@kiraSally
2018-03-12T10:32:49.000000Z
字数 11968
阅读 5667
集合番@HashMap一文通(1.7版)
JAVA COLLECTIONS 源码 1.7版本
- 笔者个人博客 kiraSally的掘金个人博客 感谢支持
1.HashMap的定义
- 基于哈希表的Map接口的非同步、无序实现
- 此实现提供所有可选的映射操作,并允许使用null值和null键
- 此实现假定哈希函数将元素适当分布在各桶之间,为读取操作提供稳定性能
- 迭代时间与实例容量(桶的数量)及其大小(键-值映射关系数)成正比
- 本版本为JDK1.7, 1.8版本参见笔者的 集合番@HashMap一文通(1.8版)
2.HashMap的数据结构
2.1 类定义
public class HashMap<K,V>extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable
2.2 重要全局变量
链表散列的数据结构(数组+链表【冲突解决方案-封闭寻址方法】)
备注:建议直接看英文注释,更加清晰明了//The default initial capacity - MUST be a power of two.static final int DEFAULT_INITIAL_CAPACITY = 16;//The maximum capacity - MUST be a power of two <= 1<<30.static final int MAXIMUM_CAPACITY = 1 << 30;//The load factor used when none specified in constructor.static final float DEFAULT_LOAD_FACTOR = 0.75f;//The table, resized as necessary. Length MUST Always be a power of two.transient Entry<K,V>[] table;//The number of key-value mappings contained in this map.transient int size;//The next size value at which to resize (capacity * load factor).int threshold;//The load factor for the hash table.final float loadFactor;/*** The number of times this HashMap has been structurally modified* Structural modifications are those that change the number of mappings in* the HashMap or otherwise modify its internal structure (e.g.,* rehash). This field is used to make iterators on Collection-views of* the HashMap fail-fast. (See ConcurrentModificationException).*/transient int modCount;
2.3 构造器
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " + loadFactor);// Find a power of 2 >= initialCapacityint capacity = 1;while (capacity < initialCapacity)capacity <<= 1;this.loadFactor = loadFactor;//阈值为容量*负载因子和最大容量+1之间的最小值 以此值作为容量翻倍的依据(不能超过最大容量)threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);//初始化一个2次幂的Entry类型数组 一个桶对应一个Entry对象table = new Entry[capacity];useAltHashing = sun.misc.VM.isBooted() &&(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);init();}
2.4 Entry
/*** 静态类 默认实现内部Entry接口 (接口中可定义内部接口-Map.Entry接口为Map的内部接口)* PS:JDK8中引入default,作用为在接口中定义默认方法实现*/static class Entry<K,V> implements Map.Entry<K,V> {final K key;//key具有引用不可变特性V value;Entry<K,V> next;//next指向下一个:单向链表,头插入final int hash;……}
3.HashMap的重要方法
3.1 put方法
- HashMap允许存放null的key和null的value,其存储过程如下:
-
1.当key==null时,若存在该entry则覆盖value,否则新增key为null的entry
-
2.根据hash计算该entry所在桶的位置 -> 即数组下标index
-
3.遍历链表,若该key存在则更新value,否则新增entry (有则更新,无则新增)
/*** 存放键值对* 允许存放null的key和null的value* @return key不存在返回null,否则返回旧值*/public V put(K key, V value) {/*** 1.针对key为null的处理有两种方式:* 1.1从tab[0]开始向后遍历,若存在key为null的entry,则覆盖其的value* 1.2遍历完成但仍不存在key为null的entry,则新增key为null的entry* 准则:一个HashMap只允许有一个key为null的键值对* 注意:由于hash(null) = 0,因此key=null的键值对永远在tab[0]*/if (key == null)return putForNullKey(value);/*** 根据key的hashCode并结合hash()算法计算出新的hash值* 目的是为了增强hash混淆 -> 因为key.hashCode()很可能不太靠谱* 而HashMap是极度依赖hash来实现元素离散的,通俗来说就是* 尽可能的让键值对可以分到不同的桶中以便快速索引*/int hash = hash(key);//2.