@windmelon
2019-03-27T10:59:16.000000Z
字数 11260
阅读 3219
Linux系统分析实验(三):理解进程创建、可执行文件的加载和进程执行进程切换,重点理解分析fork、execve和进程切换
Linux系统分析实验
原创作品转载请注明出处https://github.com/mengning/linuxkernel/
sa18225465
实验环境
ubuntu 18.04 虚拟机
VMware workstation 14 Player
实验目的
- 理解创建一个新进程如何创建和修改task_struct数据结构
- 理解linux创建新进程的过程
- 理解编译链接的过程和ELF可执行文件格式
- 理解Linux系统加载可执行程序过程
- 理解Linux系统中进程调度的时机
实验步骤
task_struck数据结构
Linux内核通过一个被称为进程描述符的task_struct结构体来管理进程,这个结构体包含了一个进程所需的所有信息。它定义在include/linux/sched.h文件中
task_struct结构体中的主要信息:
1. 进程状态:记录进程是处于运行状态还是等待状态
2. 调度信息:进程由哪个函数调度,具体怎样调度等
3. 进程之间的通讯状况
4. 进程之间的亲属关系:在父进程和子进程之间有task_struct类型的指针,将父进程和子进程联系起来
5. 时间数据信息:每个进程执行所占用CPU的时间
6. 进程的标志
7. 进程的标识符:该进程唯一的标识符用来区别其他进程
8. 信号处理信息
9. 文件信息:可以进行读写操作的一些文件的信息
10. 页面管理信息
11. 优先级:相对于其他进程的优先级
12. ptrace系统调用
13. 虚拟内存处理
进程状态
Linux中的进程由多种状态,在运行的过程中,进程会随着调度在多种情况下转换,进程的信息是进程进行调度的对换的依据。
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */int exit_state;
表示进程的运行状态,-1为不可运行,0可以运行,大于0表示停止。
内核中状态的表示有以下几种:
#define TASK_RUNNING 0#define TASK_INTERRUPTIBLE 1#define TASK_UNINTERRUPTIBLE 2#define __TASK_STOPPED 4#define __TASK_TRACED 8/* in tsk->exit_state */#define EXIT_ZOMBIE 16#define EXIT_DEAD 32/* in tsk->state again */#define TASK_DEAD 64#define TASK_WAKEKILL 128#define TASK_WAKING 256
系统中的每个进程都必然处于以上所列进程状态中的一种。
TASK_RUNNING表示进程要么正在执行,要么正要准备执行。
TASK_INTERRUPTIBLE表示进程被阻塞(睡眠),直到某个条件变为真。条件一旦达成,进程的状态就被设置为TASK_RUNNING。
TASK_UNINTERRUPTIBLE的意义与TASK_INTERRUPTIBLE类似,除了不能通过接受一个信号来唤醒以外。
__TASK_STOPPED表示进程被停止执行。
__TASK_TRACED表示进程被debugger等进程监视。
EXIT_ZOMBIE表示进程的执行被终止,但是其父进程还没有使用wait()等系统调用来获知它的终止信息。
EXIT_DEAD表示进程的最终状态。
EXIT_ZOMBIE和EXIT_DEAD也可以存放在exit_state成员中。
进程的标志
当前进程的标志,用于内核识别当前进程的状态,以备下一步操作。
unsigned int flags; /* per process flags, defined below */
