@kiraSally
2018-03-12T11:06:17.000000Z
字数 40455
阅读 5093
并发番@ThreadPoolExecutor一文通(1.8版)
JAVA 并发 1.8版
- 备注:鉴于JDK文档的英文注释过多,因此笔者选择摘录部分笔者认为最重要的部分,其他内容会以中文注释展现
- 推荐:笔者建议读者结合 并发番@Synchronized一文通(1.8版) 理解
- 推荐:笔者建议读者结合 并发番@AbstractQueuedSynchronizer一文通 理解
- 感谢支持:笔者个人博客 kiraSally的掘金个人博客
预告:笔者会新开并发番@Future一文通中进一步介绍带有返回值的线程池操作,到时会详细介绍AbstractExecutorService,因此本篇不会涉及太多知识;同时在并发番@Future一文通中,笔者同样会进一步介绍多样化的线程池配置使用以及Tomcat的线程池配置,敬请期待
1.开篇入题
1.1 如何创建更多线程
在Java中,您可以通过调整-Xss参数来调节每个线程栈的大小(64bit系统默认1024KB),当减小该值时意味着可以创建更多的线程数,但问题是JVM资源是有限的,线程不能无限创建!
您可以通过线程池控制线程数,线程池类似于连接池,其可以通过复用有限数量的线程数有效的降低频繁创建和销毁线程的开销;同时线程池可以完美处理生产者-消费者模式,提交任务相当于生产,执行任务相当于消费
1.2 线程池综述
- 从笔者开发经验来看,线程池应该是并发包中使用频率和运用场景最多的并发框架,几乎所有并发/异步执行任务的需求都需要用到线程池,线程复用,以内部线程池的形式对外提供管理任务执行,线程调度,线程池管理等等服务。合理的使用线程池可以带来如下三个好处:
-
1.降低资源消耗:通过重用已创建的线程来降低线程创建和销毁的消耗
-
2.提高响应速度:任务到达时不需要等待线程创建就可以立即执行
-
3.提高线程的可管理性:线程池可以统一管理、分配、调优和监控
2.线程池组成
2.1 类定义
public class ThreadPoolExecutor extends AbstractExecutorService
2.2 构造器
/*** 线程工厂默认为DefaultThreadFactory* 饱和策略默认为AbortPolicy*/public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue) {this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,Executors.defaultThreadFactory(), defaultHandler);}/*** 线程工厂可配置* 饱和策略默认为AbortPolicy*/public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory) {this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,threadFactory, defaultHandler);}/*** 线程工厂默认为DefaultThreadFactory* 饱和策略可配置*/public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler) {this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,Executors.defaultThreadFactory(), handler);}/*** 线程工厂可配置* 饱和策略可配置*/public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.acc = System.getSecurityManager() == null ?null : AccessController.getContext();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;}
2.3 重要变量
//线程池控制器private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));//任务队列private final BlockingQueue<Runnable> workQueue;//全局锁private final ReentrantLock mainLock = new ReentrantLock();//工作线程集合private final HashSet<Worker> workers = new HashSet<Worker>();//终止条件 - 用于等待任务完成后才终止线程池private final Condition termination = mainLock.newCondition();//曾创建过的最大线程数private int largestPoolSize;//线程池已完成总任务数private long completedTaskCount;//工作线程创建工厂private volatile ThreadFactory threadFactory;//饱和拒绝策略执行器private volatile RejectedExecutionHandler handler;//工作线程活动保持时间(超时后会被回收) - 纳秒private volatile long keepAliveTime;/*** 允许核心工作线程响应超时回收* false:核心工作线程即使空闲超时依旧存活* true:核心工作线程一旦超过keepAliveTime仍然空闲就被回收*/private volatile boolean allowCoreThreadTimeOut;//核心工作线程数private volatile int corePoolSize;//最大工作线程数private volatile int maximumPoolSize;//默认饱和策略执行器 - AbortPolicy -> 直接抛出异常private static final RejectedExecutionHandler defaultHandler =new AbortPolicy();
3.线程池使用
3.1 创建线程池
- 创建线程池实际上就是实例化一个线程池对象,这里我们使用最完整的构造器来描述最完整的创建过程:
-
1.corePoolSize(核心工作线程数): 无任务时,线程池允许(维护)的最小空闲线程池数;当一个任务被提交到线程池就新建一个工作线程来执行任务(即使此时有空闲的核心工作线程)直到
(实际工作线程数 >= 核心工作线程数)为止;调用prestartAllCoreThreads()方法会提前创建并启动所有核心工作线程 -
2.workQueue(任务队列): 用来保存等待执行的任务的阻塞队列;当
(实际工作线程数 >= 核心工作线程数) && (任务数 < 任务队列长度)时,任务会offer()入队等待;关于任务队列详见下文的任务队列与排队策略 -
3.maximumPoolSize(最大工作线程数): 线程池允许创建的最大工作线程数;当
(队列已满 && 实际工作线程数 < 最大工作线程数)时,线程池会创建新的工作线程(即使此时仍有空闲的工作线程)执行任务直到最大工作线程数为止;设置无界队列时该参数其实无效 -
4.keepAliveTime(工作线程最大空闲时间):单位纳秒,满足超时条件且空闲的工作线程会被回收;超时的非核心工作线程会被回收,核心工作线程不会被回收;当
allowCoreThreadTimeOut=true时,则超时的核心工作线程也会被回收;若该值没有设置则线程会永远存活;建议当场景为任务短而多时,可以调高时间以提高线程利用率 -
5.unit(线程活动保持时间单位): 线程活动保持时间单位,可选的包括
NANOSECONDS纳秒、MICROSECONDS微秒、MILLISECONDS毫秒、SECONDS秒、MINUTES分、HOURS时、DAYS天 -
6.threadFactory(线程创建工厂): 顾名思义,就是用于创建线程的工厂,允许自定义创建工厂,可以线程进行初始化配置,比如名字、守护线程、异常处理等等
-
7.handler(饱和策略执行器): 当线程池和队列都已满,此时说明线程已无力再接收更多的任务,即任务数饱和,没法接单了;此时需要使用一种饱和策略处理
新提交的任务,默认是Abort(直抛Reject异常),还包括Discard(LIFO规则丢弃)、DiscardOldest(LRU规则丢弃)以及CallerRuns(调用者线程执行),允许自定义执行器
补充:比较线程数量时不只有"="的情况的原因在于线程池允许动态控制,详情见下文
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {//注意数值条件,否则在初始化时会直接抛出IAEif (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();//任务队列、线程工厂、饱和策略执行器都不允许为空,否则在初始化是直接排除NPEif (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.acc = System.getSecurityManager() == null ?null : AccessController.getContext();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;}
3.2 提交和执行任务
- 您可以根据是否需要返回值选择二者其一:
-
- 1. execute():适用于提交无须返回值的任务
-
-该方法是无法判断任务是否被线程池执行成功
-
- 2. submit(): 适用于提交需要返回值的任务
-
-可以通过返回的
Future对象得知任务是否已经执行成功 -
-
get()方法会阻塞当前线程直到任务完成,但要注意防范无限阻塞!!! -
-使用
get(long timeout,TimeUnit unit)方法会阻塞当前线程直到任务完成或超时,不会有无限阻塞的发生但需要注意超时后任务可能还没完成!!!