根据hash计算该元素所在桶的位置 -> 即数组下标索引int i = indexFor(hash, table.length);/*** 3.遍历链表,若该key存在则更新value,否则新增entry* 判断该key存在的依据有两个:* 1.key的hash一致* 2.key一致(引用一致或字符串一致)* put操作遵循:有则更新,无则新增*/for (Entry<K,V> e = table[i]; e != null; e = e.next) {//使用临时变量k临时存储遍历时的e.key -> 主要是为了代码复用Object k;//hash一致 && (key引用相同 或 key字符串比较相同)if (e.hash == hash && ((k = e.key) == key || key.equals(k))){//值更新V oldValue = e.value;e.value = value;//钩子方法e.recordAccess(this);//返回旧值return oldValue;}}//put操作属于结构变更操作modCount++;//无则新增addEntry(hash, key, value, i);//该key不存在就返回null -> 即新增返回nullreturn null;}
3.2 hash方法
//JDK1.7final int hash(Object k) {int h = 0;if (useAltHashing) {if (k instanceof String) {return sun.misc.Hashing.stringHash32((String) k);}h = hashSeed;}//异或就是两个数的二进制形式,按位对比,相同取0,不同取一//此算法加入了高位计算,防止低位不变,高位变化时,造成的 hash 冲突h ^= k.hashCode();h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);}//JDK1.8 扰动函数 -> 散列值优化函数static final int hash(Object key) {int h;//把一个数右移16位即丢弃低16位,就是任何小于2^16的数,右移16后结果都为0//2的16次方再右移刚好就是1 同时int最大值为32位//任何一个数,与0按位异或的结果都是这个数本身//对于非null的hash值,仅在其大于等于2^16的时候才会重新调整其值return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
3.3 indexFor方法
/*** Int范围(2^32)从-2147483648到2147483648,加起来大概40亿空间,内存不能直接读取* 用之前还要先做对数组的长度取模运算,得到的余数才能用来访问数组下标* @Param h 根据hash方法得到h* @Param length 一定是2次幂*/static int indexFor(int h, int length) {//2次幂-1 返回的结果的二进制为永远是都是1 比如 15 -> 1111 (16 -> 10000)//与运算 只有 1 & 1 = 1 正好相当于一个“低位掩码”//如果length-1中某一位为0,则不论h中对应位的数字为几,对应位结果都是0,这样就让两个h取到同一个结果,hash冲突//同时这个操作可以保证索引不会大于数组的大小(见开头的描述)return h & (length-1);}
3.4 addEntry方法
//该方法为包访问 package java.util(本包私有性高于子类)void addEntry(int hash, K key, V value, int bucketIndex) {/*** 扩容条件:实际容量超过阈值 && 当前坐标数组非空* 有个优雅的设计在于,若bucketIndex处没有Entry对象,* 那么新添加的entry对象指向null,从而就不会有链了*/if ((size >= threshold) && (null != table[bucketIndex])) {//最大容量每次都扩容一倍resize(2 * table.length);//重算hashhash = (null != key) ? hash(key) : 0;//重算indexbucketIndex = indexFor(hash, table.length);}//新增Entry元素到数组的指定下标位置createEntry(hash, key, value, bucketIndex);}//该方法为包访问 package java.utilvoid createEntry(int hash, K key, V value, int bucketIndex) {//获取数组中指定 bucketIndex 下标索引处的 EntryEntry<K,V> e = table[bucketIndex];/*** 将新创建的Entry放入 bucketIndex 索引处,* 并让新的Entry(next)指向原来的Entry形成链表* 新加入的放入链表头部 -> 类似于栈,顶部是最新的入栈元素* 对于"桶"的命名,笔者认为这词儿很形象生动:* 1.桶具有"deep深度"的属性 -> 桶深即链表长度* 2.桶的顶部永远是最新"扔"进入的元素*/table[bucketIndex] = new Entry<>(hash, key, value, e);//元素数量++size++;}
3.5 关于indexFor和hash方法的进一步解读
- hashCode返回的-2147483648到2147483648的int值,加起来大概40亿的映射空间。只要哈希函数映射比较均匀松散,一般很难出现碰撞
key.hashCode()- 但问题是40亿长度数组,内存放不下,该散列值不能直接拿来用。用之前必须先对数组长度取模运算,得到的余数才能来访问数组下标
indexFor()- 长度取2的整次幂,而length-1时正好相当于一个低位掩码。与操作的结果就是散列的高位全部归零,只保留低位值,用作下标访问
10100101 11000100 00100101
& 00000000 00000000 00001111
00000000 00000000 00000101 //高位全部归零,只保留末四位
- 但问题是,无论散列值再松散,但只取最后几位,碰撞也很严重。更要命的是如果散列本身做的不好,分布上成等差数列,就会出现规律性重复,这时候就需要扰动函数进行打散优化.