flags的取值有以下几种情况:
#define PF_KSOFTIRQD 0x00000001 /* I am ksoftirqd */#define PF_STARTING 0x00000002 /* being created */#define PF_EXITING 0x00000004 /* getting shut down */#define PF_EXITPIDONE 0x00000008 /* pi exit done on shut down */#define PF_VCPU 0x00000010 /* I'm a virtual CPU */#define PF_WQ_WORKER 0x00000020 /* I'm a workqueue worker */#define PF_FORKNOEXEC 0x00000040 /* forked but didn't exec */#define PF_MCE_PROCESS 0x00000080 /* process policy on mce errors */#define PF_SUPERPRIV 0x00000100 /* used super-user privileges */#define PF_DUMPCORE 0x00000200 /* dumped core */#define PF_SIGNALED 0x00000400 /* killed by a signal */#define PF_MEMALLOC 0x00000800 /* Allocating memory */#define PF_USED_MATH 0x00002000 /* if unset the fpu must be initialized before use */#define PF_FREEZING 0x00004000 /* freeze in progress. do not account to load */#define PF_NOFREEZE 0x00008000 /* this thread should not be frozen */#define PF_FROZEN 0x00010000 /* frozen for system suspend */#define PF_FSTRANS 0x00020000 /* inside a filesystem transaction */#define PF_KSWAPD 0x00040000 /* I am kswapd */#define PF_OOM_ORIGIN 0x00080000 /* Allocating much memory to others */#define PF_LESS_THROTTLE 0x00100000 /* Throttle me less: I clean memory */#define PF_KTHREAD 0x00200000 /* I am a kernel thread */#define PF_RANDOMIZE 0x00400000 /* randomize virtual address space */#define PF_SWAPWRITE 0x00800000 /* Allowed to write to swap */#define PF_SPREAD_PAGE 0x01000000 /* Spread page cache over cpuset */#define PF_SPREAD_SLAB 0x02000000 /* Spread some slab caches over cpuset */#define PF_THREAD_BOUND 0x04000000 /* Thread bound to specific cpu */#define PF_MCE_EARLY 0x08000000 /* Early kill for mce process policy */#define PF_MEMPOLICY 0x10000000 /* Non-default NUMA mempolicy */#define PF_MUTEX_TESTER 0x20000000 /* Thread belongs to the rt mutex tester */#define PF_FREEZER_SKIP 0x40000000 /* Freezer should not count it as freezable */#define PF_FREEZER_NOSIG 0x80000000 /* Freezer won't send signals to it */
进程的标识符
每一个进程都拥有自己的进程标识符、用户标识符、组标识符
进程标识符PID是用来表示不同进程的,每一个进程都有唯一的标识符,内核就是通过这个标识符来识别不同的进程的。
pid_t pid;pid_t tgid;
pid:进程标识符
tpid:线程的组号
进程间的亲属关系
进程的创建是具有继承关系的,一个进程可以创建多个子进程,该进程是这些子进程的父进程,这些子进程之间具有兄弟的关系。
在创建子进程的时候,子进程会继承父进程的大部分信息,也就是说子进程会将父进程的task_struct结构体中的大部分信息拷贝过来,除过pid,因而系统需要记录这些亲属关系,以便进程之间的协作。
每个进程的task_struct结构体中有许多指针,这些指针将所有的进程的task _struct结构连接起来,构成了一棵进程树。
/** pointers to (original) parent process, youngest child, younger sibling,* older sibling, respectively. (p->father can be replaced with* p->real_parent->pid)*/struct task_struct __rcu *real_parent; /* real parent process */struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports *//** children/sibling forms the list of my natural children*/struct list_head children; /* list of my children */struct list_head sibling; /* linkage in my parent's children list */struct task_struct *group_leader; /* threadgroup leader */
real_parent指向其父进程,如果创建它的父进程不再存在,则指向PID为1的init进程。
parent指向其父进程,当它终止时,必须向它的父进程发送信号。它的值通常与real_parent相同。
children表示链表的头部,链表中的所有元素都是它的子进程。
sibling用于把当前进程插入到兄弟链表中。
group_leader指向其所在进程组的领头进程。
ptrace系统调用
ptrace系统调用提供了父进程可以观察和控制子进程执行的能力,并允许父进程检查和替换子进程的内核镜像(包括寄存器)的值。基本原理:当使用了ptrace跟踪后,所有发送给被跟踪的子进程的信号,都会被转发给父进程,而子进程被阻塞。而父进程收到信号后,就可以对停下来的子进程进行检查和修改,然后让子进程继续运行。我们常用的调试工具gdb就是基于ptrace来实现的。
unsigned int ptrace;struct list_head ptraced;struct list_head ptrace_entry;unsigned long ptrace_message;siginfo_t *last_siginfo; /* For ptrace use. */#ifdef CONFIG_HAVE_HW_BREAKPOINTatomic_t ptrace_bp_refcnt;#endif
