@windmelon
2019-05-22T12:13:25.000000Z
字数 4726
阅读 5543
C++实现简单的词法分析器
编译原理
简介
词法分析是编译器工作的第一步。词法分析负责将用户的代码从左至右依次读入,将用户的代码转换为token。
词法分析器可以分为两个步骤来实现,首先过滤掉源程序中的换行符、制表符和注释(空格在这里需要保留,因为删除空格会导致无法识别int i和inti的现象),然后逐字符读入源程序,对程序进行分解,分解成五类,分别是标识符、保留字、常数、运算符、界符。
实现步骤
种别码定义
种别码是用来表示扫描到的字符所属类型的索引,根据扫描函数返回的种别码,可以直接判断该字符是标识符、保留字、常数、运算符或者界符。
0 -> '\0' #种别码0代表读到文件末尾,结束标识
1~32 -> 保留字
33~68 -> 运算符界符
99 -> 常量
100 -> 标识符
定义保留字表和运算符界符
//保留字表static char reserveWord[32][20] = {"auto", "break", "case", "char", "const", "continue","default", "do", "double", "else", "enum", "extern","float", "for", "goto", "if", "int", "long","register", "return", "short", "signed", "sizeof", "static","struct", "switch", "typedef", "union", "unsigned", "void","volatile", "while"};//界符运算符static char operatorOrDelimiter[36][10] = {"+","-","*","/","<","<=",">",">=","=","==","!=",";","(",")","^",",","\"","\'","#","&","&&","|","||","%","~","<<",">>","[","]","{","}","\\",".","\?",":","!"};static char IDentifierTbl[1000][50] = {""};//标识符表
这一步是根据所针对的程序类型,指定保留字和运算符界符,然后定义一个标识符表,用来保存程序中自定义的变量名
定义判断字符类型的函数
bool isDigit(char ch)//判断是否为数字{if(ch>= '0' && ch <= '9')return true;return false;}bool isLetter(char ch)//判断是否为字母或下划线{if((ch>= 'a' && ch<='z') || ( ch <= 'Z' && ch >= 'A')|| ch == '_')return true;return false;}int isReserve(char *s)//判断是否为保留字{for(int i=0;i<32;++i){if(strcmp(reserveWord[i],s) == 0)return i+1;//返回种别码}return -1;}
isDigit()和isLetter()两个函数是在逐字符扫描时用来判断字符类型的函数,而isReserve()是在扫描出一个完整单词后用来判断该单词是否为保留字的,判断是否为界符或者运算符的在后面实现
定义过滤无用字符的函数
void filter(char *s,int len)//源程序预处理,过滤注释和换行回车制表符{char tmp[10000];int p = 0;for(int i=0;i<len;++i){if(s[i] == '/' && s[i+1] == '/')//单行注释{while(s[i]!='\n') ++i;//扫描到换行符为止}if(s[i] == '/' && s[i+1] == '*')//多行注释{i+=2;while(s[i] != '*' && s[i+1] != '/'){if(s[i] == '\0'){cout<<"annotation error!"<<endl;exit(0);}i++;}i+=2;}if(s[i] != '\n' && s[i] != '\t' && s[i] != '\v' && s[i] != '\r'){tmp[p] = s[i];++p;}}tmp[p] = '\0';strcpy(s,tmp);}
该函数将对源程序进行过滤,删除注释,换行符,制表符和回车符
定义对程序进行扫描的函数
void scanner(int &syn,char * project,char * token,int &p)//扫描源程序,syn是种别码,token是当前扫描的单词,p为扫描位置索引{int count = 0;char ch;ch = project[p];while(ch == ' ')//去掉空格{++p;ch = project[p];}for(int i=0;i<20;i++)//清空token{token[i] = '\0';}if(isLetter(project[p])){//以字母开头token[count++] = project[p++];while(isLetter(project[p])||isDigit(project[p]))//后面是字母或数字{token[count++] = project[p++];}token[count] = '\0';syn = isReserve(token);//查表找到种别码if(syn == -1){//若不是保留字则是标识符syn = 100;//标识符种别码}return;}else if(isDigit(project[p])){//以数字开头token[count++] = project[p++];while(isDigit(project[p]))//后面是数字{token[count++] = project[p++];}token[count] = '\0';syn = 99;return;}else