@myecho
2019-03-28T01:50:16.000000Z
字数 19464
阅读 2455
疯狂java讲义笔记
Java
数据类型和运算符
java中的数据类型仅包含基本数据类型和引用类型两种,null只可用于引用类型

java中的整数值有4种表示方式:十进制、二进制、八进制、十六进制。其中二进制的开头是以ob或者0B开头,八进制整数开头以0表示,十六进制的整数开头以0X或者0X开头,其中10~15分别以a~f来表示
java使用16位的unicode字符集作为编码方式
java语言的浮点数有两种表示形式:
十进制数形式:这种形式就是简单的浮点数,例如5.12等,浮点数必须包含一个.,否则会被当做int类型处理
科学计数法形式:例如5.12e2,5.12E2,必须指出的是只有浮点数可以使用科学计数法进行表示
java还提供了三个特殊的浮点数值,正无穷大、负无穷大和非数,用于表示溢出和出错,所有的正无穷大数值都是相等的,所有的负无穷大数值都是相等的,而NaN不与任何数值相等
当程序中数值位数特别多时,java7允许在数值使用下划线来便于标识出数值的位数
基本类型的类型转换

System.out.println('a'+7+"Hello!") //输出为104Hello!
如果除法运算符的两个操作数都是整数类型,则计算结果也是整数,就是将自然除法的结果截断取整,并且除数不能为0,但如果两个操作数中有一个是操作数,或者两个都是浮点数,则计算结果也是浮点数,而且此时允许除数为0或者0.0,得到的结果是正无穷大或者负无穷大。
%操作时如果第二个操作数是0或者0.0,则结果是非数,且必须两个操作数中有一个为浮点数。
java中的位运算
总共有7种位运算符:& | ~ ^ << >> >>> 最后一个代表无符号右移,计算机中的二进制总是以补码来表示,进行移位运算时还要遵循以下规则:
1. 对于低于int类型的操作数总是先自动类型转换为int再进行移位
2. 对于int类型的整数移位a>>b,当b>32时,系统先对32求余,然后再进行移位
3. 对于long类型的整数移位a>>b,当b>64时,系统先对64求余
==运算:如果比较的两个操作数都是数值类型,即使他们的数据类型不同,只要他们的值相等,也都将返回true,例如97 == 'a',如果两个操作数都是引用类型,那么只有当两个操作数类型具有父子关系时才可比较,并且这两个引用必须指向同一个对象才回返回true。
在逻辑运算符中包括: && & || | ! ^其中&与|均是不短路的操作符
运算符的优先级

switch语句后的表达式支持byte short char int 枚举类型以及String(java7中增强)
数组
初始化
1. 静态初始化 arrayName = new type[]{element1, element2}
2. 动态初始化 arrayName = new type[5];//系统默认初始值
Arrays类
import java.util.Arrays;
本身还有sort、fill、copyOf、toString等增强数组的方法,在Java8中添加了如parallelSort等充分利用cpu并行能力的方法。
面向对象
- java中有一些默认导入的包如java.lang
- import static用于导入静态函数和静态变量,这样当使用时可以直接省略掉类名而进行引用
初始化
局部变量声明以后,Java 虚拟机不会自动的为它初始化为默认值。
final变量必须进行初始化。否则就会报编译错误。The blank final field field_d5 may not have been initialized
static成员变量的初始化发生在类被类加载器(classLoader)加载的时候系统会对没有初始化的静态成员变量在静态区进行默认赋值。
普通成员变量的初始化发生在JVM为类生成实例开辟空间的时候进行默认初始化赋值。

上图中数组元素会被默认初始化为0,而b不会被初始化
List test = new ArrayList<>(5); 这里的5只是声明最大容量,并不会真正的开辟空间
List tmp; //局部变量都不可以
System.out.println(tmp);
重载和重写
重载需要保证两同一不同,两同指的是同一个类中方法名相同,参数列表不同。至于方法的其他部分,如方法返回值类型、修饰符等,与方法重载没有关系。
方法的重写要遵循"两同两小一大"规则,"两同"即方法名相同、形参列表相同;"两小"指的是子类方法返回值类型应比父类方法返回值类型更小或者相等,子类方法声明抛出的异常应比父类方法声明抛出的异常更小或者相等,一大指的是子类方法的访问权限应该比父类方法的访问权限更大或者相等,需要指出的是覆盖方法和被覆盖方法只能是实例方法。
如果父类方法具有private权限,则该方法对其子类是隐藏的,因此无法重写该方法,如果子类定义了一个与父类private方法具有相同方法名、相同形参列表、相同返回值类型的方法,依旧不是重写,只是定义了一个新的方法。
构造器
可以调用在该类中被重载的构造器,形如this(name, age)
在继承中,子类构造器也可以调用父类构造器,形如super(name, age) 相同点是必须都出现在第一行。