3.3 关闭线程池
- 您可以选择下述二者其中去关闭线程池,笔者推荐使用更安全的第一个:
-
1. shutdown(): 有序地关闭线程池,已提交的任务会被执行(包含正在执行和任务队列中的),但会拒绝新任务
-
2. shutdownNow(): 立即(尝试)停止执行所有任务(包含正在执行和任务队列中的),并返回待执行任务列表
注意:上述方法都可以通过调用awaitTermination()等待任务完成后才终止线程池
3.4 合理配置线程池
推荐您阅读 合理配置线程池 ,有机会的话笔者会日后分享实战经验
线程池的大小建议根据具体的业务压测结果决定,或者根据利特尔法则估算
利特尔法则,英文名:Little's law(Little's result, theorem, lemma or formula),在一个稳定的系统中,长时间观察到的平均顾客数量L,等于,长时间观察到的有效到达速率λ与平均每个顾客在系统中花费的时间之乘积,即L = λW。(摘自百度)
当然现实永远是残酷的,比如网络异常、IO超时等等可能造成耗时时间的不稳定;同时在线程池的使用过程中可能会出现各种奇葩问题,因此还需要考虑任务超时处理、失败处理、隔离处理等等,尤其是大量的错误出现的情况,比如异常洪流、高并发洪流等等
推荐您阅读 ExecutorService-10个要诀和技巧
预告:笔者会新开并发番@Future一文通中进一步介绍带有返回值的线程池操作,到时会详细介绍AbstractExecutorService,因此本篇不会涉及太多知识;同时在并发番@Future一文通中,笔者同样会进一步介绍多样化的线程池配置使用以及Tomcat的线程池配置,敬请期待
4.线程池实现原理
4.1 流程图
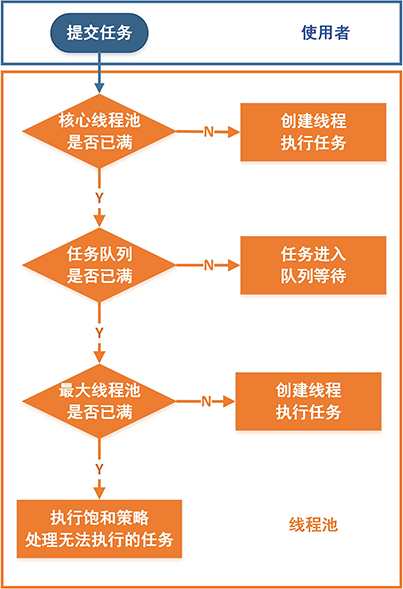
4.2 执行情况
- 随着任务数增加,线程池的执行情况主要有如下四种情况,分别对应处理流程中的各项判断:
-
1.若实际工作线程数
workers<核心工作线程数corePoolSize,则创建新工作线程来执行新任务execute(Runable) -
2.若实际工作线程数
workers>=核心工作线程数corePoolSize(核心工作线程们都在执行任务)且任务队列workQueue未满,则将任务加入到任务队列workQueue中 -
3.若任务队列
workQueue已满,则创建新工作线程来执行任务execute() -
4.若实际工作线程数
workers>=最大工作线程数maximumPoolSize(所有线程都在执行任务),此时任务数已饱和,需要根据饱和拒绝策略rejectedExecutionHandler执行相对应的饱和拒绝操作 - 线程池的总体设计是基于性能考虑,尽可能避免获取全局锁:
-
1.由于创建新线程时都需要获取全局锁,因此
步骤1和步骤3必须加锁 -
2.为了避免多次获取全局锁(性能伸缩瓶颈),当
实际工作线程数>=核心工作线程数时,之后会执行步骤2(入队时无须获取全局锁)
注意:千万不要被reject迷惑,它仅仅指的是线程池没有多余工作线程执行和多余的队列空间存储该任务,并不意味着任务就真的不处理,如何处理该任务取决于饱和拒绝策略
4.3 超时处理
- 若您需要处理超时的核心工作线程,选第二种;若不需要,选第一种:
-
1.若实际工作线程数
workers>核心工作线程数corePoolSize,回收空闲时间超过keepAliveTime的空闲的非核心线程(减少工作线程数直到<=核心工作线程数即可) -
2.若设置
allowCoreThreadTimeOut为true时,则超过keepAliveTime的空闲的核心工作线程也会被回收
4.4 线程池状态
4.4.1 状态控制器
//线程池状态控制器,用于保证线程池状态和工作线程数 ps:低29位为工作线程数量,高3位为线程池状态private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));//设定偏移量 Integer.SIZE = 32 -> 即COUNT_BITS = 29private static final int COUNT_BITS = Integer.SIZE - 3;//确定最大的容量2^29-1private static final int CAPACITY = (1 << COUNT_BITS) - 1;//获取线程池状态,取高3位private static int runStateOf(int c) { return c & ~CAPACITY; }//获取工作线程数量,取低29位private static int workerCountOf(int c) { return c & CAPACITY; }/*** 获取线程池状态控制器* @param rs 表示runState 线程池状态* @param wc 表示workerCount 工作线程数量*/private static int ctlOf(int rs, int wc) { return rs | wc; }
- 这里补充一点二进制运算符基础知识方便忘却的读者理解一下:
-
&:与运算符,同位都为1才为1,否则为0
-
|:或运算符,同位有一个为1即为1,否则为0
-
~:非运算符,0和1互换,即若是0变成1,1则变成0
-
^:异或运算符,同位相同则为0,不同则为1
4.4.2 线程池状态
- 线程状态的流转遵循如下顺序,即由小到大顺序排列:
-
RUNNING -> SHUTDOWN -> STOP -> TIDYING -> TERMINATED
补充:数值的变迁感觉就好比我们的年龄,越大离上帝就越近
// runState is stored in the high-order bits 用Integer的高三位表示//高3位111,低29位为0 该状态下线程池会接收新提交任务和执行队列任务private static final int RUNNING = -1 << COUNT_BITS;//高3位000,低29位为0 该状态下线程池不再接收新任务,但还会继续执行队列任务private static final int SHUTDOWN = 0 << COUNT_BITS;//高3位001,低29位为0 该状态下线程池不再接收新任务,不会再执行队列任务,并会中断正在执行中的任务private static final int STOP = 1 << COUNT_BITS;//高3位010,低29位为0 该状态下线程池的所有任务都被终止,工作线程数为0,期间会调用钩子方法terminated()private static final int TIDYING = 2 << COUNT_BITS;//高3位011,低29位为0 该状态下表明线程池terminated()方法已经调用完成private static final int TERMINATED = 3 << COUNT_BITS;
4.5 Worker
Worker是线程池的内部类,用于封装工作线程和任务并管理工作线程的中断状态等功能
4.5.1 组成
- Worker类封装了 ( 锁 + 线程 + 任务 ) 这三个部分,从而成为了一个多面手的存在:
-
1.继承AQS类: 实现简单的不可重入互斥锁,以提供便捷的锁操作,目的用于处理中断情况
-
2.实现Runnable接口: "投机取巧"的设计,主要是借用
Runnable接口的统一写法,好处是不用重新写一个同功能接口 -
3.工作线程: Worker会通过
thread变量绑定一个真正执行任务的工作线程(一对一),初始化时就由线程工厂分配好,它会反复地获取和执行任务 -
4.任务: Worker每次都会将新任务赋值给
firstTask变量,工作线程每次通过该变量处理新获取到的任务(初始化时该值允许为null,有特殊作用,下文会详述)
补充:由于工作线程和worker实例是一对一的关系,因为可以简单的理解工作线程等价于worker,尤其是谈及数量时,比如创建工作线程实际上就是创建一个worker,这点需要您理解,为了描述方便,笔者文中会暗藏这层关系
private final class Workerextends AbstractQueuedSynchronizerimplements Runnable{/** 实际上真正的工作线程 - 幕后大佬,但可能因线程工厂创建失败而为null */final Thread thread;/** 待执行任务,可能为null */Runnable firstTask;/** 该工作线程已完成的任务数 -- 论KPI的重要性 */volatile long completedTasks;Worker(Runnable firstTask) {//设置锁状态为-1,目的是为了阻止在runWorker()之前被中断setState(-1);/*** 新任务,任务来源有两个:* 1.调用addWorker()方法新建线程时传入的第一个任务* 2.调用runWorker()方法时内部循环调用getTask() -- 这就是线程复用的具现*/this.firstTask = firstTask;/*** 创建一个新的线程 -> 这个是真正的工作线程* 注意Worker本身就是个Runnable对象* 因此newThread(this)中的this也是个Runnable对象*/this.thread = getThreadFactory().newThread(this);}}
4.5.2 执行任务
@FunctionalInterfacepublic interface Runnable {public abstract void run();}
/*** 工作线程运行* runWorker方法内部会通过轮询的方式* 不停地获取任务和执行任务直到线程被回收*/public void run() {runWorker(this);}
- (重点)这里简单介绍一下线程在线程池执行任务的工作流程:
-
1.工作线程开始执行前,需先对worker加锁,任务完成解锁
-
2.任务执行前后分别执行
beforeExecute()和afterExecute()方法 -
3.执行中遇到异常会向外抛出,线程是否死亡取决于您对于异常的处理
-
4.每个任务执行完后,当前工作线程任务完成数自增,同时会循环调用getTask()从任务队列中反复获取任务并执行,无任务可执行时线程会阻塞在该方法上
-
5.当工作线程因各种理由退出时,会执行
processWorkerExit()回收线程(核心是将该worker从workers集合中移除,注意之前worker已经退出任务循环,因此已经不再做工了,从集合移除后就方便gc了)
4.5.3 锁方法
// Lock methods// The value 0 represents the unlocked state. 0表示未锁定// The value 1 represents the locked state. 1表示已锁定protected boolean isHeldExclusively() {return getState() != 0;}protected boolean tryAcquire(int unused) {//锁状态非0即1,即不可重入//特殊情况:只有初始化时才为-1,目的是防止线程初始化阶段被中断if (compareAndSetState(0, 1)) {//当前线程占有锁setExclusiveOwnerThread(Thread.currentThread());return true;}return false;}protected boolean tryRelease(int unused) {//释放锁setExclusiveOwnerThread(null);//状态恢复成未锁定状态setState(0);return true;}public void lock() { acquire(1); }public boolean tryLock() { return tryAcquire(1); }public void unlock() { release(1); }public boolean isLocked() { return isHeldExclusively(); }void interruptIfStarted() {Thread t;if (getState() >= 0 && (t = thread) != null&& !t.isInterrupted()){try {t.interrupt();} catch (SecurityException ignore) {}}}
小问:为什么不直接执行提交的command而必须使用Worker封装?
友情小提示:这跟worker的作用有关系
小答:主要是为了控制中断
小问:如何控制中断?
友情小提示:Worker继承了AQS从而是一把AQS锁
- 小答:Worker对于中断处理有如下四个准则:
-
1.当工作线程真正开始执行之前,不允许被中断
-
2.当工作线程正在执行任务时,不允许被中断
-
3.当工作线程正等待从任务队列中获取任务
getTask()时才能被中断 -
4.调用
interruptIdleWorkers()中断空闲线程时必须先获得worker锁
小问:为什么Worker不被设计成可重入锁?
