@songlaf
2016-05-19T15:54:16.000000Z
字数 3710
阅读 962
作业十四、【Hive表的创建及测试】
北风网大数据培训
一)Hive命令的执行方式
执行Hive Sql有两种方式
- 用bin/hive命令进入Hive的Hive SQL控制台执行
- 可以使用bin/hive命令,常用的参数有e和f。
#-e 后面带sql语句,例如:bin/hive -e 'show databases'#-f 后面带文件,文件中是SQL语句#文本文件test.sql,内容是:use db_s9;show tables;#执行该sql文件bin/hive -f test.sql#执行该sql文件,结构写入log.txt文件bin/hive -f test.sql > log.txt#-hiveconf 修改当前会话的环境参数(默认在hive-site.xml配置)bin/hive --hiveconf hive.root.logger=INFO,DRFA#set命令可以查看当前参数的信息。set#hive环境可以直接使用hdfs的命令,只是前面少了bin/hdfs#例如查看/user/hive/warehouse下的内容dfs -ls /user/hive/warehouse#!可以直接执行系统命令,例如,查看home的内容! ls /home#查看历史sql~/.hivehistory
二)Hive的基本数据类型
2.2.1 基础数据类型
| 数据类型 | 描述 | 开始支持版本 |
|---|---|---|
| TINYINT | 1byte,-128 ~ 127 | |
| SMALLINT | 2byte,-32,768 ~ 32,767 | |
| INT | 4byte,-2,147,483,648 ~ 2,147,483,647 | |
| BIGINT | 8byte,-9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | |
| BOOLEAN | true/false | |
| FLOAT | 4byte单精度 | |
| DOUBLE | 8byte双精度 | |
| STRING | ||
| BINARY | 从Hive0.8.0开始支持 | |
| TIMESTAMP | 从Hive0.8.0开始支持 | |
| DECIMAL | 从Hive0.11.0开始支持 | |
| CHAR | 从Hive0.13.0开始支持 | |
| VARCHAR | 从Hive0.12.0开始支持 | |
| DATE | 从Hive0.12.0开始支持 |
2.2.1 复杂数据类型
| 数据类型 | 描述 | 开始支持版本 |
|---|---|---|
| ARRAY | ARRAY类型是由一系列相同数据类型的元素组成,这些元素可以通过下标来访问。比如有一个ARRAY类型的变量fruits,它是由['apple','orange','mango']组成,那么我们可以通过fruits1来访问元素orange,因为ARRAY类型的下标是从0开始的 | Array(1,2) |
| MAP | MAP包含key->value键值对,可以通过key来访问元素。比如”userlist”是一个map类型,其中username是key,password是value;那么我们可以通过userlist['username']来得到这个用户对应的password | Map('a',1,'b',2) |
| STRUCT | STRUCT可以包含不同数据类型的元素。这些元素可以通过”点语法”的方式来得到所需要的元素,比如user是一个STRUCT类型,那么可以通过user.address得到这个用户的地址 | Struct('a',1,1,0) |
| UNION | 从Hive 0.7.0开始支持的 |
三)database相关的操作
create database if not exists song_test_dbcomment 'my test data base'with dbproperties('creator'='song','date'='2016-05-18')#数据库键值对属性信息location '/my/preferred/directory';#可以不用默认的location在/user/hive/warehouse下#Hive会在目录下建立一个跟数据库名称相同的文件夹#查看数据库的描述信息和文件目录位置路径信息describe database song_test_db;#查看数据库的描述信息和文件目录位置路径信息(加上数据库键值对的属性信息)describe database extended song_test_db;--删除数据库#drop database if exists song_test_db1;--级联删除数据库(当数据库还有表时,级联删除表后在删除数据库),默认是restrict#drop database if exists song_test_db cascade;#修改数据库#只能修改数据库的键值对属性值。数据库名和数据库所在的目录位置不能修改alter database song_test_db set dmproperties('creator'='Zhangsan');