多态
java引用变量有两个类型:一个是编译时类型,另一个是运行时类型。编译时类型由声明该变量时使用的类型决定,运行时类型由实际赋给该变量的对象决定。形如BaseClass b = new SubClass() 但这里要注意的是与方法不同,对象的实例变量不具有多态性。对象访问变量看声明,访问方法看实际对象类型(new出来的类型)
引用变量在编译阶段只能调用其编译时类型所具有的方法,但运行时则执行它运行时类型所具有的方法
一个典型的例子就是Queue q = new ArrayList<>();但是在编写代码时不可以直接写q.get(i)因为Queue类型的方法表中没有这个方法。
注意:static类方法的重写不具有多态性,注意这里的是重写不是抽象方法
当一个方法被调用时,JVM首先检查其是不是类方法。如果是,则直接从调用该方法引用变量所属类中找到该方法并执行,而不再确定它是否被重写(覆盖)。如果不是,才会去进行其它操作(例如动态方法查询)。
这种根据对象类型而对方法进行的选择,就是分派。根据分派发生的时期,可以将分派分为静态分派和动态分派两种。
静态分派发生在编译时期,分派根据静态类型信息发生。比较典型就是方法重载。
动态分派发生在运行时期,而上面提到的多态就是动态分派。
总结来说,Java只支持静态的多分派和动态的单分派。
编译时期确定方法有两点依据,1.调用方法的静态类型,2.方法的参数,所以说是静态多分派;
运行时期再确定方法只有一点依据,1.就是调用方法的实际类型,所以说是动态单分派;
Java如何实现双重分派:
http://www.cnblogs.com/youxin/archive/2013/05/25/3099016.html
第一个方法中两次分派的过程如下:
(1) 方法的接受者,也就是决定是Component的哪个具体子类接受
(2) 事件对象,通过类型判断对象instanceof进行第二次分派
第二个方法中的分派过程如下:
(1) 同上,决定Item中的哪个子类去接受complete方法
(2) 通过内部方法转发利用静态分派或者再利用一次动态分派实现调用哪个eval方法的问题
http://wiki.jikexueyuan.com/project/java-vm/polymorphism.html
强制类型转换


instanceof运算符前面的操作数的编译时类型要么与后面的类相同,要么与后面的类具有父子继承关系,否则会引起编译错误。
初始化块
初始化块会在构造函数之前被调用,只能用static修饰初始化块,静态初始化块只能初始化类的变量。
字符串的转换



单例类

不可变类

目前的不可变类有java提供的8个包装类以及java.lang.String类 Guava中提供的一些不可变的数据结构 还有Immutables库
抽象类

abstract和static并不是完全互斥的,虽然static和abstract不能同时修饰某个方法,但他们可以同时修饰内部类。而private与abstract方法不能同时修饰方法。
接口

接口中可以定义常量(int MAX_SIZE=100,会自动增加public static final修饰符)、抽象方法、内部类、内部接口、内部枚举、在Java8中允许定义默认方法以及类方法,默认都是public权限,因此定义时可以省略。和类继承相似,子接口扩展某个父接口,将会获得父接口里所定义的所有抽象方法、常量。
注意:
1. 接口里定义的内部类、内部接口、内部枚举默认都采用public static两个修饰符,不管定义时是否指定。
2. 接口不能用于创建实例,但接口可以用于声明引用变量
内部类
内部类可以定义为抽象类!
内部类和外部类的区别:


1. 非静态内部类的成员可以访问外部类的private成员,但反过来就不成立了。如果外部类需要访问非静态内部类的成员,则必须显式创建非静态内部类对象来调用访问其实例成员。不能这样操作的原因是当外部类需要这样访问时,内部类可能此时都没有产生。但非静态内部类的创建则必须通过外部类的实例对象才能够创建。
2. 同时根据静态成员不能访问非静态成员的规则,外部类的静态方法、静态代码块中不能访问非静态内部类。
3. Java不允许在非静态内部类中定义静态成员(包括方法、成员变量、初始化块)。
4. 静态内部类只能访问外部类的静态成员
5. 外部类的所有方法、所有初始代码块中可以使用静态内部类来定义变量、创建对象

此时这个外部子类也必须持有外部类的引用,构造器中必须传入外部类的对象才可以。
6. 局部内部类(方法内)
7. 匿名内部类
8. 在java8以前,java要求被匿名内部类访问的局部变量必须是final来修饰,但java8中变得更加智能了,会自动将被访问到的局部变量加上final修饰符。
Lambda表达式