友情小提示:禁止在动态控制时再次获取锁
小答:由于在动态控制方法中可能会中断线程,比如调用interruptIdleWorkers(),由此该方法在执行interrupt()之前会调用worker.tryLock(),若此时允许重入,就会导致线程被意外中断,这跟当工作线程正在执行任务时,不允许被中断准则是相违背的
4.6 动态控制
线程池提供了几个公共方法用于动态控制线程池的配置信息:
/*** 设置核心工作线程数* 1.若新值<当前值时,将调用interruptIdleWorkers()处理超出部分线程* 2.若新值>当前值时,新创建的线程(若有必要)直接会处理队列中的任务*/public void setCorePoolSize(int corePoolSize)/*** 设置是否响应核心工作线程超时处理* 1.设置false时,核心工作线程不会因为任务数不足(空闲)而被终止* 2.设置true时,核心工作线程和非核心工作线程待遇一样,会因为超时而终止* 注意:为了禁止出现持续性的线程替换,当设置true时,超时时间必须>0* 注意:该方法通常应在线程池被使用之前调用*/public void allowCoreThreadTimeOut(boolean value)/*** 设置最大工作线程数* 1.若新值<当前值时,将调用interruptIdleWorkers()处理超出部分线程* 注意:当新值>当前值时是无需做任何处理的,跟设置核心工作线程数不一样*/public void setMaximumPoolSize(int maximumPoolSize)/*** 设置超时时间,超时后工作线程将被终止* 注意:若实际工作线程数只剩一个,除非线程池被终止,否则无须响应超时*/public void setKeepAliveTime(long time, TimeUnit unit)
5.任务提交与执行
5.1 execute() - 提交任务
/*** 在未来的某个时刻执行给定的任务* 这个任务由一个新线程执行,或者用一个线程池中已经存在的线程执行* 如果任务无法被提交执行,要么是因为这个Executor已经被shutdown关闭* 要么是已经达到其容量上限,任务会被当前的RejectedExecutionHandler处理*/public void execute(Runnable command) {//新任务不允许为空,空则抛出NPEif (command == null)throw new NullPointerException();/*** 1.若实际工作线程数 < 核心工作线程数,会尝试创建一个工作线程去执行该* 任务,即该command会作为该线程的第一个任务,即第一个firstTask** 2.若任务入队成功,仍需要执行双重校验,原因有两点:* - 第一个是去确认是否需要新建一个工作线程,因为可能存在* 在上次检查后已经死亡died的工作线程* - 第二个是可能在进入该方法后线程池被关闭了,* 比如执行shutdown()* 因此需要再次检查state状态,并分别处理以上两种情况:* - 若线程池中已无可用工作线程了,则需要新建一个工作线程* - 若线程池已被关闭,则需要回滚入队列(若有必要)** 3.若任务入队失败(比如队列已满),则需要新建一个工作线程;* 若新建线程失败,说明线程池已停止或者已饱和,必须执行拒绝策略*/int c = ctl.get();/*** 情况一:当实际工作线程数 < 核心工作线程数时* 执行方案:会创建一个新的工作线程去执行该任务* 注意:此时即使有其他空闲的工作线程也还是会新增工作线程,* 直到达到核心工作线程数为止*/if (workerCountOf(c) < corePoolSize) {/*** 新增工作线程,true表示要对比的是核心工作线程数* 一旦新增成功就开始执行当前任务* 期间也会通过自旋获取队列任务进行执行*/if (addWorker(command, true))return;/*** 需要重新获取控制器状态,说明新增线程失败* 线程失败的原因可能有两种:* - 1.线程池已被关闭,非RUNNING状态的线程池是不允许接收新任务的* - 2.并发时,假如都通过了workerCountOf(c) < corePoolSize校验,但其他线程* 可能会在addWorker先创建出线程,导致workerCountOf(c) >= corePoolSize,* 即实际工作线程数 >= 核心工作线程数,此时需要进入情况二*/c = ctl.get();}/*** 情况二:当实际工作线程数>=核心线程数时,新提交任务需要入队* 执行方案:一旦入队成功,仍需要处理线程池状态突变和工作线程死亡的情况*/if (isRunning(c) && workQueue.offer(command)) {//双重校验int recheck = ctl.get();/*** recheck的目的是为了防止线程池状态的突变 - 即被关闭* 一旦线程池非RUNNING状态时,除了从队列中移除该任务(回滚)外* 还需要执行任务拒绝策略处理新提交的任务*/if (!isRunning(recheck) && remove(command))//执行任务拒绝策略reject(command);/*** 若线程池还是RUNNING状态 或 队列移除失败(可能正好被一个工作线程拿到处理了)* 此时需要确保至少有一个工作线程还可以干活* 补充一句:之所有无须与核心工作线程数或最大线程数相比,而只是比较0的原因是* 只要保证有一个工作线程可以干活就行,它会自动去获取任务*/else if (workerCountOf(recheck) == 0)/*** 若工作线程都已死亡,需要新增一个工作线程去干活* 死亡原因可能是线程超时或者异常等等复杂情况** 第一个参数为null指的是传入一个空任务,* 目的是创建一个新工作线程去处理队列中的剩余任务* 第二个参数为false目的是提示可以扩容到最大工作线程数*/addWorker(null, false);}/*** 情况三:一旦线程池被关闭 或者 新任务入队失败(队列已满)* 执行方案:会尝试创建一个新的工作线程,并允许扩容到最大工作线程数* 注意:一旦创建失败,比如超过最大工作线程数,需要执行任务拒绝策略*/else if (!addWorker(command, false))//执行任务拒绝策略reject(command);}
5.2 addWorker() - 新增工作线程
/*** 新增工作线程需要遵守线程池控制状态规定和边界限制** @param core core为true时允许扩容到核心工作线程数,否则为最大工作线程数* @return 新增成功返回true,失败返回false*/private boolean addWorker(Runnable firstTask, boolean core) {//重试标签retry:/**** 外部自旋 -> 目的是确认是否能够新增工作线程* 允许新增线程的条件有两个:* 1.满足线程池状态条件 -> 条件一* 2.实际工作线程满足数量边界条件 -> 条件二* 不满足条件时会直接返回false,表示新增工作线程失败*/for (;;) {//读取原子控制量 - 包含workerCount(实际工作线程数)和runState(线程池状态)int c = ctl.get();//读取线程池状态int rs = runStateOf(c);/*** 条件一.判断是否满足线程池状态条件* 1.只有两种情况允许新增线程:* 1.1 线程池状态==RUNNING* 1.2 线程池状态==SHUTDOWN且firstTask为null同时队列非空** 2.线程池状态>=SHUTDOWN时不允许接收新任务,具体如下:* 2.1 线程池状态>SHUTDOWN,即为STOP、TIDYING、TERMINATED* 2.2 线程池状态==SHUTDOWN,但firstTask非空* 2.3 线程池状态==SHUTDOWN且firstTask为空,但队列为空* 补充:针对1.2、2.2、2.3的情况具体请参加后面的"小问答"环节*/if (rs >= SHUTDOWN &&!(rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty()))return false;/**** 内部自旋 -> 条件二.判断实际工作线程数是否满足数量边界条件* -数量边界条件满足会对尝试workerCount实现CAS自增,否则新增失败* -当CAS失败时会再次重新判断是否满足新增条件:* 1.若此期间线程池状态突变(被关闭),重新判断线程池状态条件和数量边界条件* 2.若此期间线程池状态一致,则只需重新判断数量边界条件*/for (;;) {//读取实际工作线程数int wc = workerCountOf(c);/*** 新增工作线程会因两种实际工作线程数超标情况而失败:* 1.实际工作线程数 >= 最大容量* 2.实际工作线程数 > 工作线程比较边界数(当前最大扩容数)* -若core = true,比较边界数 = 核心工作线程数* -若core = false,比较边界数 = 最大工作线程数*/if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))return false;/*** 实际工作线程计数CAS自增:* 1.一旦成功直接退出整个retry循环,表明新增条件都满足* 2.因并发竞争导致CAS更新失败的原因有三种:* 2.1 线程池刚好已新增一个工作线程* -> 计数增加,只需重新判断数量边界条件* 2.2 刚好其他工作线程运行期发生错误或因超时被回收* -> 计数减少,只需重新判断数量边界条件* 2.3 刚好线程池被关闭* -> 计数减少,工作线程被回收,* 需重新判断线程池状态条件和数量边界条件*/if (compareAndIncrementWorkerCount(c))break retry;//重新读取原子控制量 -> 原因是在此期间可能线程池被关闭了c = ctl.get();/*** 快速检测是否发生线程池状态突变* 1.若状态突变,重新判断线程池状态条件和数量边界条件* 2.若状态一致,则只需重新判断数量边界条件*/if (runStateOf(c) != rs)continue retry;}}/*** 这里是addWorker方法的一个分割线* 前面的代码的作用是决定了线程池接受还是拒绝新增工作线程* 后面的代码的作用是真正开始新增工作线程并封装成Worker接着执行后续操作* PS:虽然笔者觉得这个方法其实可以拆分成两个方法的(在break retry的位置)*///记录新增的工作线程是否开始工作boolean workerStarted = false;//记录新增的worker是否成功添加到workers集合中boolean workerAdded = false;Worker w = null;try {//将新提交的任务和当前线程封装成一个Workerw = new Worker(firstTask);//获取新创建的实际工作线程final Thread t = w.thread;/*** 检测是否有可执行任务的线程,即是否成功创建了新的工作线程* 1.若存在,则选择执行任务* 2.若不存在,则需要执行addWorkerFailed()方法*/if (t != null) {/*** 新增工作线程需要加全局锁* 目的是为了确保安全更新workers集合和largestPoolSize*/final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {/*** 获得全局锁后,需再次检测当前线程池状态* 原因在于预防两种非法情况:* 1.线程工厂创建线程失败* 2.在锁被获取之前,线程池就被关闭了*/int rs = runStateOf(ctl.get());/*** 只有两种情况是允许添加work进入works集合的* 也只有进入workers集合后才是真正的工作线程,并开始执行任务* 1.线程池状态为RUNNING(即rs<SHUTDOWN)* 2.线程池状态为SHUTDOWN且传入一个空任务* (理由参见:小问答之快速检测线程池状态?)*/if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {/*** 若线程处于活动状态时,说明线程已启动,需要立即抛出"线程状态非法异常"* 原因是线程是在后面才被start的,已被start的不允许再被添加到workers集合中* 换句话说该方法新增线程时,而线程是新的,本身应该是初始状态(new)* 可能出现的场景:自定义线程工厂newThread有可能会提前启动线程*/if (t.isAlive())throw new IllegalThreadStateException();//由于加锁,所以可以放心的加入集合workers.add(w);int s = workers.size();//更新最大工作线程数,由于持有锁,所以无需CASif (s > largestPoolSize)largestPoolSize = s;//确认新建的worker已被添加到workers集合中workerAdded = true;}} finally {//千万不要忘记主动解锁mainLock.unlock();}/*** 一旦新建工作线程被加入工作线程集合中,就意味着其可以开始干活了* 有心的您肯定发现在线程start之前已经释放锁了* 原因在于一旦workerAdded为true时,说明锁的目的已经达到* 根据最小化锁作用域的原则,线程执行任务无须加锁,这是种优化* 也希望您在使用锁时尽量保证锁的作用域最小化*/if (workerAdded) {/*** 启动线程,开始干活啦* 若您看过笔者的"并发番@Thread一文通"肯定知道start()后,* 一旦线程初始化完成便会立即调用run()方法*/t.start();//确认该工作线程开始干活了workerStarted = true;}}} finally {//若新建工作线程失败或新建工作线程后没有成功执行,需要做新增失败处理if (!workerStarted)addWorkerFailed(w);}//返回结果表明新建的工作线程是否已启动执行return workerStarted;}
小问:快速检测线程状态时,情况1.2、2.1、2.3的意义是什么?