进程的调度信息
进程调度是利用这部分信息来决定进程执行的有限次序,结合着进程的状态信息来保证进程合理有序的运行。
const struct sched_class *sched_class;struct sched_entity se;struct sched_rt_entity rt;
sched_class:调度类
se:普通进程的调用实体
rt:实时进程的调用实体
每个进程都有se/rt其中之一的实体
进程优先级
int prio, static_prio, normal_prio;unsigned int rt_priority;
static_prio用于保存静态优先级,可以通过nice系统调用来进行修改。
rt_priority用于保存实时优先级。
normal_prio的值取决于静态优先级和调度策略。
prio用于保存动态优先级。
时间数据信息
cputime_t utime, stime, utimescaled, stimescaled;cputime_t gtime;cputime_t prev_utime, prev_stime;unsigned long nvcsw, nivcsw; /* context switch counts */struct timespec start_time; /* monotonic time */struct timespec real_start_time; /* boot based time *//* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */unsigned long min_flt, maj_flt;struct task_cputime cputime_expires;struct list_head cpu_timers[3];
utime/stime用于记录进程在用户态/内核态下所经过的节拍数(定时器)
prev_utime/prev_stime是先前的运行时间
utimescaled/stimescaled也是用于记录进程在用户态/内核态的运行时间,但它们以处理器的频率为刻度
gtime是以节拍计数的虚拟机运行时间(guest time)
nvcsw/nivcsw是自愿(voluntary)/非自愿(involuntary)上下文切换计数
last_switch_count是nvcsw和nivcsw的总和
start_time和real_start_time都是进程创建时间,real_start_time还包含了进程睡眠时间,常用于/proc/pid/stat
进程之间的通信
如果多个进程在一个任务上执行协作,那么就需要这些进程可以相互访问对方的资源,相互通信。
Linux中的主要进程通信方式有:管道、信号量、内存共享、信号和消息队列
#ifdef CONFIG_SYSVIPC/* ipc stuff */struct sysv_sem sysvsem;#endif
文件
进程可以打开或者关闭文件,文件属于系统资源,Linux内核要对进程使用文件的情况进行记录。task_struct结构体中有两个数据结构用于描述进程与文件相关的信息。其中fs _struct中描述了两个VFS索引节点,这两个索引节点叫做root和pwd,分别指向进程的可执行影响所对应的根目录和当前目录或者工作目录。file _struct结构用来记录了进程打开的文件的描述符。
/* file system info */int link_count, total_link_count;/* filesystem information */struct fs_struct *fs;/* open file information */struct files_struct *files;