Lambda表达式的目标类型就是函数式接口。
函数式接口:只含有一个抽象方法的接口,但可以包含多个默认方法、类方法,但只能声明一个抽象方法,同时用@FunctionalInterface注解来告知编译器执行严格的检查。
唯一的要求是Lambda表达式实现的匿名方法与目标类型(函数式接口)中唯一的抽象方法具有相同的形参列表。(但是可以有很多default的接口)
 按照某种逻辑算法(lambda表达式)提供一个数据。
按照某种逻辑算法(lambda表达式)提供一个数据。
如果lambda表达式的代码块只有一条代码,可以在代码块中使用方法引用和构造器引用。

与匿名内部类的区别以及联系:


还有一点区别就是匿名类的this指针指向本身,而lambda表达式的this指向其upper class。
闭包:
匿名类或者lambda都是一个闭包,在定义时会包裹周围的环境变量打包在一起,因此要求必须是final或者effectively final(只被更改过一次)。
http://www.cnblogs.com/figure9/archive/2014/10/24/4048421.html
lambda表达式是为了解决匿名内部类复杂的问题,而java的闭包在原有的实现上是通过匿名内部类实现的,因此lambda表达式也是解决了java的闭包问题。
枚举类
一个Java文件最多定义一个具有public权限的的枚举类,并且该Java源文件的文件名与枚举类相同,且第一行必须列出所有枚举实例使用逗号分隔,允许枚举类不使用public描述符,如下test.java所示:
enum app {
Male,Famel;
private int a;
}
public enum test {
QQ,WW;
private int b;
public void print() {
System.out.println(app.Male);
}
}
基本点:

可以switch(EnumClass)来进行判断。



如果想为所有的枚举值提供相同的方法则直接实现一个抽象方法即可。

四种引用

修饰符汇总

abstract与final永远不能同时使用;abstarct与static不能同时修饰方法,但可以同时修饰内部类;abstract与private不能同时修饰方法,但可以同时修饰内部类;private与final虽然可以同时修饰方法,但是起到的作用是相同的所以没什么意义。
RTTI
研究时对比C++ typeid and typeinfo
instanceof vs isInstance
https://stackoverflow.com/questions/8692214/when-to-use-class-isinstance-when-to-use-instanceof-operator
http://www.cnblogs.com/aoguren/p/4822380.html
isInstance 适用于可能在运行时才知道类型信息的时候
反射-> 注解发挥作用就是通过反射机制,在运行时获取类型信息
代理和动态代理
1. 还有一种静态植入代码的方式,在编译期发生作用,比如Aspectj
2. 无法通过自己类内部方法来进行调用,比如@Transactional注解,内部自己调用时是无法发生作用的(底层实现就是spring发现这个注解时注入的是一个proxy实例)
3. static方法也是无法起作用的,动态代理还是通过类的继承类似的方式实现
AOP的实现方式: jdk vs cglib
https://blog.csdn.net/qq_21033663/article/details/52295580
泛型总结
首先明白类型擦除的意义:http://blog.csdn.net/caihaijiang/article/details/6403349
然后弄明白泛型在定义类、接口、构造器、成员方法等使用,接着了解类型通配符的使用以及其上下限http://www.cnblogs.com/LinkinPark/p/5232982.html,有时候能用上限的地方一般也可以使用下限,取决于你想要保留子类还是父类的类型
接着弄懂泛型方法,并且掌握类型通配符和泛型方法的区别:
1. 泛型方法被用来表示方法中的多个参数之间的类型依赖关系,或者方法返回值与参数之间的类型依赖关系
2. 而类型通配符,最好用来支持灵活的子类化,并且其中的如集合并不能进行添加等操作(因为不知道是哪一个类型),最后看一下泛型数组的问题(http://blog.csdn.net/orzlzro/article/details/7017435),java的设计原则是,如果一段代码没有提出"unchecked未经转换的警告",则其运行也不会出现classCastException异常
掌握3种泛型的基本模式:
根据List与List的关系
1. 不变 两者任何关系都没有
2. 协变 List is a List C++的实现
3. 逆变 List is a List
JAVA中的泛型数组,是协变的,比如Base 2 dh = new Derivated2
但是dh[0] = new Derivated2();(error)
不变是一个看上去直观的做法,但是本质上与其类型系统有关。???
JAVA中的协变通过extends以及super实现。
泛型类型的继承规则
无论S与T有什么关系,Pair与Pair没有任何联系。
? extend 与? super使用区别:
list = list
1. 如果我们想要关注dog多一些,就可以使用list = list,这样的话,可以往里边加dog以及dog的子类,但是不能从中获取,因为不知道里边放的是动物还是动物的子类
2. 如果我们关注动物多一点,可以使用list< ? extends 动物> = list,这样的话,可以从其中获取动物,但是不能够添加
A -> B -> C的继承关系,
listsuperB可以指向listA和listB 而listextendsB可以指向listB和listC
Class类
Class类也是泛型的。例如String.class实际上是一个Class类的对象(唯一的对象。
妙用->进行类型匹配:
public static Pair makePair(Class c) throws InstaniationException {
return new Pair<>(c.newInstance(), c.newInstance());
}
调用时
makePair(Employee.class) 其中Employee.class与Class匹配
获取Class实例的三种方式:
(1)利用对象调用getClass()方法获取该对象的Class实例;
(2)使用Class类的静态方法forName(),用类的名字获取一个Class实例(staticClass forName(String className) Returns the Classobject associated with the class or interface with the given stringname. );
(3)运用.class的方式来获取Class实例,对于基本数据类型的封装类,还可以采用.TYPE来获取相对应的基本数据类型的Class实例
在newInstance()调用类中缺省的构造方法
异常体系