友情小提示:读者可以反问自己 -> 何时新增Worker才是有意义的呢?传入一个空任务的目的是什么?
- 小答:在阐明这个问题之前,我们先明确两个知识点:
-
1.新增Worker的目的是处理任务,任务来源分初始任务和队列任务(即剩余的待处理任务)
-
2.线程池在非RUNNING状态下是不允许接收新任务的,换句话说您都要下班了,难道还想接新需求?
- 针对2.1 - > 线程池状态==SHUTDOWN,但firstTask!= null,不允许新增Worker
-
- 当线程池状态为SHUTDOWN时,由于不允许接收新任务,因此一旦firstTask!= null需要直接拒绝
- 针对2.2 - > 线程池状态==SHUTDOWN且firstTask == null,但队列为空,不允许新增Worker
-
- 当firstTask为null时,说明调用addWorker()目的不是为了处理新增任务
-
- 那么其目的应该是为了处理剩余任务,即队列中的任务,而一旦队列为空,那也没必要新增Worker了
- 针对1.2 - > 若线程池状态==SHUTDOWN,必须满足firstTask为null且队列非空,才允许新增Worker
-
- 当线程池状态为SHUTDOWN时(调用shutdown()),此时不允许接收新任务,因此firstTask必须为null
-
- 但需要处理剩余任务,因此队列必须非空,否则新增的工作线程就无任务可做,那就没意义了
结论:传入一个空任务的目的是为了新增工作线程去处理任务队列中的剩余任务
小问:线程是如何真正开始工作的,即何时开始执行runWorker()?
友情小提示:结合Thread和Worker的构造器考虑一下
小答:作者在线程执行任务这块使用了一些"投机取巧"(很巧妙)的写法,我们分析一下Worker类即可
private final class Workerextends AbstractQueuedSynchronizer//步骤1:实现Runnable接口,从而自身是个Runnable,可以调用run方法implements Runnable{Worker(Runnable firstTask) {setState(-1);this.firstTask = firstTask;//步骤2:newThread()的参数传入的是this,即Worker本身,注意Worker是Runnablethis.thread = getThreadFactory().newThread(this);}/*** 步骤3:调用run()最终执行runWorker()* - 在addWorker()中会使用 worker.thread.start()启动线程* - thread启动后会立即调用run()方法,这就意味着启动调用会经历这样的过程:* worker = new Worker(Runnable) - > thread = newThread(worker) -> thread.start() ->* thread.run()[JVM自动调用] -> worker.run() -> threadPoolExecuter.runWorker(worker)*/public void run() {runWorker(this);}}
- 结论之启动调用会经历一下过程:
-
(1) worker = new Worker(Runnable) --> (2) thread = newThread(worker) --> (3) thread.start() --> (4) thread.run()[JVM自动调用] --> (5) worker.run() --> (6) threadPoolExecuter.runWorker(worker)
5.3 runWorker() - 执行任务
final void runWorker(Worker w) {//读取当前线程 -即调用execute()方法的线程(一般是主线程)Thread wt = Thread.currentThread();//读取待执行任务Runnable task = w.firstTask;//清空任务 -> 目的是用来接收下一个任务w.firstTask = null;/*** 注意Worker本身也是一把不可重入的互斥锁!* 由于Worker初始化时state=-1,因此此处的解锁的目的是:* 将state-1变成0,因为只有state>=0时才允许中断;* 同时也侧面说明在worker调用runWorker()之前是不允许被中断的,* 即运行前不允许被中断*/w.unlock();//记录是否因异常/错误突然完成,默认有异常/错误发生boolean completedAbruptly = true;try {/*** 获取任务并执行任务,取任务分两种情况:* 1.初始任务:Worker被初始化时赋予的第一个任务(firstTask)* 2.队列任务:当firstTask任务执行好后,线程不会被回收,而是之后自动自旋从任务队列中取任务(getTask)* 此时即体现了线程的复用*/while (task != null || (task = getTask()) != null) {/*** Worker加锁的目的是为了在shutdown()时不要立即终止正在运行的worker,* 因为需要先持有锁才能终止,而不是为了处理并发情况(注意不是全局锁)* 在shutdownNow()时会立即终止worker,因为其无须持有锁就能终止* 关于关闭线程池下文会再具体详述*/w.lock();/*** 当线程池被关闭且主线程非中断状态时,需要重新中断它* 由于调用线程一般是主线程,因此这里是主线程代指调用线程*/if ((runStateAtLeast(ctl.get(), STOP) ||(Thread.interrupted() &&runStateAtLeast(ctl.get(), STOP))) &&!wt.isInterrupted())wt.interrupt();try {/*** 每个任务执行前都会调用"前置方法",* 在"前置方法"可能会抛出异常,* 结果是退出循环且completedAbruptly=true,* 从而线程死亡,任务未执行(并被丢弃)*/beforeExecute(wt, task);Throwable thrown = null;try {//执行任务task.run();} catch (RuntimeException x) {thrown = x; throw x;} catch (Error x) {thrown = x; throw x;} catch (Throwable x) {thrown = x; throw new Error(x);} finally {/*** 任务执行结束后,会调用"后置方法"* 该方法也可能抛异常从而导致线程死亡* 但值得注意的是任务已经执行完毕*/afterExecute(task, thrown);}} finally {//清空任务 help gctask = null;//无论成功失败任务数都要+1,由于持有锁所以无须CASw.completedTasks++;//必须要主动释放锁w.unlock();}}//无异常时需要清除异常状态completedAbruptly = false;} finally {/*** 工作线程退出循环的原因有两个:* 1.因意外的错误/异常退出* 2.getTask()返回空 -> 原因有四种,下文会详述* 工作线程退出循环后,需要执行相对应的回收处理*/processWorkerExit(w, completedAbruptly);}}
小问:为什么新任务不直接放入任务队列而是被新线程执行呢?