fs用来表示进程与文件系统的联系,包括当前目录和根目录。
files表示进程当前打开的文件。
信号处理信息
struct signal_struct *signal;struct sighand_struct *sighand;sigset_t blocked, real_blocked;sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */struct sigpending pending;unsigned long sas_ss_sp;size_t sas_ss_size;int (*notifier)(void *priv);void *notifier_data;sigset_t *notifier_mask;
signal指向进程的信号描述符。
sighand指向进程的信号处理程序描述符。
blocked表示被阻塞信号的掩码,real_blocked表示临时掩码。
pending存放私有挂起信号的数据结构。
sas_ss_sp是信号处理程序备用堆栈的地址,sas_ss_size表示堆栈的大小。
设备驱动程序常用notifier指向的函数来阻塞进程的某些信号(notifier_mask是这些信号的位掩码),notifier_data指的是notifier所指向的函数可能使用的数据。
虚拟内存处理
struct mm_struct *mm, *active_mm;
mm _struct用来描述每个进程的地址空间(虚拟空间)
mm指向进程所拥有的内存描述符,而active_mm指向进程运行时所使用的内存描述符。
对于普通进程而言,这两个指针变量的值相同。但是,内核线程不拥有任何内存描述符,所以它们的mm成员总是为NULL。当内核线程得以运行时,它的active_mm成员被初始化为前一个运行进程的active_mm值。
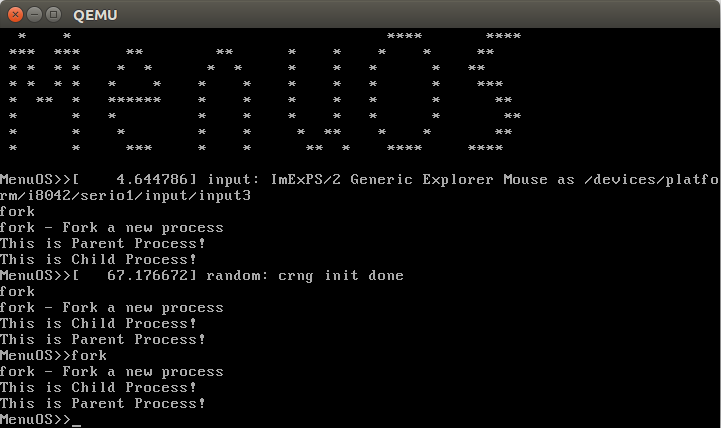
do_fork跟踪
设置断点到sys_clone()
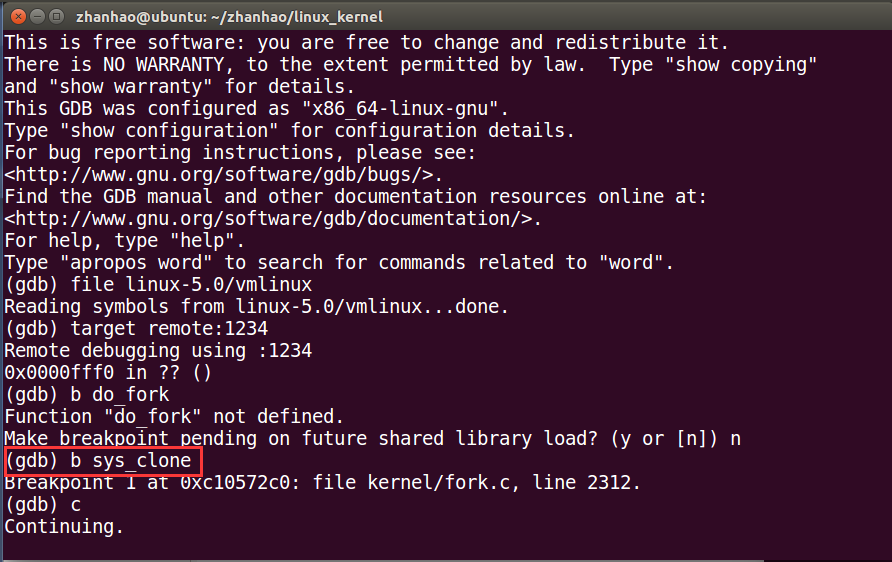
在menuOS中调用fork()
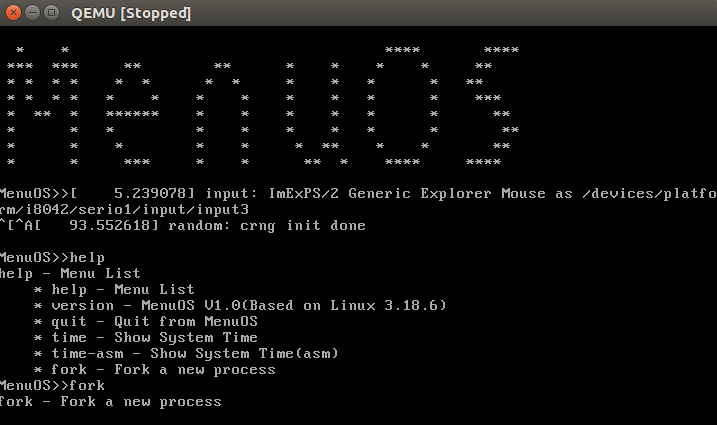
函数调用栈如下:
_do_fork()->copy_process()->dup_task_struct(),copy_thread_tls()
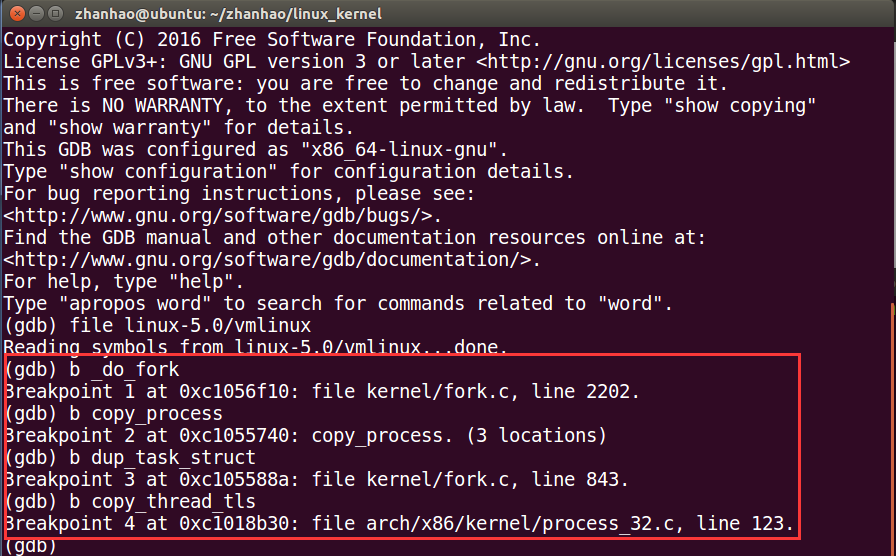
先进入_do_fork()
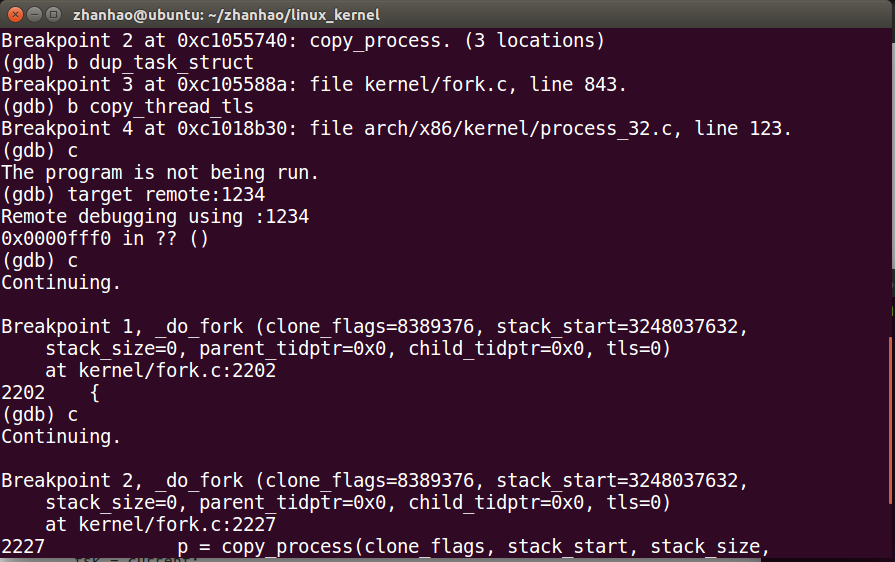
再进入copy_process()
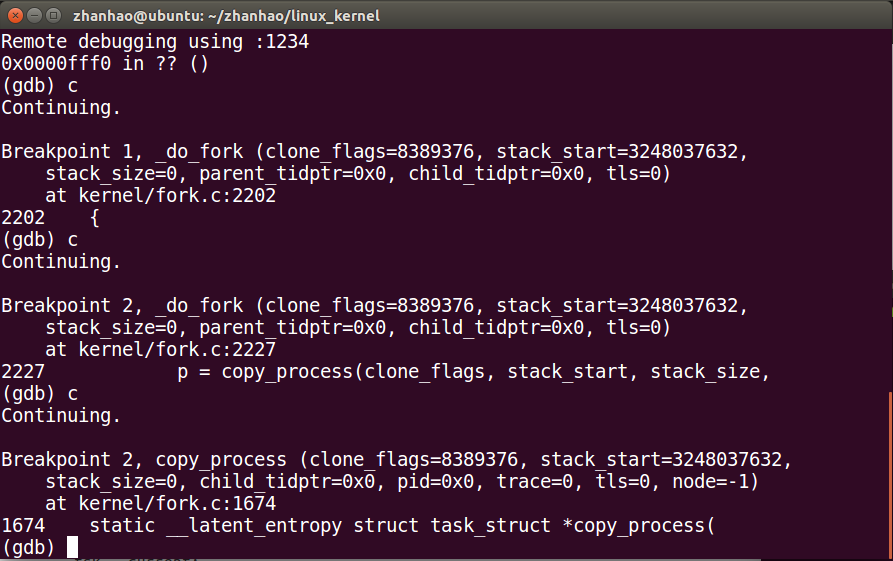
然后是dup_task_struct()
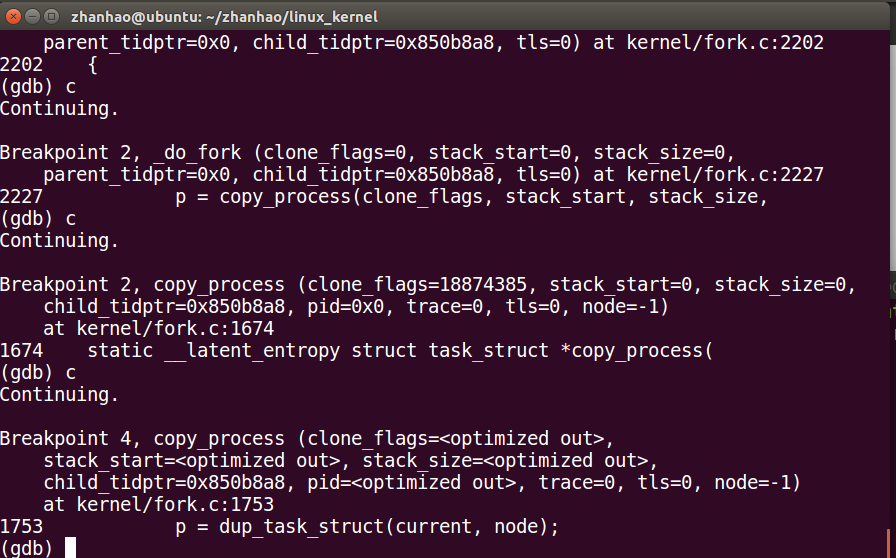
接下来是copy_thread_tls()
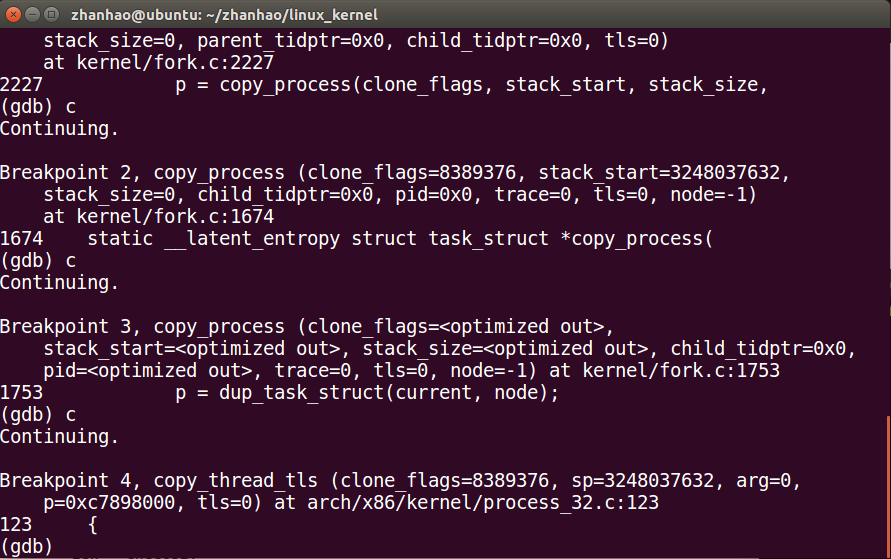
然后fork完成
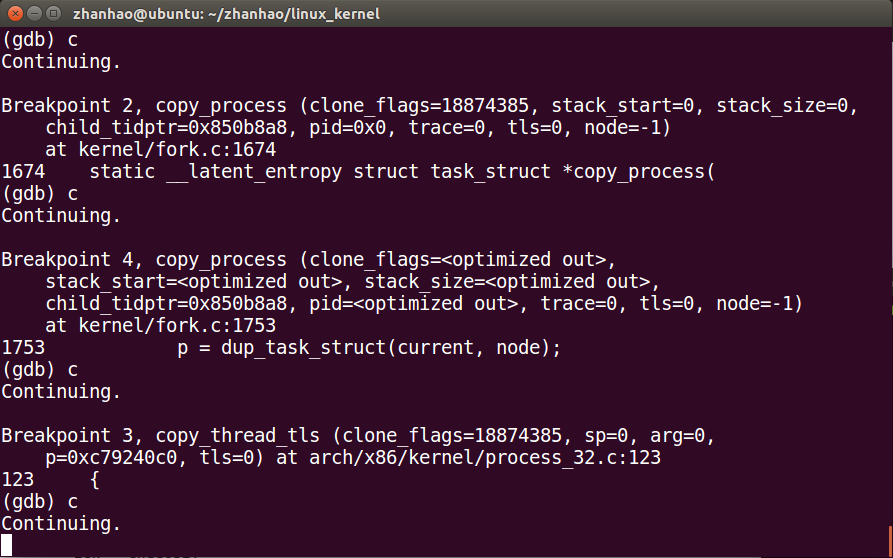
分析
_do_fork()是所有创建进程的系统函数最终调用的方法
新进程是从哪里开始执行的?为什么从哪里能顺利执行下去?执行起点与内核堆栈如何保证一致?
在copy_thread_tls()中
frame->bp = 0;frame->ret_addr = (unsigned long) ret_from_fork;p->thread.sp = (unsigned long) fork_frame;p->thread.sp0 = (unsigned long) (childregs+1);memset(p->thread.ptrace_bps, 0, sizeof(p->thread.ptrace_bps));...*childregs = *current_pt_regs();...