其中RuntimeException类及其子类的实例被称为Runtime异常,也就是所谓的unchecked异常。其他的为checked异常,如果不解决checked异常,则无法通过编译。
java7中提供了catch(exception1 | exception2)的语句以及自动关闭资源的try语句
 以前的话不会进行细致的检查,必须throws Exception
以前的话不会进行细致的检查,必须throws Exception
保持异常链:
在catch语句中throw新的异常时要以旧的异常实例为构造参数,如throw new SalException(ex);
注解机制

另外关于依赖注入,javax.inject下也提供了许多声明可被用作注入的注解:http://blog.csdn.net/dl88250/article/details/4838803
SuppressWarnings注解的常见参数值的简单说明:
1.deprecation:使用了不赞成使用的类或方法时的警告;
2.unchecked:执行了未检查的转换时的警告,例如当使用集合时没有用泛型 (Generics) 来指定集合保存的类型;
3.fallthrough:当 Switch 程序块直接通往下一种情况而没有 Break 时的警告;
4.path:在类路径、源文件路径等中有不存在的路径时的警告;
5.serial:当在可序列化的类上缺少 serialVersionUID 定义时的警告;
6.finally:任何 finally 子句不能正常完成时的警告;
7.all:关于以上所有情况的警告。
@SafeVarargs用于抑制堆污染警告的发生。https://stackoverflow.com/questions/12462079/potential-heap-pollution-via-varargs-parameter
元注解的作用就是负责注解其他注解。Java5.0定义了4个标准的meta-annotation类型,它们被用来提供对其它 annotation类型作说明。Java5.0定义的元注解:
1.@Target,
2.@Retention,注解的声明周期
3.@Documented,
4.@Inherited
详细使用:http://www.cnblogs.com/peida/archive/2013/04/24/3036689.html
java8还新增了@Repeatable元注解用于解决重复注解的问题。
java8新增的重复注解在定义时需要为允许重复注解的注解提供一个容器注解,并且要保证容器注解的存活周期大于允许重复注解的注解。

 但是java8并没有为类型注解提供处理的框架
但是java8并没有为类型注解提供处理的框架
自定义注解:
@Retention(RetentionPolicy.CLASS)
@Target(ElementType.FIELD)
public @interface Meta {
int repeat() default 0;
String id() default "";
}
1. @interface声明这是一个自定义的注解,所有的注解类都隐式继承于 java.lang.annotation.Annotation,注解不允许显式继承于其他的接口。
2. 注解内部通过方法声明成员变量
3. 成员类型是受限的,合法的类型包括原始类型及其封装类、String、Class、enums、注解类型,以及上述类型的数组类型。如ForumService value()、List foo()是非法的。
4. 成员变量允许有默认值,没有默认值的变量必须在使用时手动通过name=value的形式指定,当变量名为value时可直接指定,省略=
定义的注解,本来是没有任何效果的,要实现某种特定作用必须要结合注解处理器
实现我们自己的注解处理器:
1. 运行时通过反射来处理 http://www.cnblogs.com/peida/archive/2013/04/26/3038503.html
2. 编译期处理
(1) apt工具实现编译时处理注解:http://docs.oracle.com/javase/1.5.0/docs/guide/apt/GettingStarted.html
(2) JDK 5中的apt工具的不足之处在于它是Oracle提供的私有实现。在JDK6中,通过JSR 269把自定义注解处理器这一功能进行了规范化,有了新的javax.annotation.processing这个新的API。对Mirror API也进行了更新,形成了新的javax.lang.model包。注解处理器的使用也进行了简化,不需要再单独运行apt这样的命令行工具,Java编译器本身就可以完成对注解的处理。对于同样的功能,如果用JSR 269的做法,只需要一个类就可以了。
@SupportedSourceVersion(SourceVersion.RELEASE_6)
@SupportedAnnotationTypes("annotation.Assignment")
public class AssignmentProcess extends AbstractProcessor {
private TypeElement assignmentElement;
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
Elements elementUtils = processingEnv.getElementUtils();
assignmentElement = elementUtils.getTypeElement("annotation.Assignment");
}
public boolean process(Set annotations, RoundEnvironment roundEnv) {
Set elements = roundEnv.getElementsAnnotatedWith(assignmentElement);
for (Element element : elements) {
processAssignment(element);
}
}
private void processAssignment(Element element) {
List annotations = element.getAnnotationMirrors();
for (AnnotationMirror mirror : annotations) {
if (mirror.getAnnotationType().asElement().equals(assignmentElement)) {
Map values = mirror.getElementValues();
String assignee = (String) getAnnotationValue(values, "assignee"); //获取注解的值
}
}
}
}
使用的时候也更加简单,只需要通过javac -processor annotation.pap.AssignmentProcess Demo1.java这样的方式即可。
3. Aspects所实现的aop模型中也提供了对特定的注解的切面处理,也算是一种注解处理器
思考:spring的注解处理是运行时,有机会去研究一下源码,编译时的注解处理通常被用做生成额外的xml、class文件等作用
依赖注入是如何结合反射机制实现的?
4. lombok实现的注解也是SOURCE级别的,实现原理和2介绍的基本类似https://blog.csdn.net/dslztx/article/details/46715803
java I/O体系
首先从大类来说分为随机读写类RandomAccessFile,第二类是输出/输出流。输入输出流又分为单次读写1个字节的字节流以及单次读写2个字节的字符流(char)。


