@stike
2017-08-13T15:21:47.000000Z
字数 3788
阅读 408
R学习计划 - leaflet包学习笔记
可视化 交互地图 rvest httr R学习笔记
首先道歉,最近实在太忙,一直没时间交作业。 正好今天空着,干脆自己折腾一份分析报告,把刚发现的leaflet包和最近经常用的httr和rvest包功能整合在一起使用,就有了这个学习笔记。当作自己练手项目的记录,也算让大家知道数据抓取/清洗/分析/可视化整个流程是怎么走完的。
我对中国的学校资源分布其实蛮感兴趣的,所以虚设了这个分析项目,以练代学吧,自觉没有程序猿的天赋,代码质量垃圾也凑合看吧,谢了。
leaflet包介绍
leaflet包是Rstudio旗下一个非常好用的地图交互包,可以通过R语言实现优秀的交互地图可视化展现。 它基于leaflet.js项目封装,可以说是真正的交互地图利器。
原项目地址:http://leafletjs.com/
leaflet for R: http://rstudio.github.io/leaflet/
安装:
install.packages("leaflet")library(leaflet)
leaflet包生态介绍
leaflet包除了rstudio公司推出的原生包之外,也有强大的生态支持。尤其推荐leafletCN包,将leaflet的本土化推进了一大步。
leafletCN:基于leaflet的中国大陆包,将地图信息支持落到了县级,并加入了高德地图支持,没错就是那个高德地图- -~
install.packages("leafletCN")library(leafletCN)
leaflet.extras: 一个leaflet的插件包,为leaflet加入了很多额外功能,比如热力图。
install.packages('leaflet.extras')
--
github上往往有更新的版本,相较于cran更新更快,但需要devtools包支持。
devtools::install_github('rstudio/leaflet')devtools::install_github('bhaskarvk/leaflet.extras')
练习笔记正文 : 分析中国高校分布情况
加载用到的包如下:
library(rvest) #很方便的爬虫library(httr) #抓取解析JSONlibrary(stringr) #清洗文本信息的利器library(DataExplorer) #数据简报快速生成工具,数据检查快报神器。。。library(leaflet.extras) #为热图准备的library(leaflet) #扯了半天还是用leaflet...
下面是爬虫部分。
# 该部分为生成高校信息抓取,没错我爬了阳光高校网,很抱歉占用了你们的带宽,但我真的只访问了134个页面233.url <- c() #初始化urlfor(i in 1:134){url[i] <- paste("http://gaokao.chsi.com.cn/sch/search--ss-on,searchType-1,option-qg,start-",(i-1)*20,".dhtml",sep="")}college_list <- data.frame() #最终信息保存到这个数据框内for(j in 1:134){read_html(url[j]) -> webweb %>% html_table(header = T) %>% .[4] -> college_list_tempas.data.frame(college_list_temp) -> college_list_temprbind(college_list,college_list_temp) -> college_listSys.sleep(2) #没错,我设置了休眠防止被封。。。}
抓取之后,由于学校名称字段包含了985,211,研究生字段,所以我设置了几个判断,通过字段添加了几个分析变量。
grepl("研",college_list$院校名称)-> college_list$是否设研究生院grepl("985",college_list$院校名称)-> college_list$is_985 #985院校grepl("211",college_list$院校名称)-> college_list$is_211 #211院校as.factor(college_list$所在地) -> college_list$所在地as.factor(college_list$院校隶属) -> college_list$院校隶属as.factor(college_list$学历层次) -> college_list$学历层次as.factor(college_list$办学类型) -> college_list$办学类型as.factor(college_list$院校类型) -> college_list$院校类型str_replace_all(string = college_list$院校名称,pattern ="[\\r\\t]",replacement = "") -> college_list$院校名称college_list$院校名称 %>% str_replace_all("985|211| 研","") %>% str_replace_all(" ","") -> college_list$院校名称 #洗掉了这些字段
漫漫采集路才刚刚开始,有了学校名字我并不能干什么,虽然我们可以分析点简单的信息,但我最初的目的是分析学校资源分布情况啊.