frame->ret_addr = (unsigned long) ret_from_fork;这句代码将子进程的返回地址设置为 ret_form_fork 的首地址因此子进程是从 ret_from_fork 开始执行的。
*childregs = *current_pt_regs();该句将父进程的regs参数赋值到子进程的内核堆栈,*childregs的类型为pt_regs,里面存放了SAVE ALL中压入栈的参数。故在之后的RESTORE ALL中能顺利执行下去。
编译链接的过程和ELF可执行文件格式
ELF文件
在x86架构下,Linux使用的是ELF(Executable and Linkable Format)目标文件格式。目标文件的三种格式:
Relocatable object file. 可重定位目标文件包含二进制代码和数据,编译时可与其他可重定位目标文件合并组成可执行目标文件,如 .o,.a文件。
Executable object file. 可执行目标文件包含二进制代码和数据,可以直接加载到内存并执行, 如 .out文件。
Shared object file. 共享目标文件是一种特殊类型的可重定位目标文件,可以在加载或运行时被动态的加载到内存并链接。如 .so文件。
编译连接的过程
静态链接:在形成可执行文件之前将所有目标文件装载
动态链接:在形成可执行文件的时候不对动态链接库中内容进行装载,而是在执行程序时动态装载
使用exec*库函数加载一个可执行文件
编写程序hello.c
#include <stdio.h>#include <stdlib.h>#include <unistd.h>int main(int argc,char* argv[]){int pid;/*fork another process*/pid = fork();if(pid < 0){/*error occurred*/fprintf(stderr,"Fork Failed!\n");exit(-1);}else if(pid == 0){/* child process */execlp("/bin/ls","ls",NULL);}else{/* parent process *//* parent will wait for the child to complete */wait(NULL);printf("Child Complete\n");exit(0);}}
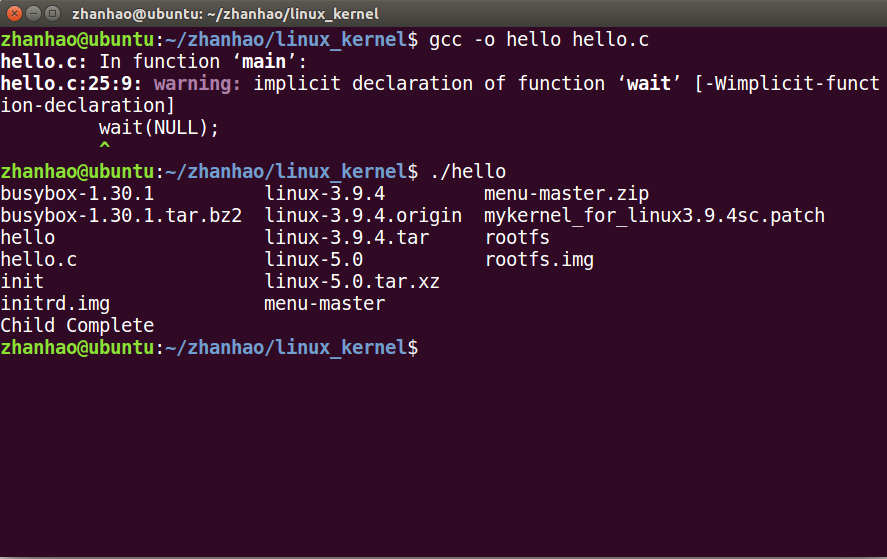
do_execve跟踪