基类
InputStream与OutputStream是所有字节型输入输出流的基抽象类,同时也是适配器(原始流处理器)需要适配的对象,也是装饰器(链接流处理器)装饰对象的基类.原始流处理器
原始流处理器接收Byte数组对象,String对象,FileDescriptor对象将其适配成InputStream,以供其他装饰器使用,他们都继承自InputStream 包括如下几个:
ByteArrayInputStream: 接收Byte数组为流源,为多线程通信提供缓冲区操作功能
FileInputStream: 接收一个File作为流源,用于文件的读取
PipedInputStream: 接收一个PipedOutputStream,与PipedOutputStream配合作为管道使用
StringBufferInputStream: 接收一个String作为流的源(已弃用)链接流处理器
链接流处理器可以接收另一个流处理器(InputStream,包括链接流处理器和原始流处理器)作为源,并对其功能进行扩展,所以说他们是装饰器.
1) FilterInputStream继承自InputStream,是所有装饰器的父类,FilterInputStream内部也包含一个InputStream,这个InputStream就是被装饰类--一个原始流处理器,它包括如下几个子类:
BufferedInputStream: 用来将数据读入内存缓冲区,并从此缓冲区提供数据
DataInputStream: 提供基于多字节的读取方法,可以读取原始数据类型(Byte, Int, Long, Double等等)
LineNumberInputStream: 提供具有行计数功能的流处理器
PushbackInputStream: 提供已读取字节"推回"输入流的功能
2) ObjectInputStream: 可以将使用ObjectOutputStream写入的基本数据和对象进行反串行化
3) SequenceInputStream: 可以合并多个InputStream原始流,依次读取这些合并的原始流
- 与输出/输出流不同的是。RandomAcessFile支持随机访问的形式,程序可以直接跳转到文件的任意地方来读写数据,同时允许自由定位文件记录指针,可以向已存在的文件后追加内容,同时在打开文件需要制定mode模式
- InputStreamReader与OutputStreamReader提供了字节流转换成字符流的转换
- 标准输入输出的重定向,System提供了setErr/setIn/setOut方法
- Process类提供了获取子进程输入输出的方式,getErrorStream/getInputStream/getOutputStream
jdk4 NIO
核心对象是Channel以及Buffer,Channel是对传统输入/输出系统的模拟(相对于输入输出流是Channel一个双通道),在新的IO系统所有的数据都需要通过通道运输:与传统的输入/输出系统的区别,其提供了map的方法,可以直接将一块数据映射到内存中。新IO是面向块的处理。
Buffer本质是一个数组,发送到Channel的所有对象都必须首先放到Buffer中,而从Channel中读取的数据也必须先放到Buffer中去。
除了Buffer和Channel外,新IO还提供了用于将Unicode字符串映射成字节序列以及逆映射操作的Charest类,也提供了用于支持非堵塞式输入输出的Selector类。
所有的Channel都不应该直接通过构造器来创建,而是通过传统的节点InputStream的getChannel方法来创建

在NIO中,java提供了FileLock来支持文件锁定功能,在FileChannel中提供的lock堵塞式/trylock非堵塞方法都可以获得文件锁FileLock对象,同时支持锁定文件的部分内容,而不是全部;允许用户选择这是一个共享锁还是排他锁,默认是排他锁,锁住读写。
jdk7 NIO2