小提示:主要是为了减少不必要的开销,从而提供性能
小答:新任务不直接放入任务队列目的是减少任务队列的入队和出队操作,因为任务队列本身是阻塞队列,因此其入队和出队操作会涉及锁操作以及并发处理
5.4 getTask() - 获取任务
- 造成getTask()方法返回null的原因有5种:
-
1.线程池被关闭,状态为(STOP || TIDYING || TERMINATED)
-
2.线程池被关闭,状态为SHUTDOWN且任务队列为空
-
3.实际工作线程数超过最大工作线程数
-
- 4.工作线程满足超时条件后,同时符合下述的任意一种情况:
-
4.1 线程池中还存在至少一个其他可用的工作线程
-
4.2 线程池中已没有其他可用的工作线程但任务队列为空
private Runnable getTask() {// 记录任务队列的poll()是否超时,默认未超时boolean timedOut = false;//自旋获取任务for (;;) {/*** 线程池会依次判断五种情况,满足任意一种就返回null:* 1.线程池被关闭,状态为(STOP || TIDYING || TERMINATED)* 2.线程池被关闭,状态为SHUTDOWN且任务队列为空* 3.实际工作线程数超过最大工作线程数* 4.工作线程满足超时条件后,同时符合下述的任意一种情况:* 4.1 线程池中还存在至少一个其他可用的工作线程* 4.2 线程池中已没有其他可用的工作线程但任务队列为空*/int c = ctl.get();int rs = runStateOf(c);/*** 判断线程池状态条件,有两种情况直接返回null* 1.线程池状态大于SHUTDOWN(STOP||TIDYING||TERMINATED),说明不允许再执行任务* - 因为>=STOP以上状态时不允许接收新任务同时会中断正在执行中的任务,任务队列的任务也不执行了** 2.线程池状态为SHUTDOWN且任务队列为空,说明已经无任务可执行* - 因为SHUTDOWN时还需要执行任务队列的剩余任务,只有当无任务才可退出*/if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {/*** 减少一个工作线程数* 值得注意的是工作线程的回收是放在processWorkerExit()中进行的* decrementWorkerCount()方法是内部不断循环执行CAS的,保证最终一定会成功* 补充:因线程池被关闭而计数减少可能与addWorker()的* 计数CAS自增发生并发竞争*/decrementWorkerCount();return null;}//读取实际工作线程数int wc = workerCountOf(c);/*** 判断是否需要处理超时:* 1.allowCoreThreadTimeOut = true 表示需要回收空闲超时的核心工作线程* 2.wc > corePoolSize 表示存在空闲超时的非核心工作线程需要回收*/boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;/*** 有三种情况会实际工作线程计数-1且直接返回null** 1.实际工作线程数超过最大线程数* 2.该工作线程满足空闲超时条件需要被回收:* 2.1 当线程池中还存在至少一个其他可用的工作线程* 2.2 线程池中已没有其他可用的工作线程但任务队列为空** 结合2.1和2.2我们可以推导出:** 1.当任务队列非空时,线程池至少需要维护一个可用的工作线程,* 因此此时即使该工作线程超时也不会被回收掉而是继续获取任务** 2.当实际工作线程数超标或获取任务超时时,线程池会因为* 一直没有新任务可执行,而逐渐减少线程直到核心线程数为止;* 若设置allowCoreThreadTimeOut为true,则减少到1为止;** 提示:由于wc > maximumPoolSize时必定wc > 1,因此无须比较* (wc > maximumPoolSize && workQueue.isEmpty()) 这种情况*/if ((wc > maximumPoolSize || (timed && timedOut))&& (wc > 1 || workQueue.isEmpty())) {/*** CAS失败的原因还是出现并发竞争,具体参考上文* 当CAS失败后,说明实际工作线程数已经发生变化,* 必须重新判断实际工作线程数和超时情况* 因此需要countinue*/if (compareAndDecrementWorkerCount(c))return null;/***/continue;}//若满足获取任务条件,根据是否需要超时获取会调用不同方法try {/*** 从任务队列中取任务分两种:* 1.timed=true 表明需要处理超时情况* -> 调用poll(),超过keepAliveTime返回null* 2.timed=fasle 表明无须处理超时情况* -> 调用take(),无任务则挂起等待*/Runnable r = timed ?workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :workQueue.take();//一旦获取到任务就返回该任务并退出循环if (r != null)return r;//当任务为空时说明poll超时timedOut = true;/*** 关于中断异常获取简单讲一些超出本章范畴的内容* take()和poll(long timeout, TimeUnit unit)都会throws InterruptedException* 原因在LockSupport.park(this)不会抛出异常但会响应中断;* 但ConditionObject的await()会通过reportInterruptAfterWait()响应中断* 具体内容笔者会在阻塞队列相关番中进一步介绍*/} catch (InterruptedException retry) {/*** 一旦该工作线程被中断,需要清除超时标记* 这表明当工作线程在获取队列任务时被中断,* 若您不对中断异常做任务处理,线程池就默认* 您希望线程继续执行,这样就会重置之前的超时标记*/timedOut = false;}}}
小问:为什么当任务为空时说明poll超时?
友情小提示:可以联想一下阻塞队列操作接口
小答:针对这个问题,我们只需看下图即可,原因在于take是阻塞操作
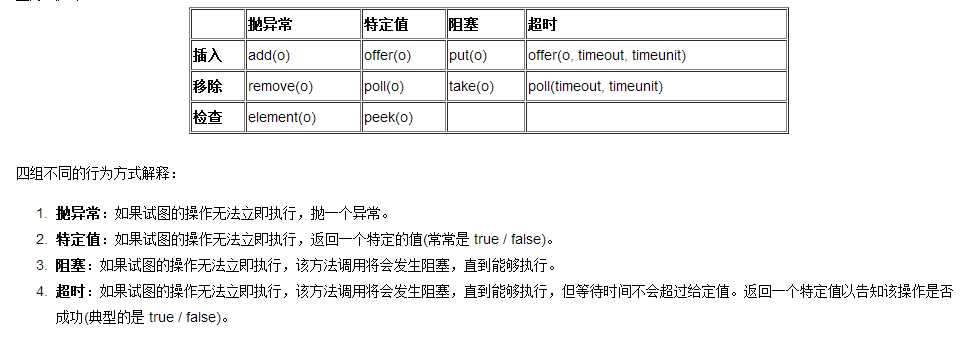
补充:笔者是这么记得"AR抛","OP布超","PT阻"... 您随意
6.关闭线程池
- 关闭线程池主要有两种方式,两者的区别是:
-
shutdown() : 队列剩余任务全部执行完毕再终止
-
shutdownNow() : 放弃执行队列剩余任务,但会将它们返回
- 两者的共性在于:
-
1.正在执行中的任务会继续执行,不会被终止或放弃
-
2.新提交的任务会被直接拒绝
6.1 shutdown() - 有序关闭
- 使用shutdown()关闭线程池最主要执行5个操作:
-
1.获取全局锁
-
2.CAS自旋变更线程池状态为SHUTDOWN
-
3.中断所有空闲工作线程(设置中断标记) -> 注意是空闲
-
4.释放全局锁
-
5.尝试终止线程池
/*** 有序关闭线程池* 在关闭过程中,之前已提交的任务将被执行(包括正在和队列中的),* 但新提交的任务会被拒绝* 如果线程池已经被关闭,调用该方法不会有任何附加效果*/public void shutdown() {//1.获取全局锁final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {checkShutdownAccess();//2.CAS自旋变更线程池状态为SHUTDOWNadvanceRunState(SHUTDOWN);//3.中断所有空闲工作线程interruptIdleWorkers();//专门提供给ScheduledThreadPoolExecutor的钩子方法onShutdown();} finally {//4.释放全局锁mainLock.unlock();}/*** 5.尝试终止线程池,此时线程池满足两个条件:* 1.线程池状态为SHUTDOWN* 2.所有空闲工作线程已被中断*/tryTerminate();}
6.2 shutdownNow() - 立即关闭
- 使用shutdownNow()关闭线程池最主要执行六个操作:
-
1.获取全局锁
-
2.CAS自旋变更线程池状态为SHUTDOWN
-
3.中断所有工作线程(设置中断标记)
-
4.将剩余任务重新放入一个list中并清空任务队列
-
5.释放全局锁
-
6.尝试终止线程池
/*** 尝试中断所有工作线程,并返回待处理任务列表集合(从任务队列中移除)** 1.若想等待执行中的线程完成任务,可使用awaitTermination()* 2.由于取消任务操作是通过Thread#interrupt实现,因此* 响应中断失败的任务可能永远都不会被终止(谨慎使用!!!)* 响应中断失败指的是您选择捕获但不处理该中断异常*/public List<Runnable> shutdownNow() {List<Runnable> tasks;//1.获取全局锁final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {checkShutdownAccess();//2.CAS自旋更新线程池状态为STOPadvanceRunState(STOP);//3.中断所有工作线程interruptWorkers();//4.将剩余任务重新放入一个list中并清空任务队列tasks = drainQueue();} finally {//5.释放全局锁mainLock.unlock();}/*** 6.尝试终止线程池,此时线程池满足两个条件:* 1.线程池状态为STOP* 2.任务队列为空* 注意:此时不一定所有工作线程都被中断回收,详述见* 7.3 tryTerminate*/tryTerminate();//5.返回待处理任务列表集合return tasks;}
6.3 awaitTermination() - 等待线程池终止
- 当关闭线程池时,awaitTermination()会一直阻塞直到下述任一种情况的出现:
-
1.所有任务执行完毕: 线程池只有在调用
tryTerminated()尝试终止线程池并成功将状态变更为TERMINATED后才会调用termination.signalAll(),此后阻塞线程被唤醒后会再次判断状态,一旦满足TERMINATED就会退出 -
2.到达阻塞超时时间:
termination.awaitNanos()在到达超时间后便会返回剩余时间(此时为0),随后会因再次判断满足nano==0导致return false,即等待失败 -
3.当前线程被中断: 若当前线程(主线程)被中断,线程会抛出
InterruptException中断异常,若不做异常处理就会因异常而解除阻塞
public boolean awaitTermination(long timeout, TimeUnit unit)throws InterruptedException {long nanos = unit.toNanos(timeout);final ReentrantLock mainLock = this.mainLock;//1.获取全局锁mainLock.lock();try {for (;;) {//2.所有任务执行完毕,等待成功而退出if (runStateAtLeast(ctl.get(), TERMINATED))return true;//3.到达阻塞超时时间,等待失败而退出if (nanos <= 0)return false;nanos = termination.awaitNanos(nanos);}} finally {//4.释放全局锁mainLock.unlock();}}
您可以通过以下方式得知线程池是否真正被关闭:
//关闭线程池threadPoolExecutor.shutdown();try{//循环调用等待任务最终全部完成while(!threadPoolExecutor.awaitTermination(300, TimeUnit.MILLISECONDS)) {logger.info("task executing...");}//此时剩余任务全部执行完毕,开始执行终止流程logger.info("shutdown completed!")} catch (InterruptedException e) {//中断处理}
7.中断和终止处理
7.1 interruptIdleWorkers() - 中断空闲线程
- Worker对于中断处理有如下四个准则(前面的知识我们再回顾一遍):
-
1.当工作线程真正开始执行之前,不允许被中断
-
2.当工作线程正在执行任务时,不允许被中断
-
3.当工作线程正等待从任务队列中获取任务
getTask()时才能被中断 -
4.调用
interruptIdleWorkers()中断空闲线程时必须先获得worker锁
/*** 中断全部空闲线程*/private void interruptIdleWorkers() {interruptIdleWorkers(false);}/*** 中断未上锁且在等待任务的空闲线程* 中断的作用在于便于处理终止线程池或动态控制的情况** @param onlyOne 为true时为中断一个,为false时为中断全部*/private void interruptIdleWorkers(boolean onlyOne) {//加全局锁final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {/*** 循环方式中断工作线程* 这里也体现了workers集合的核心作用之一*/for (Worker w : workers) {Thread t = w.thread;/*** 非中断且成功获取到worker锁的工作线程才允许被中断** 1.已被中断的工作线程无须再次标记中断** 2.w.tryLock()体现了Worker作为一把锁的核心作用:* 即控制线程中断 -> 当线程还在运行中是不允许被中断的** 3.具体可以参见runWorker()方法,运行前都是调用lock()** 4.由于该方法只会在shutdown()中调用,间接也说明* shutdown()只会中断在该方法中获取到worker锁* 的空闲线程(此时线程正在获取新任务getTask(),还没上锁)*/if (!t.isInterrupted() && w.tryLock()) {try {//中断工作线程t.interrupt();} catch (SecurityException ignore) {} finally {//注意这里释放的是worker锁,对应tryLock()w.unlock();}}//onlyOne为true时,只随机中断一个空闲线程(Set可是无序的哦)if (onlyOne)break;}} finally {//释放全局锁mainLock.unlock();}}
7.2 interruptWorkers() - 中断所有线程
/*** 中断所有线程,包括正在执行任务的线程* 该方法只提供给shutdownNow()使用*/private void interruptWorkers() {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {//循环设置中断标志for (Worker w : workers)w.interruptIfStarted();} finally {mainLock.unlock();}}/*** Worker实现的中断方法*/void interruptIfStarted() {Thread t;/*** 当线程池非RUNNING状态 && 线程非空 && 线程非中断* 三者同时满足时才允许中断** 为什么线程池必须非RUNNING状态才允许中断呢?* 因为该方法只提供给interruptWorkers()使用* 而interruptWorkers()只提供给shutdownNow()使用* 因此此时线程状态应为STOP*/if (getState() >= 0 && (t = thread) != null&& !t.isInterrupted()) {try {//设置中断标志t.interrupt();} catch (SecurityException ignore) {}}}
7.3 tryTerminate() - 尝试终止线程池
在解析tryTerminate()之前,我们先解决几个很重要的问题
小问:为什么正在执行任务的工作线程不允许被中断?
