@Duanxx
2016-10-25T02:46:21.000000Z
字数 6150
阅读 5785
LR回归(Logistic Regression)
监督学习
@ author : duanxxnj@163.com
@ time : 2016-07-03
LR回归,虽然这个算法从名字上来看,是回归算法,但其实际上是一个分类算法,学术界也叫它logit regression, maximum-entropy classification (MaxEnt)或者是the log-linear classifier。在机器学习算法中,有几十种分类器,LR回归是其中最常用的一个。
LR回归是在线性回归模型的基础上,使用函数,将线性模型 的结果压缩到 之间,使其拥有概率意义。 其本质仍然是一个线性模型,实现相对简单。在广告计算和推荐系统中使用频率极高,是CTR预估模型的基本算法。同时,LR模型也是深度学习的基本组成单元。
LR回归属于概率性判别式模型,之所谓是概率性模型,是因为LR模型是有概率意义的;之所以是判别式模型,是因为LR回归并没有对数据的分布进行建模,也就是说,LR模型并不知道数据的具体分布,而是直接将判别函数,或者说是分类超平面求解了出来。
一般来说,分类算法都是求解 ,即对于一个新的样本,计算其条件概率 。这个可以看做是一个后验概率,其计算可以基于贝叶斯公式得到: ,其中是类条件概率密度,是类的概率先验。使用这种方法的模型,称为是生成模型,即:是由 和 生成的。分类算法所得到的 可以将输入空间划分成许多不相交的区域,这些区域之间的分隔面被称为判别函数(也称为分类面),有了判别函数,就可以进行分类了,上面生成模型,最终也是为了得到判别函数。如果直接对判别函数进行求解,得到判别面,这种方法,就称为判别式法。LR就属于这种方法。
logistic distribution (逻辑斯蒂分布)
之前说过,LR回归是在线性回归模型的基础上,使用函数得到的。关于线性模型,在前面的文章《线性回归》中已经说了很多了。这里就先介绍一下,函数。
首先,需要对 logistic distribution (逻辑斯蒂分布)进行说明,这个分布的密度函数和分布函数如下:
这里是位置参数,而 是形状参数。
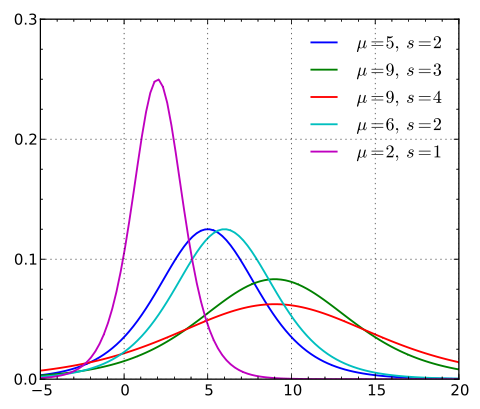
逻辑斯蒂分布在不同的 和 的情况下,其概率密度函数的图形:
逻辑斯蒂分布在不同的 和 的情况下,其概率分布函数的图形:
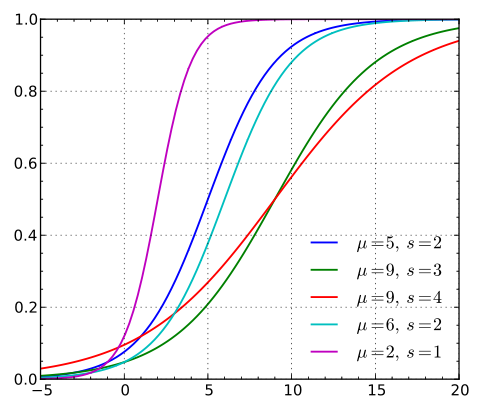
由图可以看出,逻辑斯蒂分布和高斯分布的密度函数长得差不多。特别注意逻辑斯蒂分布的概率分布函数自中心附近增长速度较快,而在两端的增长速度相对较慢。形状参数的数值越小,则概率分布函数在中心附近增长越快。
当 时,逻辑斯蒂分布的概率分布函数就是我们常说的函数:
且其导数为:
这是一个非常好的特性,并且这个特性在后面的推导中将会被用到。
从逻辑斯蒂分布 到 逻辑斯蒂回归模型
前面说过,分类算法都是求解,而逻辑斯蒂回归模型,就是用当 时的逻辑斯蒂分布的概率分布函数:函数,对进行建模,所得到的模型,对于二分类的逻辑斯蒂回归模型有:
很容易求得,这里:
就是我们在分类算法中的决策面,由于LR回归是一个线性分类算法,所以,此处采用线性模型:这里参数向量为,是线性模型的基函数,基函数的数目为个,如果定义的话(详细说明可以参阅《线性回归》):
那么, 逻辑斯蒂回归模型 就可以重写为下面这个形式:
对于一个二分类的数据集,这里,其极大似然估计为:
对数似然估计为:
关于的梯度为:
得到梯度之后,那么就可以和线性回归模型一样,使用梯度下降法求解参数。
梯度下降法实现相对简单,但是其收敛速度往往不尽人意,可以考虑使用随机梯度下降法来解决收敛速度的问题。但上面两种在最小值附近,都存在以一种曲折的慢速逼近方式来逼近最小点的问题。所以在LR回归的实际算法中,用到的是牛顿法,拟牛顿法(DFP、BFGS、L-BFGS)。
由于求解最优解的问题,其实是一个凸优化的问题,这些数值优化方法的区别仅仅在于选择什么方向走向最优解,而这个方向通常是优化函数在当前点的一阶导数(梯度)或者二阶导数(海森矩阵)决定的。比如梯度下降法用的就是一阶导数,而牛顿法和拟牛顿法用的就是二阶导数。
带惩罚项的LR回归
在之前的文章《Lasso Regression》、《脊回归》中,就L1正则化和L2正则化作了详细的说明,其主要是用来避免模型的参数过大,而导致的模型过拟合的问题。其实现方法就是在前面的对数似然函数后面再加上一个惩罚项。
L2惩罚的LR回归:
L1惩罚的LR回归:
上式中,是用于调节目标函数和惩罚项之间关系的,越小,惩罚力度越大,所得到的的最优解越趋近于0,或者说参数向量越稀疏;越大,惩罚力度越小,越能体现模型本身的特征。
#!/usr/bin/python# -*- coding: utf-8 -*-"""author : duanxxnj@163.comtime : 2016-07-03-18-04基于L1惩罚和L2惩罚的LR回归模型C是用于调节目标函数和惩罚项之间关系的C越小,惩罚力度越大,所得到的w的最优解越趋近于0,或者说参数向量越稀疏C越大,惩罚力度越小,越能体现模型本身的特征。本例子是利用逻辑回归做数字分类每个样本都是一个8x8的图片,将这些样本分为两类:0-4为一类,5-9为一类"""print(__doc__)import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LogisticRegressionfrom sklearn import datasetsfrom sklearn.preprocessing import StandardScaler# 读取图片数据# 