早期Java只提供了File类来访问文件系统,但由于其功能有限,不能利用特定文件系统的特性,并且其提供的性能也不高。NIO2为了弥补这种不足,引入了Path接口,用其来代表一个平台无关的文件路径。并且提供了Paths以及Files类,其中Files包含了大量静态的工具方法来操作文件,包含遍历文件、监控文件变化等新功能,更便捷的获得文件属性;Paths则包含了两个返回Path的静态工厂方法。
https://www.ibm.com/developerworks/cn/java/j-nio2-2/index.html
https://www.ibm.com/developerworks/cn/java/j-nio2-1/index.html
Java在NIO2中正式提供了异步文件I/O操作,同时提供了与UNIX网络编程驱动I/O对应的AIO,是真正的非堵塞I/O,它不需要多路复用器对注册的通道进行轮询操作即可实现异步读写。
通过下列两种方式获取操作结果:
1. 通过java.util.concurrent.Future类来表示异步操作的结果
2. 在执行异步操作的时候传入一个CompletionHandler接口的实现类作为操作完成的回调
使用AIO编程的例子见netty权威指南
netty vs 原生jdk nio
https://www.520mwx.com/view/20451
多线程
可以通过以下几种方式创建线程:
1. 继承Thread类创建线程类
2. 实现Runnable接口创建线程类
3. 使用Callable和Future创建线程,而Callable是函数式接口,因此可直接使用Lambda表达式创建Callable对象

FutureTask同时实现了future和Callable接口,同时可以作为Thread的target
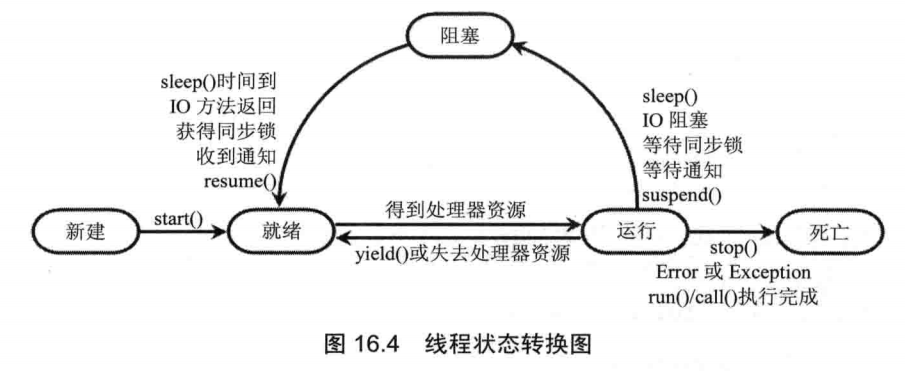
yield()只是让当前执行的线程暂停,同时让系统的线程调度器再重新调度一次,但很有可能调度执行的线程还是它自己,除非有人优先级比它高(setPriority设置)。
join()方法提供了让一个线程等待另外一个线程执行结束的方式。
锁对象
Lock提供了比synchronized方法和synchronized代码块更广泛的锁定操作。jdk5提供
Synchronized优化(轻量级锁、偏向锁):https://yq.aliyun.com/articles/143211?spm=5176.8246799.0.0.nGKq1a
几种细粒度锁的实现方式:https://yq.aliyun.com/ziliao/150184?spm=5176.8246799.0.0.nGKq1a
锁的可重入性
Java中的synchronized同步块以及ReentrantLock、ReenTrantReadWriteLock是可重入的。共享锁如Semaphore等应该都是可以重入的吧?至少Semaphore是可重入的。
//可重入锁的实现
public class Lock{
boolean isLocked = false;
Thread lockedBy = null;
int lockedCount = 0;
public synchronized void lock()
throws InterruptedException{
Thread callingThread =
Thread.currentThread();
while(isLocked && lockedBy != callingThread){
wait();
}
isLocked = true;
lockedCount++;
lockedBy = callingThread;
}
public synchronized void unlock(){
if(Thread.curentThread() ==
this.lockedBy){
lockedCount--;
if(lockedCount == 0){
isLocked = false;
notify();
}
}
}
...
}
使用可重入锁能有效的避免死锁现象的发生。
锁的公平性
synchronized同步块不保证公平性
Semaphore和ReentrantLock都是有公平模式和非公平模式可以进行选择
其中Lock接口共有两个实现类分别是ReentrantLock以及ReentrantReadWriteLock,后者还另外实现了ReadWriteLock接口,这这个类实现都依托于 的内部类
的内部类
底层实现分析:http://www.cnblogs.com/leesf456/p/5383609.html
还有CyclicBarrier以及CountDownLatch等并发工具类其底层实现也依赖于上图的AQS数据结构。
AQS论文:The java.util.concurrent Synchronizer Framework
线程通信