友情小提示:工作线程执行任务前需加worker锁且该锁非重入
小答:回顾interruptIdleWorkers()我们发现在(1)必须先调用tryLock()成功获取worker锁后才允许中断该工作线程,而因为(2)工作线程获取到任务后并在执行任务之前也会先加worker锁且worker锁是不可重入的,这就意味着正在执行任务的工作线程不允许被中断
小问:怎样才算是空闲工作线程?
友情小提示:需要获取worker锁有两个时机,一个是shutdown(),一个真正执行任务之前
- 小答:工作线程在执行任务时肯定是持有锁的,而只有当从任务队列获取任务getTask()时无须获得worker锁,由此可以将工作线程分成两种状态:
-
1.正在执行任务的工作线程:获得worker锁后执行task.run()的工作线程
-
2.空闲工作线程:正在从任务队列中获取任务的工作线程(包含刚好 拿到任务以及因无任务时被阻塞的工作线程)
小问:线程中断是如何影响线程回收的?
友情小提示:核心在于当getTask()返回null时会退出runWorker()并执行processWorkerExit()
小答:我们先来回顾一下geTask()返回null的情况:
- 造成getTask()方法返回null的原因有5种:
-
1.线程池被关闭,状态为(STOP || TIDYING || TERMINATED)
-
2.线程池被关闭,状态为SHUTDOWN且任务队列为空
-
3.实际工作线程数超过最大工作线程数
-
- 4.工作线程满足超时条件后,同时符合下述的任意一种情况:
-
4.1 线程池中还存在至少一个其他可用的工作线程
-
4.2 线程池中已没有其他可用的工作线程但任务队列为空
由上述可知,当线程池关闭、线程超时或动态控制线程(比如池大小数、超时时间等)都可能造成getTask()返回null,那getTask()是如何影响回收的呢?
- 我们仅以关闭线程池为例(其他情况也只是条件判断不同的区别),描述一下中断后会发生的逻辑:
-
1.当阻塞在
getTask()上的工作线程被中断后会抛出InterruptedException中断异常,之后会解除阻塞重新获取任务 -
2.重新获取任务仍需重新校验任务获取条件,当线程池关闭时,比如调用
shutdown(),线程池状态变为SHUTDOWN,又因为此时任务队列为空,getTask()直接返回null;若调用shutdownNow(),线程池状态变为STOP,则直接返回null -
3.在
runWorker()方法中,当getTask()返回null后,会退出循环,然后调用processWorkerExit()方法线程回收操作
值得一提的是:JAVA的中断机制只是设置中断标记,因此您在任务中自行执行Thread.currentThread().interrupt()并不会影响线程继续执行任务和线程回收,同时您无法在任务中获取InterruptedException(编译报错),原因在于已经在getTask()捕获过了
小问:既然关闭线程池后线程池状态变更且被中断后的线程会被回收,为什么还要执行tryTerminate()?
友情小提示:调用shutdown()后,interruptIdleWorkers()只会中断空闲工作线程,那么当时正在执行任务的工作线程执行完后怎么办呢?
小答:调用shutdown()后,正在执行任务的工作线程不会被中断,当它们结束任务后,假设队列非空,这些工作线程会继续执行剩余任务直到阻塞,随着任务数的减少,实际工作线程数会不断减少直到最小维护数量;当队列为空时,最小维护数的工作线程们会一直被阻塞在workerQueue.take()上面,永远无法终止了,且线程池被关闭后也不会再接收新提交的任务
- 针对中断时正在执行任务的工作线程无法被终止的问题,Doug Lea老师的解决方案是:
-
-在任何可能导致线程池终止的地方都要调用
tryTerminate(),该方法会判断线程池是否已进入终止流程,若此时还有线程存在,会重新中断一个空闲工作线程
终止流程:线程池状态为SHUTDOWN且任务队列为空,或线程池状态为STOP
/*** 终止线程池 -> 最终会将线程池状态变更为TERMINATED* 只有同时满足下面两个条件才允许做TERMINATED的状态转变:* 1.线程池状态为SHUTDOWN且任务队列为空 或状态为STOP* 2.线程池中已没有存活的工作线程 -> 实际工作线程为0*/final void tryTerminate() {//自旋for (;;) {//获取线程池控制器int c = ctl.get();/*** 有4种情况是不允许执行变更TERMINATED操作** 1.线程池仍为运行态RUNNING,说明线程池还在正常运行中,* 此时是不允许尝试中断,起码要SHUTDOWN或STOP* 规则参见shutdown()和shutdownNow()** 2.线程池状态已经是TIDYING或TERMINATED,* 前者说明变更TERMINATED正在执行中,后者说明终止已完成* 这两种情况都无须重复执行终止** 3.线程池状态为SHUTDOWN且任务队列非空,* 说明线程池虽然已被要求关闭,但还有任务还没处理完* 需要等待任务队列中剩余任务被执行完毕*/if (isRunning(c) ||runStateAtLeast(c, TIDYING) ||(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))return;/*** 此时线程池状态为SHUTDOWN状态且队列为空,或已是STOP状态* 4.若工作线程数非0,说明还有工作线程可能正在执行或等待任务中,* 这种情况的原因参见上文中的小问答之`为什么还要执行tryTerminate()`* 此时会选择中断一个空闲工作线程以确保SHUTDOWN信号的传播*/if (workerCountOf(c) != 0) { // Eligible to terminate/*** 此时已经进入终止流程,为了传播SHUTDOWN信号,* 每次总是中断一个空闲工作线程以避免所有线程等待** 小问:此时若调用interruptIdleWorkers(false)呢?* 小答:注意每个线程的回收都会调用processWorkerExit()* 而该方法都会调用tryTerminate(),而此时一旦* 设置为true(表示全部)的话,由于中断操作前必须* 通过worker.tryLock()加锁,因此就可能因锁竞争* 造成不必要的大量等待,还不如一个个执行** 小问:那么为什么shutdown()的时候可以为true呢?* 小答:那是因为空闲线程都是没有持有worker锁的!* 那么就不会出现锁竞争带来的不必要的开销*/interruptIdleWorkers(ONLY_ONE);return;}/*** 当进入终止流程且无存活的工作线程时* 那么就可以terminate终止线程池了*///1.获取全局锁final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {/*** 2.先尝试变成TIDYING状态* 1.一旦成功,执行🐶方法terminated()* 2.CAS失败后会重试,失败原因可能是线程池刚好* 已被设置为TERMINATED,即线程池终止已经完成,* 之后在重新循环中会因runStateAtLeast(c, TIDYING)* 而退出该方法*/if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {try {//3.执行终止terminated();} finally {//4.设置TERMINATED状态ctl.set(ctlOf(TERMINATED, 0));/*** 5.通过唤醒解除条件阻塞* 当关闭线程池后需要等待剩余任务完成才真正终止线程池,* 会调用awaitTermination()方法,* 此时主线程会被**/termination.signalAll();}return;}} finally {//6.释放全局锁mainLock.unlock();}// else retry on failed CAS}}
8.线程失败和回收处理
8.1 addWorkerFailed() - 新增线程失败处理
- 处理新增工作线程失败会执行如下操作:
-
1.获得全局锁
-
2.从workers集合中移除该worker
-
3.CAS自旋减少实际工作线程计数
-
4.尝试终止线程池
-
5.释放全局锁
/*** 新增工作线程失败处理*/private void addWorkerFailed(Worker w) {//1.获取全局锁 -> 目的是为了安全更新workersfinal ReentrantLock mainLock = this.mainLock;mainLock.lock();try {//2.从workers集合中移除该workerif (w != null)workers.remove(w);/*** 3.CAS自旋减少实际工作线程计数 -> 最终会成功* 小问:为何已经加锁还是使用CAS?* 小答:workers必须在持有锁环境下使用,ctl无须在持有锁环境下使用* 1.workers集合为非线程安全的HashSet,不能使用CAS只能加锁(即外部控制方式)* 2.ctl为AtomicInteger原子类型,因此可以直接使用CAS维护(即内部控制方式)* 注意:这里说的持有锁指的是持有全局锁mainLock,虽然ReentrantLock底层实现也是CAS*/decrementWorkerCount();/*** 4.尝试终止线程池** 小问:那么为什么此时要尝试终止线程池呢?* 小答:因为新增线程失败的原因只有一个* -> 线程池被关闭并进入终止流程* 具体可参见addWorker()方法*/tryTerminate();} finally {//5.释放全局锁mainLock.unlock();}}
