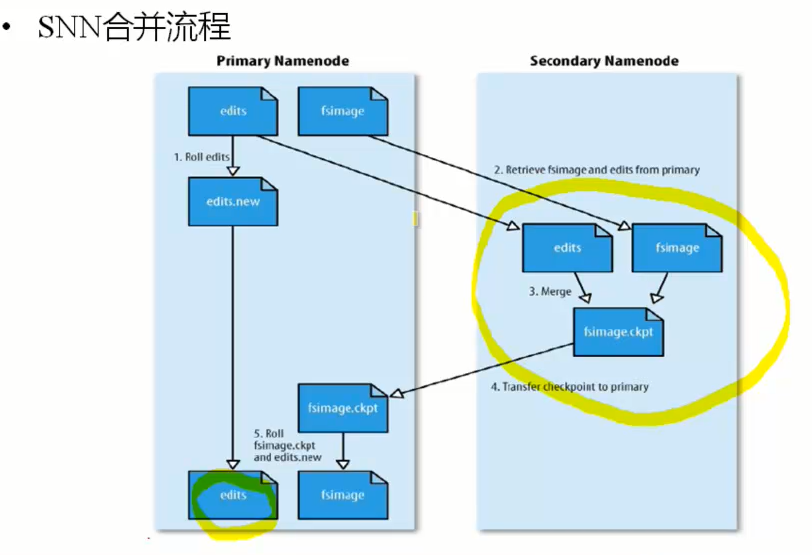
SNM从NM拷贝image和edits数据去合并,NM重新生成一个新的edits文件,因为合并的时候,nm还在继续运行。
当SNM合并结束会拷贝到NM替换掉就的image数据。
所以SNM可以部分代替NM,是因为当NM宕机之后,SNM拷贝过去之后的操作找不到了。
1.3.3)DateNode (DN)
功能
-存储数据
-启动DN县城的时候想NM汇报block信息
--通过向NM发送心跳保存语气联系(3秒一次),如果NM10分钟没有收到DN的心跳,人为其已经丢失,并copy骑上的block到其他的DN。
block存放策略
-第一副本:放置文件上传的DN,
如果是集群,那么随机挑选一台磁盘不太满,cpu不带忙的节点。
-第二副本:于第一个副本不同的机架(机架相邻要配置到配置文件中)
-第三副本:于第二个副本相同的机架
-更对哦副本:随机节点
1.3.4)HDFS的读流程
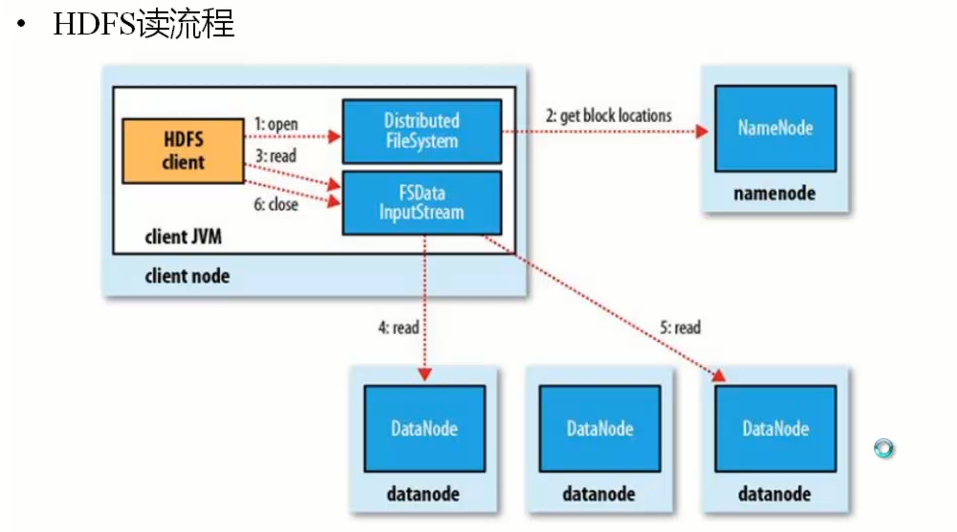
从NM获取block信息,返回block信息,
然后client并发去DN去读取文件,然后文件合并。
?????????注意如果大型文件,合并会消耗时间。
1.3.4)HDFS的写流程
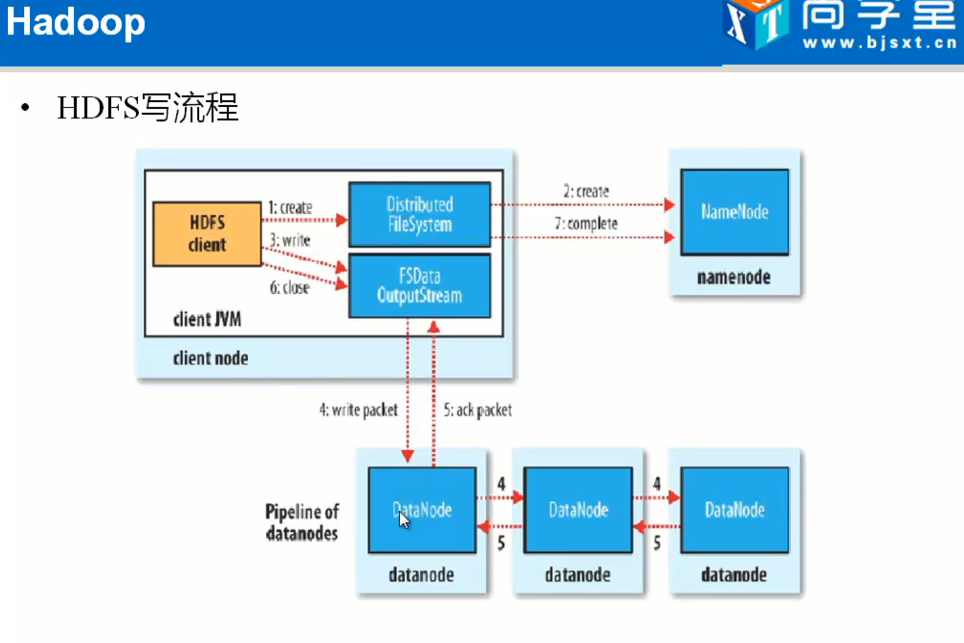
Client,提交请求,NM返回文件要切成多少block,然后返回block id 到client,
然后client向一个dn传送数据,传送完成dn想备份的dn传送。
当全部的传送结束之后关闭掉。
有DN1转DN2有点是因为速度快。
1.3.5)HDFS文件的权限

1.3.6)HDF安全模式

二)hadoop的安装
1)HDFS配置文件的属性
```xml
fs.default.name
hdfs://localhost:9000
置namenode和datanode的存放位置,默认就放在这个路径中-->
hadoop.tmp.dir
/home/hdfs/tmp
dfs.replication
1
<!-- dfs.data.dir - 这是DataNode结点被指定要存储数据的本地文件系统路径。DataNode结点上 的这个路径没有必要完全相同,因为每台机器的环境很可能是不一样的。但如果每台机器上的这 个路径都是统一配置的话,会使工作变得简单一些。默认的情况下,它的值hadoop.tmp.dir, 这 个路径只能用于测试的目的,因为,它很可能会丢失掉一些数据。所以,这个值最好还是被覆 盖。
dfs.name.dir - 这是NameNode结点存储hadoop文件系统信息的本地系统路径。这个值只对NameNode有效,DataNode并不需要使用到它。上面对于/temp类型的警告,同样也适用于这里。在实际应用中,它最好被覆盖掉。-->
dfs.name.dir
/home/hdfs/name
dfs.data.dir
/home/hdfs/data
<!—解决:org.apache.hadoop.security.AccessControlException:Permission denied:user=Administrator,access=WRITE,inode="tmp":root:supergroup:rwxr-xr-x 。
因为Eclipse使用hadoop插件提交作业时,会默认以 DrWho 身份去将作业写入hdfs文件系统中,对应的也就是 HDFS 上的/user/hadoop , 由于 DrWho 用户对hadoop目录并没有写入权限,所以导致异常的发生。解决方法为:放开 hadoop 目录的权限, 命令如下 :$ hadoop fs -chmod 777 /user/hadoop -->
dfs.permissions
false
If "true", enable permission checking in HDFS. If "false", permission checking is turned off, but all other behavior is unchanged. Switching from one parameter value to the other does not change the mode, owner or group of files or directories