设置三个断点:sys_execve,load_elf_binary,start_thread
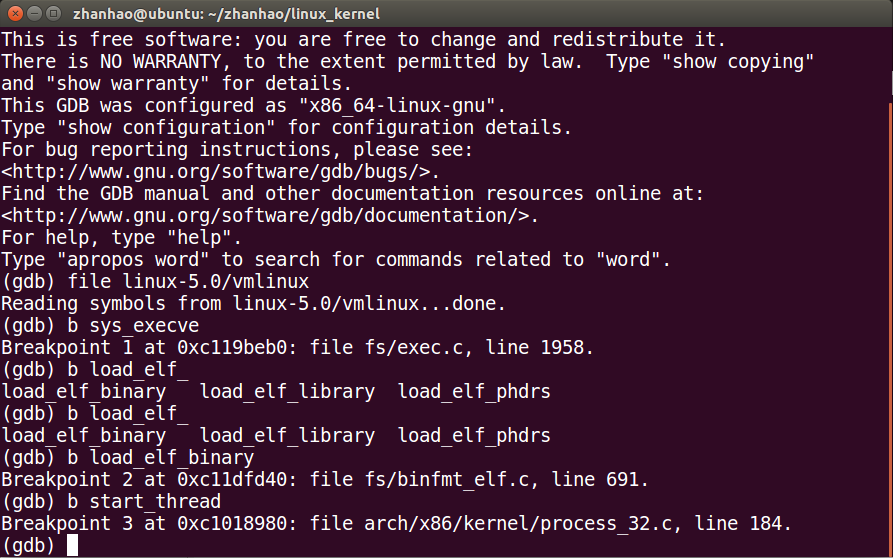
先sys_execve系统调用
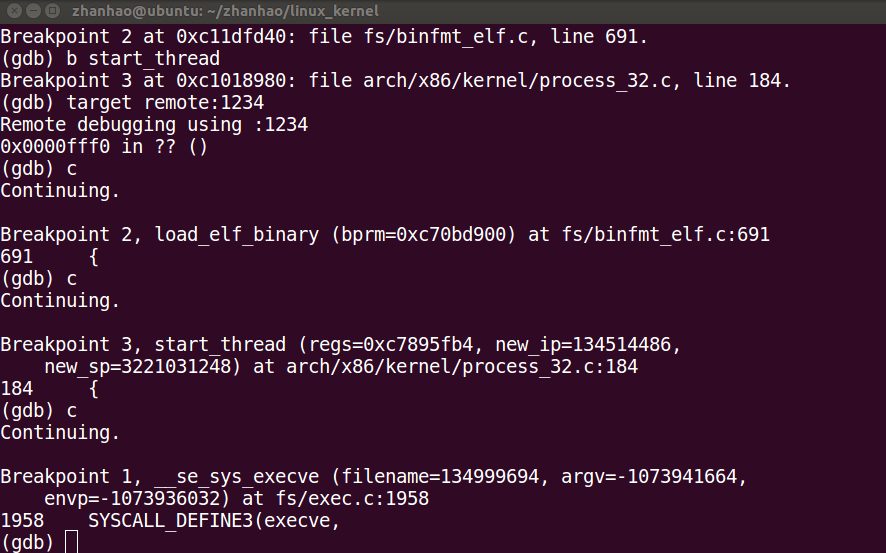
然后load_elf_binary()
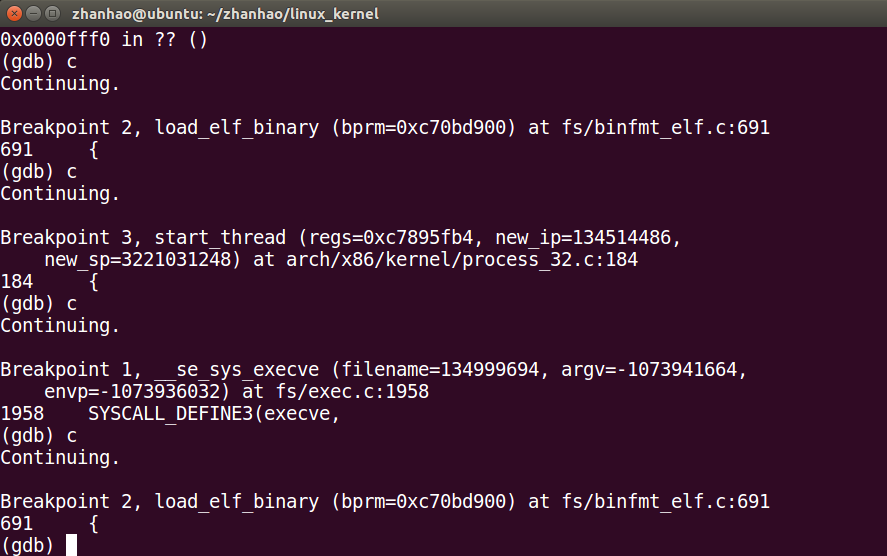
再start_thread()
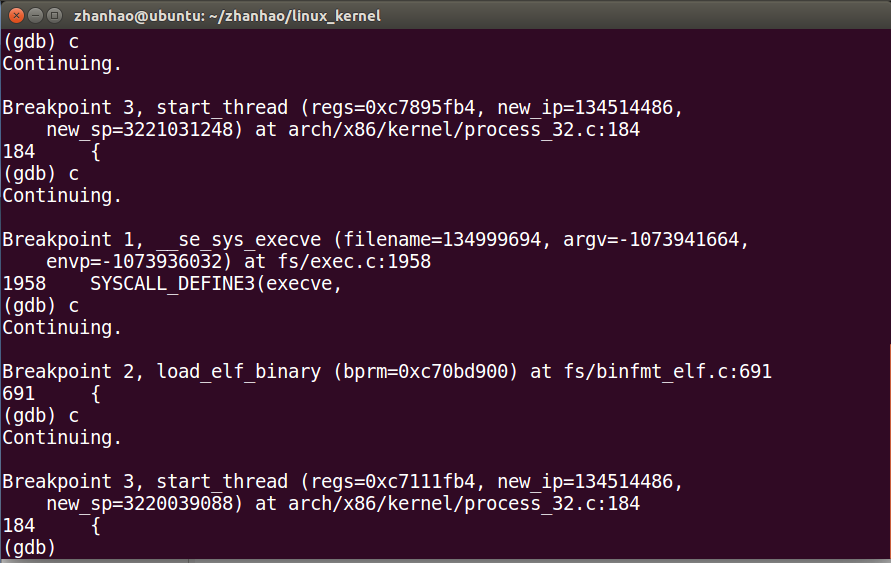
最后调用完毕
新的可执行程序是从哪里开始执行的?
当execve()系统调用终止且进程重新恢复它在用户态执行时,执行上下文被大幅度改变,要执行的新程序已被映射到进程空间,从elf头中的程序入口点开始执行新程序。
如果这个新程序是静态链接的,那么这个程序就可以独立运行,elf头中的这个入口地址就是本程序的入口地址。
如果这个新程序是动态链接的,那么此时还需要装载共享库,elf头中的这个入口地址是动态链接器ld的入口地址。
为什么execve系统调用返回后新的可执行程序能顺利执行?
新的可执行程序执行,需要以下:
1. 它所需要的库函数。
2. 属于它的进程空间:代码段,数据段,内核栈,用户栈等。
3. 它所需要的运行参数。
4. 它所需要的系统资源。
如果满足以上4个条件,那么新的可执行程序就会处于可运行态,只要被调度到,就可以正常执行。我们一个一个看这几个条件能不能满足。
条件1:如果新进程是静态链接的,那么库函数已经在可执行程序文件中,条件满足。如果是动态链接的,新进程的入口地址是动态链接器ld的起始地址,可以完成对所需库函数的加载,也能满足条件。
条件2:execve系统调用通过大幅度修改执行上下文,将用户态堆栈清空,将老进程的进程空间替换为新进程的进程空间,新进程从老进程那里继承了所需要的进程空间,条件满足。
条件3:我们一般在shell中,输入可执行程序所需要的参数,shell程序把这些参数用函数参数传递的方式传给给execve系统调用,然后execve系统调用以系统调用参数传递的方式传给sys_execve,最后sys_execve在初始化新程序的用户态堆栈时,将这些参数放在main函数取参数的位置上。条件满足。
条件4:如果当前系统中没有所需要的资源,那么新进程会被挂起,直到资源有了,唤醒新进程,变为可运行态,条件可以满足。
综上所述,新的可执行程序可以顺利执行。
对于静态链接的可执行程序和动态链接的可执行程序execve系统调用返回时会有什么不同?