if(ch == '+' || ch == '-' || ch == '*' || ch == '/' || ch == ';' || ch == '(' || ch == ')' || ch == '^'|| ch == ',' || ch == '\"' || ch == '\'' || ch == '~' || ch == '#' || ch == '%' || ch == '['|| ch == ']' || ch == '{' || ch == '}' || ch == '\\' || ch == '.' || ch == '\?' || ch == ':'){token[count++] = project[p++];token[count] = '\0';for(int i=0;i<36;++i){if(strcmp(operatorOrDelimiter[i],token) == 0){syn = 33+i;break;}}return;}else if(ch == '<'){//可能是< <= <<++p;if(project[p] == '=')//<={syn = 38;}if(project[p] == '<')//<<{syn = 58;}else//<{--p;syn = 37;}++p;return;}else if(ch == '>'){//可能是> >= >>++p;if(project[p] == '=')//>={syn = 40;}if(project[p] == '>')//>>{syn = 59;}else//>{--p;syn = 39;}++p;return;}else if(ch == '='){//可能是= ==++p;if(project[p] == '=')//=={syn = 42;}else{//=--p;syn = 41;}++p;return;}else if(ch == '!'){//可能是! !=++p;if(project[p] == '=')//=={syn = 43;}else{--p;syn = 68;}++p;return;}else if(ch == '&'){//可能是& &&++p;if(project[p] == '&')//&&{syn = 53;}else{//&--p;syn = 52;}++p;return;}else if(ch == '|'){//可能是| ||++p;if(project[p] == '|')//||{syn = 55;}else{--p;syn = 54;}++p;return;}else if(ch == '\0')//文件结束{syn = 0;}else{cout<<"wrong letter:"<<ch<<endl;exit(0);}}
scanner()函数对过滤后的源文件逐字符扫描,直至文件结束(遇到'\0')
程序入口
int main(){//打开一个文件,读取源程序char project[10000];char token[20] = {0};int syn = -1;int p = 0; //程序位置索引ifstream in("test.txt");ofstream out("out.txt");if(!in.is_open()){cout << "error opening file!"<<endl;exit(0);}while(!in.eof()){in.get(project[p++]);}project[p++] = '\0';in.close();cout<<"源程序为:\n"<<project<<endl;filter(project,p);cout<<"过滤后的源程序为:\n"<<project<<endl;p = 0;while(syn != 0)//开始扫描{scanner(syn,project,token,p);if(syn == 100)//标识符{for(int i = 0;i<1000;i++){//插入标识符表if(strcmp(IDentifierTbl[i],token) == 0){//已存在表中break;}else if(strcmp(IDentifierTbl[i],"") == 0){strcpy(IDentifierTbl[i],token);break;}}cout<<"标识符:"<<token<<endl;out<<"标识符:"<<token<<endl;}else if(syn == 99)//常数{cout<<"常数:"<<token<<endl;out<<"常数:"<<token<<endl;}else if(syn <= 32 && syn >= 1)//保留字{cout<<reserveWord[syn - 1]<<":"<<syn<<endl;out<<reserveWord[syn - 1]<<":"<<syn<<endl;}else if(syn >= 33 && syn <= 68)//运算符或界符{cout<<operatorOrDelimiter[syn - 33]<<":"<<syn<<endl;out<<operatorOrDelimiter[syn - 33]<<":"<<syn<<endl;}}out.close();system("pause");}
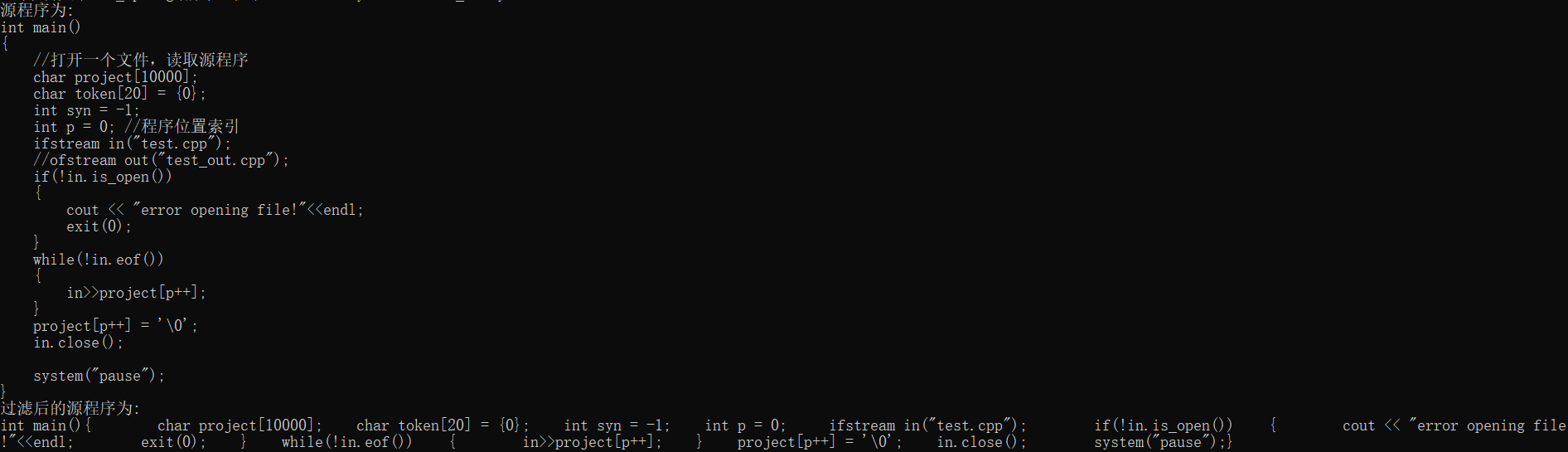
使用内容如下的文件进行测试
int main()
{
//打开一个文件,读取源程序
char project[10000];
char token[20] = {0};
int syn = -1;
int p = 0; //程序位置索引
ifstream in("test.cpp");
//ofstream out("test_out.cpp");
if(!in.is_open())
{
cout << "error opening file!"< exit(0);
}
while(!in.eof())
{
in>>project[p++];
}
project[p++] = '\0';
in.close();
system("pause");
}