</property>
- 在conf/mapred-site.xml中增加如下内容:
mapred.job.tracker
localhost:9001
二、操作命令
1. 格式化工作空间
进入bin目录,运行 ./hadoop namenode –format
2. 启动hdfs
进入hadoop目录,在bin/下面有很多启动脚本,可以根据自己的需要来启动。
* start-all.sh 启动所有的Hadoop守护。包括namenode, datanode, jobtracker, tasktrack
- stop-all.sh 停止所有的Hadoop
- start-mapred.sh 启动Map/Reduce守护。包括Jobtracker和Tasktrack
- stop-mapred.sh 停止Map/Reduce守护
- start-dfs.sh 启动Hadoop DFS守护Namenode和Datanode
- stop-dfs.sh 停止DFS守护
三、Hadoop hdfs 整合
可按如下步骤删除和更改hdfs不需要的文件:
1.将hadoop-core-1.0.0.jar 移动到lib目录下。
- 将ibexec目录下的文件移动到bin目录下。
- 删除除bin、lib、conf、logs之外的所有目录和文件。
- 如果需要修改日志存储路径,则需要在conf/hadoop-env.sh文件中增加:
export HADOOP_LOG_DIR=/home/xxxx/xxxx即可。
四、HDFS文件操作
Hadoop使用的是HDFS,能够实现的功能和我们使用的磁盘系统类似。并且支持通配符,如*。
- 查看文件列表
查看hdfs中/user/admin/hdfs目录下的文件。
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -ls /user/admin/hdfs
查看hdfs中/user/admin/hdfs目录下的所有文件(包括子目录下的文件)。
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -lsr /user/admin/hdfs - 创建文件目录
查看hdfs中/user/admin/hdfs目录下再新建一个叫做newDir的新目录。
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -mkdir /user/admin/hdfs/newDir - 删除文件
删除hdfs中/user/admin/hdfs目录下一个名叫needDelete的文件
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -rm /user/admin/hdfs/needDelete
删除hdfs中/user/admin/hdfs目录以及该目录下的所有文件
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -rmr /user/admin/hdfs - 上传文件
上传一个本机/home/admin/newFile的文件到hdfs中/user/admin/hdfs目录下
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs –put /home/admin/newFile /user/admin/hdfs/ - 下载文件
下载hdfs中/user/admin/hdfs目录下的newFile文件到本机/home/admin/newFile中
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs –get /user/admin/hdfs/newFile /home/admin/newFile - 查看文件内容
查看hdfs中/user/admin/hdfs目录下的newFile文件
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs –cat /home/admin/newFile
- 查看文件列表