execve系统调用会调用sys_execve,然后sys_execve调用do_execve,然后do_execve调用do_execve_common,然后do_execve_common调用exec_binprm
对于ELF文件格式,fmt函数指针实际会执行load_elf_binary,load_elf_binary会调用start_thread,在start_thread中通过修改内核堆栈中EIP的值,使其指向elf_entry,跳转到elf_entry执行。
对于静态链接的可执行程序,elf_entry是新程序的执行起点。对于动态链接的可执行程序,需要先加载链接器ld,
elf_entry = load_elf_interp(…)
将CPU控制权交给ld来加载依赖库,再由ld在完成加载工作后将CPU控制权还给新进程。
Linux系统中进程调度的时机
- 中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();
- 内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
- 用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
schedule跟踪
设置四个断点:schedule,context_switch,switch_to,pick_next_task
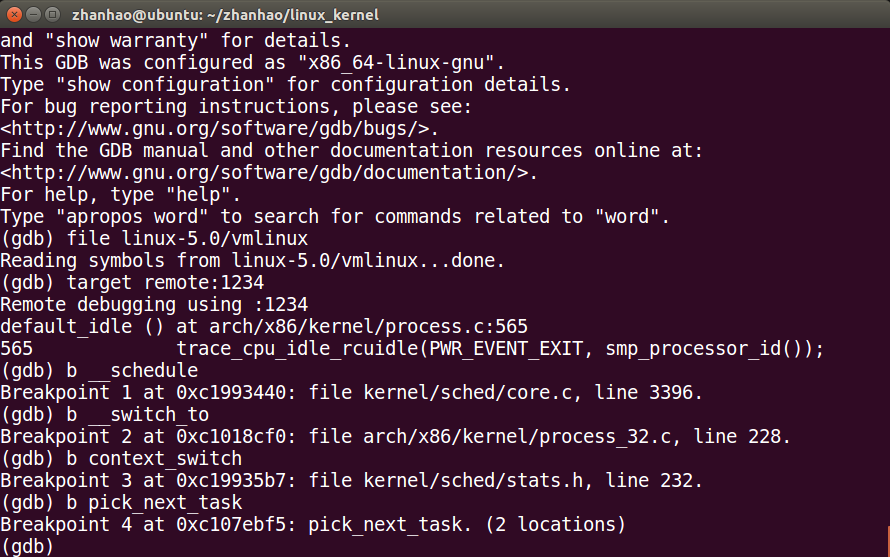
函数调用栈:
__schedule->pick_next_task->context_switch->__switch_to
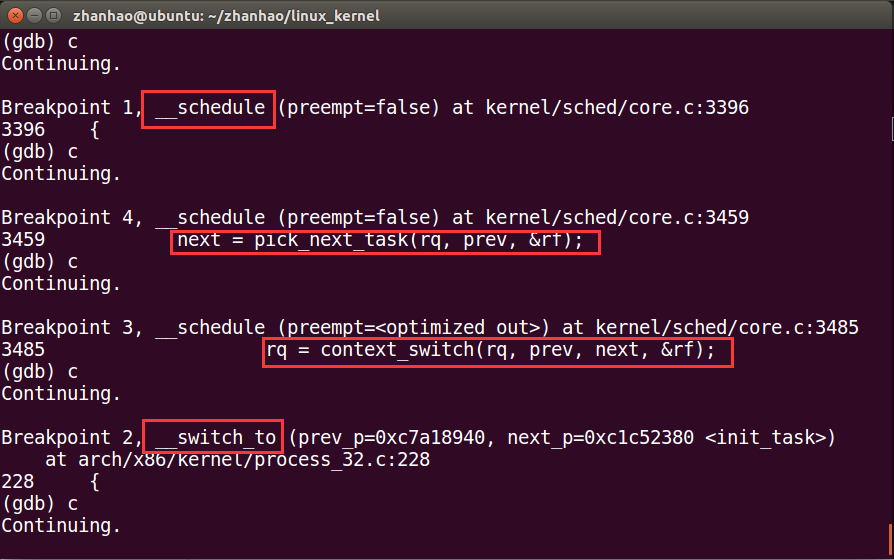
switch_to实现了进程之间的真正切换:
- 首先在当前进程prev的内核栈中保存esi,edi及ebp寄存器的内容。
- 然后将prev的内核堆栈指针ebp存入prev->thread.esp中。
- 把将要运行进程next的内核栈指针next->thread.esp置入esp寄存器中
- 将popl指令所在的地址保存在prev->thread.eip中,这个地址就是prev下一次被调度
- 通过jmp指令(而不是call指令)转入一个函数__switch_to()
- 恢复next上次被调离时推进堆栈的内容。从现在开始,next进程就成为当前进程而真正开始执行
实验总结
通过系统调用,用户空间的应用程序就会进入内核空间,由内核代表该进程运行于内核空间,这就涉及到上下文的切换,用户空间和内核空间具有不同的地址映射,通用或专用的寄存器组,而用户空间的进程要传递很多变量、参数给内核,内核也要保存用户进程的一些寄存器、变量等,以便系统调用结束后回到用户空间继续执行,所谓的进程上下文,就是一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容,当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。
同理,硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理,中断上下文就可以理解为硬件传递过来的这些参数和内核需要保存的一些环境,主要是被中断的进程的环境。
Linux内核工作在进程上下文或者中断上下文。提供系统调用服务的内核代码代表发起系统调用的应用程序运行在进程上下文;另一方面,中断处理程序,异步运行在中断上下文。中断上下文和特定进程无关。
运行在进程上下文的内核代码是可以被抢占的(Linux2.6支持抢占)。但是一个中断上下文,通常都会始终占有CPU(当然中断可以嵌套,但我们一般不这样做),不可以被打断。正因为如此,运行在中断上下文的代码就要受一些限制