#我们先把清洗完的学校名字取出来,这就是我为啥要洗名字了。college_list$院校名称 -> college_name#地址初始化address <- c()#经纬度初始化lat <- vector()lng <- vector()
下面,通过谷歌地图的api抓经纬度及地址信息,没错,并没有被墙,但是悲催的是限制每日查询2500条。。。 你可以分两天跑完,也可以注册个独立的api。
for(k in 1:length(college_name)){json_address <- paste("https://maps.google.cn/maps/api/geocode/json?address=",college_name[k],sep = "")# json_address <- paste(json_address,"&key=<your api key>",sep="")GET(json_address) -> json_1content(json_1,"parsed") -> json_1# 这里撞了个小坑,我没想到我们的谷歌大神也会有搜不到的地方所以跑到一半报错了,我补了个检查条件,当抓取api为空的时候,跳过这一条记录,并标记为0经纬度。if(json_1$status=="ZERO_RESULTS") {"NA" -> address[k]0 -> lat[k]0 -> lng[k]} else {json_1$results[[1]]$formatted_address -> address[k]json_1$results[[1]]$geometry$location$lat -> lat[k]json_1$results[[1]]$geometry$location$lng -> lng[k]Sys.sleep(1)}}
这次我们的采集量高到了2663个页面,没错,中国的大学就有那么多家,速度感觉有点慢,看来我要抽空学并发采集了。。。 不过要学的东西真的好多!>_<
下面是简单的分析,我们先来看看表的结构:
嗯,我们有地区,院校隶属机构,学历层次,办学类型,学校类型,985,211,研究生院等各种信息,这意味着我们可以很直观的了解到中国学校的现状。
我们来看看简单的分布情况。
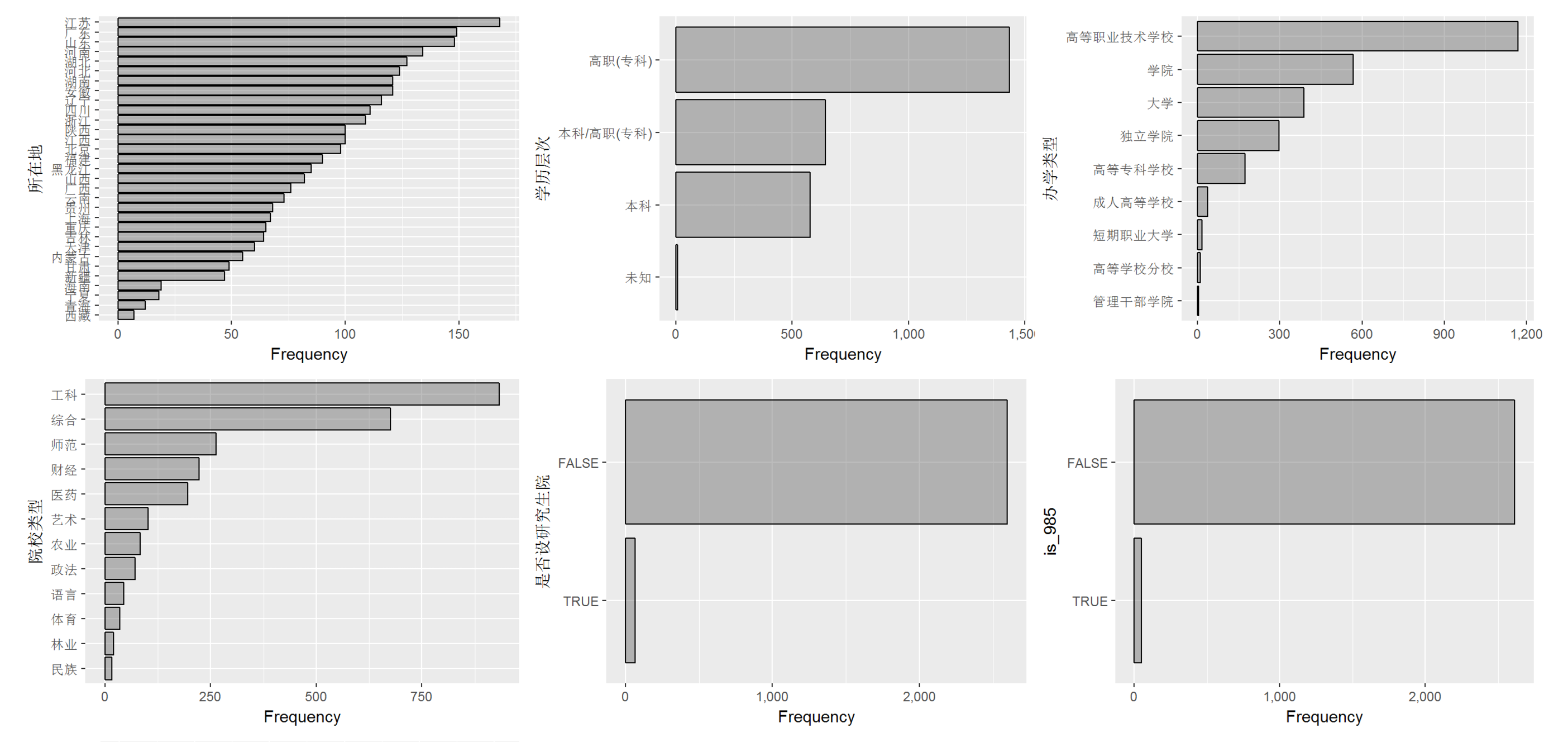
果然,人口和学校多寡直接成正比。 高职类院校是最多的,而在学科中,工科学校比综合院校还要多。。。
采集完成后,我们又要清洗数据了,把那些没有地址的数据给洗掉,没错,我们还有地址不明的学校。。。 或者你可以试试自己手动补数据,反正也不多,有23家学校被我们清洗出局。
data.frame(college_list,address,lat,lng) -> college_listcollege_list[address!="NA",] -> college_list
最后,我们画个热力图看看
# 第一步:取出经纬度地址college_list[,c("lat","lng")]-> lat_lng#第二步:设置初始数值和底图#setView的三个参数分别为:经度(lng),纬度(lat),缩放倍数leaf <- leaflet(lat_lng) %>%setView(116,40,3) %>%addProviderTiles(providers$OpenStreetMap.BlackAndWhite)# 我们添加一层热图看看leaf %>% addHeatmap(lng = ~lng,lat = ~lat,blur = 20, max = 0.15, radius = 15)
嗯,我们证明了中国的教育资源倾向于东部,尤其是沿海地区(等于没说,哈哈)。 或许下周我们会继续挖挖看,以上。
最终成品效果大家可以上这里查看:
http://rpubs.com/stike/colleges
```