- 传统的线程通信
 wait操作会释放同步锁
wait操作会释放同步锁
(1) 丢失的信号(Missed Signals)
如果一个线程先于被通知线程调用wait()前调用了notify(),等待的线程将错过这个信号。
public class MyWaitNotify2{
MonitorObject myMonitorObject = new MonitorObject();
boolean wasSignalled = false;
public void doWait(){
synchronized(myMonitorObject){
if(!wasSignalled){
try{
myMonitorObject.wait();
} catch(InterruptedException e){...}
}
//clear signal and continue running.
wasSignalled = false;
}
}
public void doNotify(){
synchronized(myMonitorObject){
wasSignalled = true;
myMonitorObject.notify();
}
}
}
(2) 虚假唤醒
为了防止假唤醒,保存信号的成员变量将在一个while循环里接受检查,而不是在if表达式里。这样的一个while循环叫做自旋锁(校注:这种做法要慎重,目前的JVM实现自旋会消耗CPU,如果长时间不调用doNotify方法,doWait方法会一直自旋,CPU会消耗太大)。
public class MyWaitNotify3{
MonitorObject myMonitorObject = new MonitorObject();
boolean wasSignalled = false;
public void doWait(){
synchronized(myMonitorObject){
while(!wasSignalled){
try{
myMonitorObject.wait();
} catch(InterruptedException e){...}
}
//clear signal and continue running.
wasSignalled = false;
}
}
public void doNotify(){
synchronized(myMonitorObject){
wasSignalled = true;
myMonitorObject.notify();
}
}
}
(3) notify/notyfyAll区别
先说两个概念:锁池和等待池锁池:假设线程A已经拥有了某个对象(注意:不是类)的锁,而其它的线程想要调用这个对象的某个synchronized方法(或者synchronized块),由于这些线程在进入对象的synchronized方法之前必须先获得该对象的锁的拥有权,但是该对象的锁目前正被线程A拥有,所以这些线程就进入了该对象的锁池中。等待池:假设一个线程A调用了某个对象的wait()方法,线程A就会释放该对象的锁后,进入到了该对象的等待池中
然后再来说notify和notifyAll的区别 如果线程调用了对象的 wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。当有线程调用了对象的 notifyAll()方法(唤醒所有 wait 线程)或 notify()方法(只随机唤醒一个 wait 线程),被唤醒的的线程便会进入该对象的锁池中,锁池中的线程会去竞争该对象锁。也就是说,调用了notify后只要一个线程会由等待池进入锁池,而notifyAll会将该对象等待池内的所有线程移动到锁池中,等待锁竞争优先级高的线程竞争到对象锁的概率大,假若某线程没有竞争到该对象锁,它还会留在锁池中,唯有线程再次调用 wait()方法,它才会重新回到等待池中。而竞争到对象锁的线程则继续往下执行,直到执行完了 synchronized 代码块,它会释放掉该对象锁,这时锁池中的线程会继续竞争该对象锁。
notify会导致活跃度过低,notifyall会带来惊群问题。
(4) 不要在字符串常量或全局对象中调用wait()
在空字符串作为锁的同步块(或者其他常量字符串)里调用wait()和notify()产生的问题是,JVM/编译器内部会把常量字符串转换成同一个对象。这意味着,即使你有2个不同的MyWaitNotify实例,它们都引用了相同的空字符串实例。同时也意味着存在这样的风险:在第一个MyWaitNotify实例上调用doWait()的线程会被在第二个MyWaitNotify实例上调用doNotify()的线程唤醒。
2. 使用condition控制线程通信
在这种情况下,实际上就是Lock对象替代了同步方法或者同步代码块,Condition替代了同步监视器的作用。
Condition对象通过lock.newCondition()方法产生