四)表的操作
4.1) 创建表的三种方式
4.1.1)直接Sql语句
create table userinfo(id int,UserName string,Password string)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
显示表结构
desc userinfo
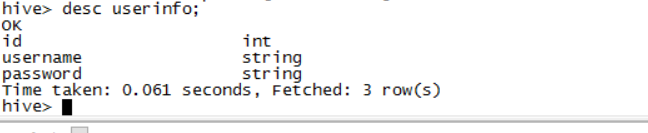
插入数据
#文件employee.txtchael| Montreal, Toronto| Male, 30| DB: 80| Product: Developer^DLeadWill| Montreal| Male, 35| Perl: 85| Product: Lead, Test: LeadShelley| New York| Female, 27| Python: 80| Test: Lead, COE: ArchitectLucy| Vancouver| Female, 57| Sales: 89, HR: 94| Sales: Lead
LOAD DATA LOCAL INPATH '/home/sjf/u.txt' OVERWRITE INTO TABLE userinfo;
4.1.2)用一张已经存在的表,创建另外一张表
create table userinfo_new as select id,username from userinfo;
执行结果
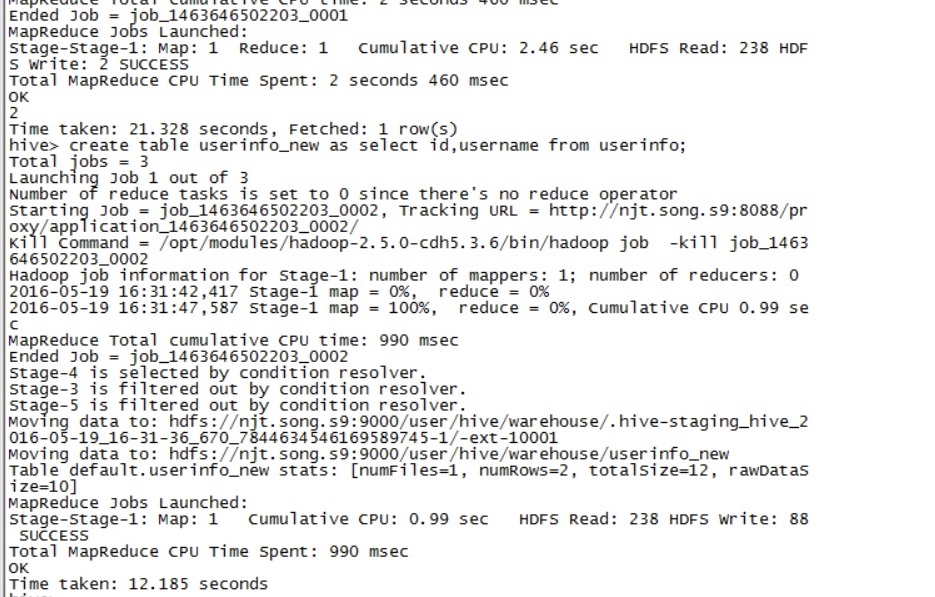
数据
4.1.3)用like关键之,只会产生表的结构,而不生成表的数据
create table userinfo_new2 like userinfo;
执行结果,可以看出,userinfo_new2表中并没有数据
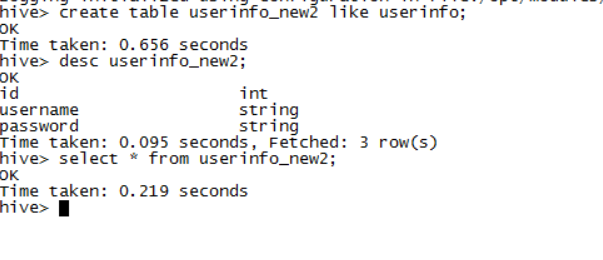
4.2) 内部表和外部表
内部表的数据存放在HIVE数据仓库的位置,删除的时候,文件也元数据一起删除。
而外部表,放到指定的HDFS目录,当删除的时候,只删除元数据,而数据文件并不删除。
外部表使用的场合,通常是在不同的业务场景,要实用同样一份数据,在一个业务中删除了数据,
而不影响其他的业务。
#创建外部表CREATE EXTERNAL TABLE countrycode(code string, name string)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','LOCATION '/external_workspace'#插入数据load data local inpath "/home/sjf/country.txt" into table countrycode;#查看external_workspace目录的文件bin/hdfs dfs -ls /external_workspace#显示结果如下:-rwxr-xr-x 1 sjf supergroup 21 2016-05-19 16:59 /external_workspace/country.txt#删除countrycode表,drop table countrycode#查看external_workspace目录的文件,数据仍然在bin/hdfs dfs -ls /external_workspace
4.3) 分区表
分区表是把部分字段提取出来,创建一个文件夹,可以减少文件的大小,可以提高查询速度。
create table partition_test(id string,name string)partitioned by (Sex string,Age string)row format delimited fields terminated by ',';
# 创建一个分区alter table partition_test add partition (Sex='F',Age='18');#然后发现在多了一个/user/hive/warehouse/test.db/partition_test/sex=F/age=18的目录#插入数据需要提供分区load data local inpath "/home/sjf/P1.txt" into table partition_test partition(sex='M',age=20);load data local inpath "/home/sjf/P2.txt" into table partition_test partition(sex='F',age=21);#分区表的查询select sex,age,id from partition_test;
在HDFS可以看到文件根据不同的partition存放到不同的目录