这个数据集中有共有10种数字图片,数字分别是0-9# 每种类别的数字大概有180张图片,总共的图片数目为1797张# 每幅图片的尺寸为8x8,即64个像素点# 像素的变化范围是0-16## 也就是说,每个样本点有64个特征# 即本例中LR模型的特征维度为64digits = datasets.load_digits()# 将前12张数字图片显示出来plt.figure(1)for i in range(12):imageplot = plt.subplot(3, 4, i+1)plt.imshow(digits.images[i], interpolation='nearest',cmap='binary', vmax=16, vmin=0)imageplot.set_title("digit %d" % i)# 读取数据X和目标y,并将数据X归一化# 归一化的结果是均值为0,方差为1,也就是常用的z变换## 对于机器学习中的很多方法,比如SVM,L1、L2正则化的线性模型等等# 对于数据,都有一个基本假设,就是数据每个特征都是以0为中心# 并且所有特征的数据变化都在同一个数量级# 如果有一个特征的方差特别大,那么这个特征就有可能对机器学习的模型起决定性的作用# 为了防止上面的现象,所以这里将数据做了归一化,或者叫做正则化X, y = digits.data, digits.targetX = StandardScaler().fit_transform(X)# 将数据集分成两类 0-4之间为一类,5-9之间为另一类y = (y > 4).astype(np.int)plt.figure(2)for i, C in enumerate((100, 1, 0.01)):# 根据不同的C得到不同的LR模型clf_l1_LR = LogisticRegression(C=C, penalty='l1', tol=0.01)clf_l2_LR = LogisticRegression(C=C, penalty='l2', tol=0.01)clf_l1_LR.fit(X, y)clf_l2_LR.fit(X, y)# LR模型的参数向量coef_l1_LR = clf_l1_LR.coef_.ravel()coef_l2_LR = clf_l2_LR.coef_.ravel()# 计算L1和L2惩罚下,模型参数w的稀疏性sparsity_l1_LR = np.mean(coef_l1_LR == 0) * 100sparsity_l2_LR = np.mean(coef_l2_LR == 0) * 100print("C=%.2f" % C)print("L1惩罚项得到的参数的稀疏性: %.2f%%" % sparsity_l1_LR)print("L1惩罚项的模型性能: %.4f" % clf_l1_LR.score(X, y))print("L2惩罚项得到的参数的稀疏性: %.2f%%" % sparsity_l2_LR)print("L2惩罚项的模型性能: %.4f" % clf_l2_LR.score(X, y))l1_plot = plt.subplot(3, 2, 2 * i + 1)l2_plot = plt.subplot(3, 2, 2 * (i + 1))if i == 0:l1_plot.set_title("L1 penalty")l2_plot.set_title("L2 penalty")print coef_l1_LRl1_plot.imshow(np.abs(coef_l1_LR.reshape(8, 8)), interpolation='nearest',cmap='binary', vmax=1, vmin=0)l2_plot.imshow(np.abs(coef_l2_LR.reshape(8, 8)), interpolation='nearest',cmap='binary', vmax=1, vmin=0)plt.text(-8, 3, "C = %.2f" % C)l1_plot.set_xticks(())l1_plot.set_yticks(())l2_plot.set_xticks(())l2_plot.set_yticks(())plt.show()

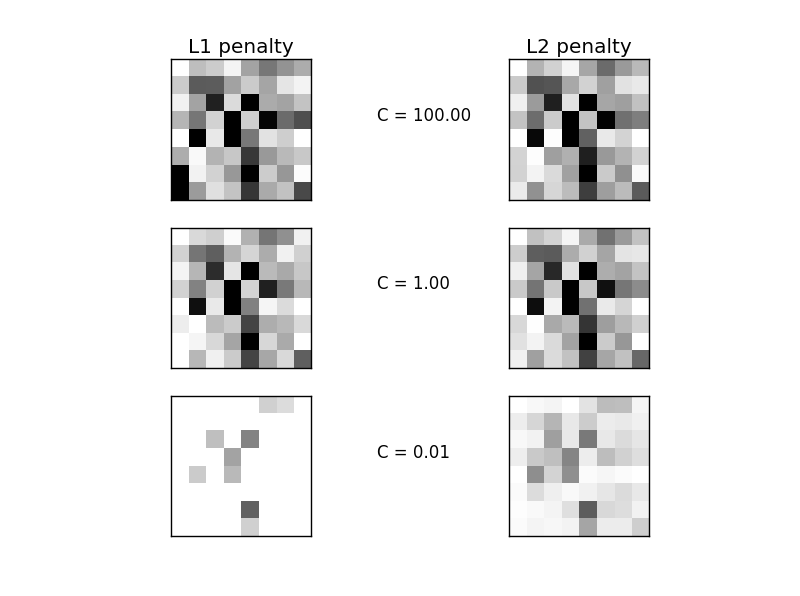
程序运行结果:
C=100.00L1惩罚项得到的参数的稀疏性: 4.69%L1惩罚项的模型性能: 0.9098L2惩罚项得到的参数的稀疏性: 4.69%L2惩罚项的模型性能: 0.9098C=1.00L1惩罚项得到的参数的稀疏性: 9.38%L1惩罚项的模型性能: 0.9098L2惩罚项得到的参数的稀疏性: 4.69%L2惩罚项的模型性能: 0.9093C=0.01L1惩罚项得到的参数的稀疏性: 85.94%L1惩罚项的模型性能: 0.8614L2惩罚项得到的参数的稀疏性: 4.69%L2惩罚项的模型性能: 0.8915
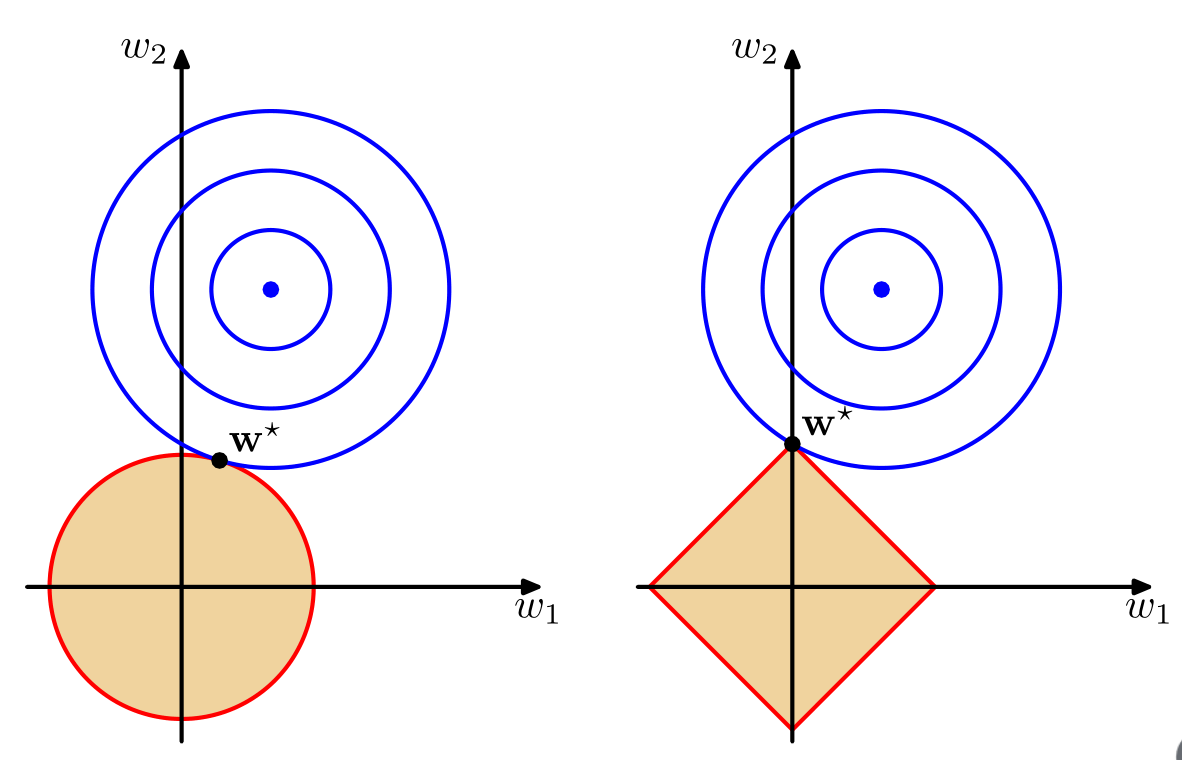
由上面的运行结果可以看出,随着C的不断减小,L1惩罚项带来的参数的稀疏性越来越大,而L2惩罚项的参数的稀疏性并没有特别大的改变。所以,在之前的Lasso Regression中也提到过,可以使用L1正则化来进行特征选择。关于L1和L2正则化带来的结果上的稀疏性的区别,在RPML中是这么解释的:下面左边是L2正则化,右边是L1正则化,可以看出由于L1正则化的最小点或者说是最优解,一般会直接走到坐标轴上,这样其他坐标轴的数值就直接为0了,而那些为0 的坐标轴对应的就是不重要的特征,比如下图右边图中的;右图中 的就是重要的特征。而L2正则化由于其解的约束空间是一个圆形,所以最优解很难落到坐标轴上,所以其并不用于做特征选择。