- 扰动函数生效:
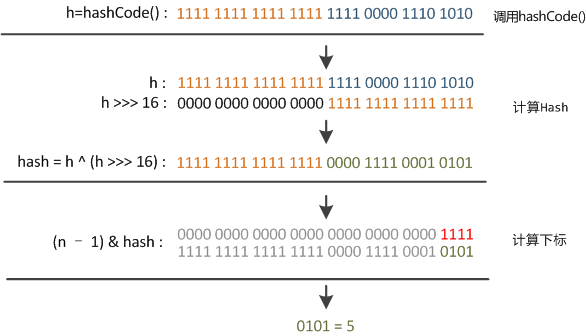
右位移16位(32位一半),让高半区和低半区做异或,目的是混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位包含高位的部分特征,这样高位的信息也变相保留下来。- 当长度非2次幂(最后一位永远是0),进行与运算(只有都为1得1,否则为0),会造成最后一位永远是0,那最后一位就无法使用,导致(1)空间的巨大浪费。同时可使用的位置比原数组长度小很多,(2)进一步增加了碰撞的几率。
3.6 存储 vs 读取
- 存储时,根据hash算法决定其在数组中的存储位置,再根据equals方法决定其在该数组位置上的链表中的存储位置;同时HashMap会根据当前bucket的占用情况自动调整容量(超过loadFacotr则resize为原来的2倍)
- 读取时,根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry。在产生碰撞的情况下,进行get时,两步的时间复杂度是O(1)+O(n)。1.8使用红黑树(O(1)+O(logn))
4.HashMap的扩容
4.1 性能参数
- HashMap的性能瓶颈出现在扩容阶段,而扩容时机由两个重要属性决定:
-
1.initialCapacity: 初始容量,默认16
-
2.loadFactor: 负载因子,衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。对于使用链表法的散列表来说,查找一个元素的平均时间是 O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费;默认的的负载因子 0.75是对空间和时间效率的一个平衡选择;当容量超出此最大容量时, resize后的HashMap 容量是原容量的两倍
4.2 resize方法
- HashMap的扩容采用的数组替换的方式:
-
1.先创建一个两倍于原容量的新数组
-
2.遍历旧数组对新数组赋值,期间会同时完成新旧索引的变更
-
3.新数组替换旧数组引用
-
4.重新计算阈值
/*** Rehashes the contents of this map into a new array with a* larger capacity. This method is called automatically when the* number of keys in this map reaches its threshold.** 目的:通过增加内部数组的长度的方式,从而保证链表中只保留很少的Entry对象,从而降低put(),remove()和get()方法的执行时间* 注意:如果两个Entry对象的键的哈希值不一样,但它们之前在同一个桶上,那么在调整以后,并不能保证它们依然在同一个桶上*/void resize(int newCapacity) {/*** 使用临时拷贝,保证当前数组长度的时效性(参见JAVA的`观察者`模式实现)* 否则多线程环境下很容易造成oldCapacity的变化,* 进而导致由一系列过期数据的造成的错误*/Entry[] oldTable = table;int oldCapacity = oldTable.length;//达到最大容量时禁止扩容 - 边界保护if (oldCapacity == MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return;}//1.实例化一个newCapacity容量的新数组Entry[] newTable = new Entry[newCapacity];boolean oldAltHashing = useAltHashing;useAltHashing |= sun.misc.VM.isBooted() &&(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);boolean rehash = oldAltHashing ^ useAltHashing;//2.遍历旧数组对新数组赋值transfer(newTable, rehash);//3.新数组替换旧数组table = newTable;//4.重新计算阈值threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);}
4.3 transfer方法
/*** Transfers all entries from current table to newTable.*/void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;//注意:如果在新表的数组索引位置相同,则链表元素会倒置,也就是先插入最近的for (Entry<K,V> e : table) {while(null != e) {Entry<K,V> next = e.next;if (rehash) {//重新计算hash null的位置还是tab[0]不变e.hash = null == e.key ? 0 : hash(e.key);}//重新计算下标索引(主要是因为容量变化成2倍)int i = indexFor(e.hash, newCapacity);//注意:多线程环境可能由于执行次序非有序造成next引用变更赋值出错导致环形链接出现,从而造成死循环e.next = newTable[i];newTable[i] = e;e = next;}}}
5.Fail-Fast机制
5.1 错误机制
当使用迭代器的过程中有其他线程修改了map,将抛出ConcurrentModificationException
5.2 源码实现
//修改计数 put、remove或clear时mount++ clear时清空transient int modCount;HashIterator() {expectedModCount = modCount;if (size > 0) {Entry[] t = table;while (index < t.length && (next = t[index++]) == null);}}final Entry<K,V> nextEntry() {//期望变更数量不匹配if (modCount != expectedModCount)throw new ConcurrentModificationException();
5.3 remove方法
5.3.1 HashMap的remove方法实现
public V remove(Object key) {Entry<K,V> e = removeEntryForKey(key);return (e == null ? null : e.value);}
5.3.2 HashMap.KeySet的remove方法实现
public boolean remove(Object o) {return HashMap.this.removeEntryForKey(o) != null;}
5.3.3 HashMap.HashIterator的remove方法实现