8.2 processWorkerExit() - 线程回收处理
- 线程回收处理主要分两个部分:
-
1.回收该工作线程
-
2.根据需要新增工作线程
- 一.回收该工作线程主要有6个步骤:
-
1.因错误异常而被突然中断的线程,实际工作线程计数-1
-
2.获取全局锁
-
3.统计线程池总完成任务数
-
4.将该worker从workers集合中安全移除
-
5.释放全局锁
-
6.尝试终止线程池
- 二.若线程池状态为RUNNING或SHUTDOWN时,有两种情况需要新增工作线程:
-
1.线程因错误异常而被意外死亡
-
2.若非意外死亡,则至少保证有最小存活数个可用工作线程存活
private void processWorkerExit(Worker w, boolean completedAbruptly) {//1.因错误异常而被意外死亡的线程,实际工作线程计数-1if (completedAbruptly)// If abrupt, then workerCount wasn't adjusted 作者大佬的注释真的没写错吗....decrementWorkerCount();//2.获取全局锁,主要目的是为了安全将worker从workers集合中移除final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {//3.统计线程池总完成任务数completedTaskCount += w.completedTasks;//4.将该worker从workers集合中安全移除workers.remove(w);} finally {//5.释放全局锁mainLock.unlock();}/*** 6.尝试终止线程池* 小问:为什么此处需要尝试终止线程池?* 小答:由于processWorkerExit()方法只会在* runWorker()中调用,而调用的时机有两个:* 1.工作线程因错误异常而被中断退出* 2.getTask()返回null* 根据tryTerminate()的终止条件可知,* 前者实际上并不会终止线程池,但问题是* 后者的getTask()是有可能因进入终止流程而返回null*/tryTerminate();int c = ctl.get();/*** 若线程池状态为RUNNING或SHUTDOWN时,有两种情况需要新增工作线程* 1.线程因错误异常而被意外死亡* -> 目的是填补这个意外死亡的工作线程造成的线程缺口(填坑)* 2.若非意外死亡,则至少保证有最小存活数个可用工作线程存活* -> 目的是保证线程池正常运行或SHUTDOWN时有能力完成队列剩余任务*/if (runStateLessThan(c, STOP)) {if (!completedAbruptly) {/*** 线程最小存活数由allowCoreThreadTimeOut和队列长度共同决定* 1.当allowCoreThreadTimeOut为true时,若队列非空,* 至少保证一个可用线程存活* 2.当allowCoreThreadTimeOut为false时,实际工作线程数* 一旦超过核心工作线程数,无须再新增工作线程了*/int min = allowCoreThreadTimeOut ? 0 : corePoolSize;//1.若允许响应核心工作线程超市且队列非空时if (min == 0 && ! workQueue.isEmpty())//至少保证一个可用线程可用min = 1;//2.实际工作线程数一旦超过核心工作线程数,无须再新增线程了if (workerCountOf(c) >= min)// replacement not needed//"替换"指的是替已死亡的线程继续填坑(完成剩余任务)return;}/*** 新增工作线程根据原因区分的目的有两个:* 1.因意外死亡的:* -> 目的是为了填补线程空缺* 2.非意外死亡正常退出且队列非空:* -> 处理任务队列中的剩余任务* 虽然目的有区别,但实际上作用是一致的:* -> 都是为了处理队列任务(因为firstTask为null)*/addWorker(null, false);}}
9.任务队列与排队策略
- 任务队列是用于存储等待执行的任务的阻塞队列(在这里特指实现了
BlockingQueue接口的阻塞队列实现类),其目的是为了实现数据缓存和共享;并发包原生提供了7种阻塞队列,根据界化可分成两部分: -
-有界队列: 有界队列指的是容量有限,不允许无限拓展的队列,其最大可设置容量为
Integer.MAX_VALUE,入队和出队都可能阻塞有界队列(bounded): 必须给定出初始容量,包括
ArrayBlockingQueue可配队列(optionally-bounded): 不设置初始容量时默认最大容量为
Integer.MAX_VALUE,包括LinkedBlockingQueue和LinkedBlockingDeque
-
-无界队列:无界队列指的无边界,有两种情况分别是0和无限制
无边界(0):容量为0,不存储元素,无阻塞,如
SynchronousQueue无边界限制(unbounded): 允许容量无限拓展,直到抛出
OutOfMemoryError,入队不会阻塞,出队才可能阻塞,包括DelayQueue、LinkedTransferQueue、PriorityBlockingQueue
注意:若不特别说明,阻塞队列都遵循FIFO先进先出规则
9.1 有界队列
- 有界队列指的是容量有限且固定,不容许无限拓展的阻塞队列,相对于无界队列来说,当maximumPoolSizes有限时可以有效防止资源耗尽,但也增加了控制的难度 -> 有界队列需要队列大小和最大线程数之间相互"妥协":
-
-大型队列+小型池:有效减少线程开销但可能降低吞吐量,若任务频繁阻塞,比如频繁I/O,
使用大型队列和小型池可以最大限度地降低CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O 边界),则系统可能为超过您许可的更多线程安排时间 -
-使用小型队列通常要求较大的池大小,CPU 使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量
9.1.1 ArrayBlockingQueue
- 作用:
-
-由数组结构组成的有界阻塞队列
-
-除了定长数组外还包括两个int变量标识头部和尾部在数组中的位置
-
-入队和出队时不会产生或回收任何额外的对象
-
-支持公平和非公平模式,默认非公平锁
-
-内部采用一把锁+两个条件的同步方式,不能真正并发
9.1.2 LinkedBlockingQueue
- 作用:
-
-由链表结构组成的有界阻塞队列
-
-此队列的默认和最大长度为
Integer.MAX_VALUE -
-入队/出队时每次都会生成/销毁一个额外的Node对象,用于实现链表结构
-
-链表的吞吐通常要好于数组列表(理论上),理由自行谷歌
ArrayList和LinkedList的区别 -
-内部采用两把锁+两个条件的同步方式,真正并发
-
-
Executors.newFixedThreadPool()所用阻塞队列 - 坑点:
-
使用默认容量时,若生产速度远超过消费速度,可能在因队列满仓被阻塞之前内存资源就已经耗尽了
- 建议:
-
-通常只要使用
LinkedBlockingQueue和ArrayListBlockingQueue就可以满足大部分生产-消费需求
9.1.3 LinkedBlockingDeque
- 作用:
-
-由链表结构组成的双端阻塞队列
-
-双端队列允许从队列双端入队和出队,具体表现在多了很多xxFirst和xxLast方法
-
-当没设置初始容量时,此队列默认使用最大容量值为
Integer.MAX_VALUE -
-同
ArrayListBlockingQueue一样,内部采用一把锁+两个条件的同步方式,不能真正并发
9.2 无界队列
- 无界队列指的是容量无限大或容量为0的阻塞队列,在使用时需要注意:
-
1.当容量为0时则要慎重设置maxPoolSize以避免拒绝新提交的任务
-
2.当容量无限大时,就意味着maxPoolSize失效,设置该值无意义,创建线程数不会超过corePoolSize
- 适用场景:
- 当每个任务相互独立,相互无影响时最适合无界队列
9.2.1 SynchronousQueue
- 特点:
-
-不存储元素的阻塞队列,也是线程池默认任务队列类型
-
-队列不存储任务,只能进行线程之间的元素传送 -> 即直接提交
-
-支持公平模式和非公平模式,默认非公平(关于公平参见
reentrantLock) -
-
Executors.newCachedThreadPool()所用阻塞队列 - 场景:
-
此策略可以避免在处理可能具有内部依赖性的请求集时出现锁
- 坑点:
-
-当不存在可用于立即运行的任务时,加入队列会失败,此时会新增一个新线程;但若超过maxPoolSize时会出现拒绝新提交的任务的问题!