3. 使用BlockingQueue控制线程通信

线程组合未处理的异常
如果创建时没有指定线程组,则属于默认线程组,

这里要注意的一点是异常处理器对异常处理之后,异常依然会传播给上层调用者。
线程池
java的线程池实现是Executor实现,将任务的发布和执行进行了隔离。将运行的任务抽象为一个Executor并提供对生命周期的支持以及统计信息收集、应用程序管理机制和性能监控等机制。
基于生产者-消费者模式,提交任务-生产者,执行任务的线程则相当于消费者。
多种Executor,包括固定大小的线程池,无边界的线程池,单线程的线程池、执行延迟任务的线程池等,允许用户通过ThreadPoolExector来自定义,包括队列满时的策略等。
而线程的产生则可以通过定义化ThreadFactory来实现,默认是直接new一个。
通过ExecutorService来管理executor的生命周期。shutdown和shutdownNoe两种方式关闭线程池。
Runnable不能返回一个值或者抛出一个受检查的异常。而callable可以~
Future表示一个任务的生命周期,并提供了相应的方法判断是否完成,以及获取任务的结果和获取任务等。但是get()会堵塞。
可以通过newTaskfor方法创建一个FutureTask来封装任务。
ExectorService将exector和BlockingQueue结合在一起,exector将callable的结果封装成future扔到队列中去。
线程池源码探索:http://www.tuicool.com/articles/EvUjQnz
Java8增强的ForkJoinPool
ForkJoinPool是ExecutorService的实现类,因此是一种特殊的线程池,ForkJoinPool 最适合的是计算密集型的任务,如果存在I/O,线程间同步,sleep()等会造成线程长时间阻塞的情况时,最好配合使用ManagedBlocker。提供了如下两个如下常用的构造器:
* ForkJoinPool(int paralleism):创建一个包含parallelism个并行线程的ForkJoinPool
* FokrJoinPool():以Runtime.availableProcessors()返回值作为参数进行创建线程池
java8进一步增强扩展了其功能,为其增加了通用池的功能,通过以下两个静态方法为其提供静态池功能:
* ForkJoinPool commonPool() 该方法返回一个通用池,通用池的状态不会受到shutdown()或shutdownNow方法的影响
* getCommonPoolParallelism():该方法返回通用池的并行级别
To support parallelism for collections using parallel streams, a common ForkJoinPool is used internally.
为什么是个通用池:https://stackoverflow.com/questions/33694908/is-forkjoinpool-commonpool-equivalent-to-no-pool
能为并行流处理指定线程池么?https://stackoverflow.com/questions/21163108/custom-thread-pool-in-java-8-parallel-stream
java8的CompletableFuture内部执行的线程池也是依赖commonpool实现的,从而提供了众多异步回调的转换和结合操作的新功能http://www.importnew.com/10815.html
有两种类型的ForkJoinTask的定义:
RecursiveAction的实例代表执行没有返回结果。
相反,RecursiveTask会有返回值。

 通过Future future = pool.submit()来接受返回值
通过Future future = pool.submit()来接受返回值
ManagedBlocker的使用:http://www.concretepage.com/java/jdk7/example-of-managedblocker-in-java
网络编程
使用InetAddress封装IP地址,使用URL封装http地址,URLConnection封装与http连接
http编程
原生的java以及apache-httpclient支持:http://www.mkyong.com/java/how-to-send-http-request-getpost-in-java/
异步http:
1. play wsclient
使用方式:JsonNode resp = wsClient.url(api).get().toCompletableFuture().get(TIMEOUT, SECONDS).asJson()
response还可以获得以下的形式:getBody(),asXml()等
public interface WSResponse {
Map> getAllHeaders();
String getHeader(String var1);
Object getUnderlying();
int getStatus();
String getStatusText();
List getCookies();
WSCookie getCookie(String var1);
String getBody();
Document asXml();
JsonNode asJson();
InputStream getBodyAsStream();
byte[] asByteArray();
URI getUri();
}
2. 2同步httpclient包装在CompletableFuture.supplyAsync(()->{})中
Webservice
Webservice有很多种不同的方式根据wsdl生成对应的数据结构
1. jdk中内置的webservice工具 wsimport -keep -s main/java "http://113.108.143.172/etcwip/services/CWIPService/wsdl/CWIPService.wsdl" 生成命令
2. 从idea中生成的webservice http://www.biliyu.com/article/986.html
3. 另外一种生成webservice的方式:
public class ScootGenerator {
public static void main(String[] args) {
// org.apache.axis.wsdl.WSDL2Java生成服务端调用方法:
// java org.apache.axis.wsdl.WSDL2Java -o代码输出路径 -p生成代码的包结构 --server-side wsdl文件的路径
WSDL2Java.main(new String[]{"-oC:\Users\Administrator\Desktop\bookingManager", "-pbooking", "--server-side", "https://tztestr3xapi.navitaire.com/BookingManager.svc?wsdl"});
WSDL2Java.main(new String[]{"-oC:\Users\Administrator\Desktop\sessionManager", "-psession", "--server-side", "https://tztestr3xapi.navitaire.com/BookingManager.svc?wsdl"});
}
}
Axis、axis2、Xfire、jax-ws(原生)以及cx是不同的webservice框架,不同的框架生成的wsdl文件不同,wsdl文件中携带使用哪个框架的标识
TCP/UDP编程
使用ServerSocket创建TCP服务端 使用Socket进行通信(同步)
使用NIO中的Selector实现非堵塞Socket通信(同步)
使用Java7的AIO的AsychronousServerSocketChannel实现非堵塞通信(异步)
使用DatagramSocket进行upp编程
使用MulticastSocket实现多点广播
使用代理
从Java5开始,Java在java.net包下提供了Proxy和ProxySelector两个类,其中Proxy代表一个代理服务器,可以再打开URLConnection连接时指定Proxy,创建Socket连接时也可以指定Proxy;而ProxySelector代表一个代理选择器,它提供对代理服务器更加灵活的控制,它可以对HTTP、HTTPS、FTP等进行分别设置,而且还可以设置不需要通过代理服务器的主机和地址。
见实习-全局代理设置,在igola实习时候需要为某个webservice设置代理服务器