-
-非公共模式下若生产和消费速度差距较大,很容易出现饥饿的情况,某些数据可能永远无法执行
- 建议:
-
-直接提交通常要求无界maximumPoolSizes以避免拒绝新提交的任务
-
-当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性
9.2.2 PriorityBlockingQueue
- 特点:
-
-由数组结构组成且具有优先级的无界阻塞队列,默认容量11
-
-默认自然排序,同时支持入队元素自定义顺序(实现
Comparable接口) -
-排序算法为堆排序,内部线程同步使用公平锁
-
-内部使用一把锁+一条件的同步方式:由于是无界队列,因此只需要一个
notEmpty非空条件即可 -
-值得注意的是只有头节点才保证优先级顺序,其他节点不保障
- 场景:
- 需要排序后的数组的时候
- 坑点:
-
由于使用堆排序,因此一旦消费速度远小于生产速度时,时间一长由于任务挤压再加上堆排序需要,很可能会耗尽所有的堆空间,即很容易内存溢出
- 建议:
- 土豪随意加内存,否则需要保证任务不要积压过多
9.2.3 DelayQueue
- 特点:
-
-使用优先级队列实现有序且获取延迟的阻塞无界队列
-
-入队元素必须实现
Delayed接口,给定初识延时时间,只有到达延时时间才能从队列中获取到该元素,该元素不允许为null -
-内部使用一把锁+一条件+优先级队列的同步方式:由于延迟特性,因此只需要一个
available条件标示任务是否可用即可 - 场景:
-
-用于实现重试机制,多次延迟执行同时可支持重试次数限制
-
-
ScheduledThreadPoolExecutor延迟线程池中的DelayedWorkQueue延迟阻塞队列是其的优化版本,用于定时调度等操作 -
-用于实现缓存,虽然推荐使用NoSQL
-
-
TimerQueue的底层数据结构
9.2.4 LinkedTransferQueue
- 特点:
-
-由链表结构组成的无界阻塞队列
-
-
TransferQueue是ConcurrentLinkedQueue、SynchronousQueue (公平模式下)、无界的LinkedBlockingQueues等的超集 -
-相对于其他阻塞队列
LinkedTransferQueue多了tryTransfer()和transfer()方法 -
-当没有消费者在等待接收元素,
transfer()方法会将元素存放在队列的tail节点,阻塞直到有消费者消费该元素才返回;否则直接传递给消费者
,此时不会入队 -
-区别于
transfer(),tryTransfer()方法无论是否有消费者在等待接收元素,都会立即返回操作结果是成功或是失败,此时不会入队且非阻塞 -
- -此类使用的复杂的双重数据结构,其方法都需要通过两个步骤实现:
- 保留:当消费者从队列中获取元素时发现队列为空,此时会创建一个数据字段为null的Node节点元素放入队列,然后消费者必须阻塞(自旋等待)直到此数据字段非空
- 传递: 当生产者准备向队列存入元素时发现最前面的元素的数据字段为null,此时它会直接把该元素的数据赋值给最前面的元素,即完成数据的传递
10.线程池的监控
10.1 原生监控
- 监控线程池的运行情况是挺重要的一件事情,尤其是定位问题的时候,所幸的是线程池原生给我们提供了几个监控属性可供get:
-
1.taskCount:线程池需要执行的任务数量(近似值)
-
2.completedTaskCount:线程池在运行过程中已完成的任务数量,小于或等于taskCount
-
3.largestPoolSize:线程池里曾经创建过的最大线程数,若该值与maxPoolSize一致的话说明线程池曾经满过
-
4.poolSize:线程池中线程数量,包括不在干活的工作线程数;值得注意的是若线程池不关闭的话,线程池中的线程不会被自动回收的,因此对于运行中的线程池来说该值只增不减
-
5.activeCount:正在运行中的工作线程数(近似值)
值得一提的是这些监控属性的get方法内部虽然都是使用全局锁维护的,但由于线程池运行期间的状态和线程数可以被动态调整,比如allowCoreThreadTimeOut()、setMaximumPoolSize()、setCorePoolSize()、shutdown()等等方法,因此有些值只能近似值
10.2 拓展监控
- 线程池提供了三个钩子方法可以用于拓展功能,比如监控任务的平均执行时间、最大执行时间和最小执行时间:
- beforeExecute():位于
runWorker()方法中,在run()方法前执行 - afterExecute():位于
runWorker()方法中,在run()方法后执行 - terminated():位于
tryTerminate()方法中,状态CAS为TIDYING之后执行
注意:由于上述方法都为protected且线程池中默认都是空方法,因此只能通过继承线程池或构造时才能重写上述方法
11.饱和拒绝策略
- 线程池的饱和拒绝策略主要用于拒绝任务(但这并不意味着该任务不会被执行),线程池原生提供了四种饱和拒绝策略,基本涵盖常见的饱和处理场景:
-
AbortPolicy:默认策略,直接抛出异常
-
CallerRunsPolic:只用调用线程执行该任务
-
DiscardPolicy:直接丢弃任务
-
DiscardOldestPolicy:丢弃队尾任务并用线程池重新尝试执行该任务
所有的拒绝策略都需要实现该拒绝处理器接口,以统一口径:
/*** 用于拒绝线程池任务的处理器*/public interface RejectedExecutionHandler {/*** 该方法用于拒绝接受线程池任务** 有三种情况可能调用该方法:* 1.没有更多的工作线程可用* 2.任务队列已满* 3.关闭线程池** 当没有其他处理选择时,该方法会选择抛出RejectedExecutionException异常* 该异常会向上抛出直到execute()的调用者*/void rejectedExecution(Runnable r, ThreadPoolExecutor executor);}
11.1 CallerRunsPolicy
处理规则:新提交任务由调用者线程直接执行
推荐:拒绝策略推荐使用CallerRunsPolicy,理由是该策略不会抛弃任务,也不会抛出异常,而是将任务回退到调用者线程中执行
/*** 不会直接丢弃,而是直接用调用execute()方法的线程执行该方法* 当然一旦线程池已经被关闭,还是要丢弃的** 补充:值得注意的是所有策略类都是public的静态内部类,* 其目的应该是告知使用者 -> 该类与线程池相关但无需线程池实例便可直接使用*/public static class CallerRunsPolicy implements RejectedExecutionHandler {public CallerRunsPolicy() { }/*** 直接使用调用该方法的线程执行任务* 除非线程池被关闭时才会丢弃该任务*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {//一旦线程池被关闭,丢弃该任务if (!e.isShutdown()) {//注意此时不是线程池执行该任务r.run();}}}
11.2 AbortPolicy
处理规则:直接抛出RejectedExecutionException异常
/*** 简单、粗暴的直接抛出RejectedExecutionException异常*/public static class AbortPolicy implements RejectedExecutionHandler {public AbortPolicy() { }/*** 直接抛出异常,但r.toString()方法会告诉你哪个任务失败了* 更人性化的一点是 e.toString()方法还会告诉你:* 线程池的状态、工作线程数、队列长度、已完成任务数* 建议若是不处理异常起码也要在日志里面打印一下,留个案底*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + e.toString());}}
11.3 DiscardPolicy
处理规则:根据LIFO(后进先出)规则直接丢弃最新提交的任务
/*** 直接丢弃任务* 这个太狠了,连个案底都没有,慎用啊*/public static class DiscardPolicy implements RejectedExecutionHandler {public DiscardPolicy() { }/*** 无作为即为丢弃*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {}}
11.4 DiscardOldestPolicy
处理规则:根据LRU(最近最少使用)规则丢弃最后一个任务,然后尝试执行新提交的任务
/*** 比起直接丢弃,该类会丢弃队列里最后一个但仍未被处理的任务,* 然后会重新调用execute()方法处理当前任务* 除非线程池被关闭时才会丢弃该任务* 此类充分证明了"来得早不如来的巧"*/public static class DiscardOldestPolicy implements RejectedExecutionHandler {public DiscardOldestPolicy() { }/*** 丢弃队列里最近的一个任务,并执行当前任务* 除非线程池被关闭时才会丢弃该任务* 原因是队列是遵循先进先出FIFO原则,poll()会弹出队尾元素*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {//一旦线程池被关闭,直接丢弃if (!e.isShutdown()) {//弹出队尾元素e.getQueue().poll();//直接用线程池执行当前任务e.execute(r);}}}
12.线程池的异常处理
12.1 submit()异常处理
- 使用
submit()处理异常时有四个注意事项: -
1.异常会保存在
Future对象的ExecutionException中,可以在调用get()使用try-catch方式捕获,有N个任务有异常就会抛出来N个异常,但不会终止当前工作线程 -
2.单独设置
UncaughtExceptionHandler没卵用,但结合(3)使用就有效 -
3.允许在
submit()方法内部用try-catch捕获该异常,同样不会终止当前线程 -
4.若想在内部处理异常,还可以重写
afterExecute()方法,例如:
static ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 3, 3, TimeUnit.SECONDS, new SynchronousQueue<>()) {//构造时直接重写afterExecute()方法protected void afterExecute(Runnable r, Throwable t) {super.afterExecute(r, t);printException(r, t);}};private static void printException(Runnable r, Throwable t) {if (t == null && r instanceof Future<?>) {try {Future<?> future = (Future<?>) r;if (future.isDone())future.get();} catch (ExecutionException e) {t = e.getCause();} catch (InterruptedException e) {Thread.currentThread().interrupt();}}if (t != null) {System.out.println(t);}}
12.2 execute()异常处理
- 使用
execute()处理异常时有四个注意事项: -
1.默认会在
execute()方法内部直接抛出异常,注意这不会中断线程池运行,但会终止当前工作线程,并重新创建新的工作线程执行该任务 -
2.允许在
execute()方法内部用try-catch捕获该异常,好处是不会终止当前线程并重新创建一个新的线程了 -
3.重写
afterExecute()方法 -
4.还可以设置
UncaughtExceptionHandler,例如:
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 2, 3, TimeUnit.SECONDS, new LinkedBlockingQueue(),//我们自定义一个线程工厂和重写线程的setUncaughtExceptionHandler方法new ThreadFactory() {final AtomicInteger threadNumber = new AtomicInteger(1);public Thread newThread(Runnable r) {Thread thread = new Thread(Thread.currentThread().getThreadGroup(), r, "thread-"+ (threadNumber.getAndIncrement()));thread.setUncaughtExceptionHandler((t,e) -> System.out.println(e));return thread;}});
并发番@ThreadPoolExecutor一文通(1.8版) 由 黄志鹏kira 创作,采用 知识共享 署名-非商业性使用 4.0 国际 许可协议 进行许可。
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。