public void remove() {if (current == null)throw new IllegalStateException();if (modCount != expectedModCount)throw new ConcurrentModificationException();Object k = current.key;current = null;HashMap.this.removeEntryForKey(k);//重要操作:迭代器中删除时同步了expectedModCount值与modCount相同expectedModCount = modCount;}
5.4 removeEntryForKey方法
/*** Removes and returns the entry associated with the specified key* in the HashMap. Returns null if the HashMap contains no mapping* for this key.*/final Entry<K,V> removeEntryForKey(Object key) {//计算hashint hash = (key == null) ? 0 : hash(key);//根据hash定位数组下标index索引int i = indexFor(hash, table.length);/*** 记录前一个enrty元素(默认从链表首元素开始)* 1.table[i] 表示链表首元素 - 即桶顶部元素* 2.prev会记录遍历时的当前entry的前一个entry*/Entry<K,V> prev = table[i];//沿着链表从头到尾顺序遍历Entry<K,V> e = prev;//遍历key所在链表while (e != null) {//当前key对应entry的下一个entryEntry<K,V> next = e.next;Object k;//1.一旦key一致,即找到该key对应entry便移除并返回该entryif (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {//remove属于结构性更新,modCount计数+1modCount++;//实际元素数量-1size--;/*** 移除当前key对应entry,实际上就是* 通过变更前后链接将该entry从链表中移除* 1.若当前key正好位于链首,则链首指向next* 2.若当前key不位于链首,则该key之前的元素的next指向该key的下一个元素*/if (prev == e)table[i] = next;elseprev.next = next;//LinkedHashMap专用钩子方法e.recordRemoval(this);return e;}//2.找不到就继续往后找//记录当前key对应entryprev = e;//指向下一次循环元素e = next;}return e;}
6.HashMap的迭代
Map map = new HashMap();Iterator iter = map.entrySet().iterator();while (iter.hasNext()) {Map.Entry entry = (Map.Entry) iter.next();Object key = entry.getKey();Object val = entry.getValue();}
7.HashMap的常见面试题
1.什么时候会使用HashMap?他有什么特点?
- 基于Map接口实现的Key-Value容器,允许null值,同时非有序,非同步。
2.你知道HashMap的工作原理吗?
- 参见
归纳- 在Java 8中,如果一个bucket中碰撞冲突的元素超过某个限制(默认是8),则使用红黑树来替换链表,从而提高速度
3.你知道get和put的原理吗?equals()和hashCode()的都有什么作用?
- 通过对key的hashCode()进行hashing,并计算下标( n-1 & hash),从而获得buckets的位置。如果产生碰撞,则利用key.equals()方法去链表或树中去查找对应的节点
4.你知道hash的实现吗?为什么要这样实现?
- 在Java 1.8的实现中,是通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在bucket的n比较小的时候,也能保证考虑到高低bit都参与到hash的计算中,同时不会有太大的开销。
- 使用hash还有一个好处就是 尽可能确保每个链表中的长度一致
5. 如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
- 如果超过了负载因子(默认0.75),则会重新resize一个原来长度两倍的HashMap,并且重新调用hash方法;同时此时很可能出现一系列问题:参见
问题6
6. 你了解重新调整HashMap大小存在什么问题吗?
- 当数据过多时,很可能出现性能瓶颈(包括rehash时间)
使用HashMap时一定保证数量有限- 多线程情况下可能产生条件竞竞争从而造成死循环(具体表现在CPU接近100%)。多线程同时试着调整大小,可能导致存储在链表中的元素的次序颠倒,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历。具体死循环代码参见
transfer(newTable)
多线程环境下推荐使用ConcurrentHashMap
7. 为什么String, Interger这样的wrapper类适合作为键?
- class具有final属性,同时重写equals()和hashCode()
- hashCode变动会导致读取失效
- final同时保证线程安全
对象推荐重写equals和hashCode方法,主要用于Map存取时的对比,同时有利于减少碰撞
8.我们可以使用自定义的对象作为键吗?
- 这是前一个问题的延伸。当然你可能使用任何对象作为键,只要它遵守了equals()和hashCode()方法的定义规则,并且当对象插入到Map中之后将不会再改变了。如果这个自定义对象时不可变的,那么它已经满足了作为键的条件,因为当它创建之后就已经不能改变了
- 典型实例就是ThreadLocal,读者可参见笔者的 并发番@ThreadLocal一文通(1.7版)
9.如何对HashMap进行排序?
- 转换:Map -> Set -> LinkedList(存key)
- 排序:LinkedList自行sort
- 存储:存入有序LinkedHashMap
10.HashMap的remove陷阱?
- 通过Iterator方式可正确遍历完成remove操作
- 直接调用list的remove方法就会抛异常
11.为什么只允许通过iterator进行remove操作?
- HashMap和keySet的remove方法都可以通过传递key参数删除任意的元素
- 而iterator只能删除当前元素(current),一旦删除的元素是iterator对象中next所正在引用的,如果没有通过modCount、 expectedModCount的比较实现快速失败抛出异常,下次循环该元素将成为current指向,此时iterator就遍历了一个已移除的过期数据
- 之所以推荐迭代器remove的根本原因在于只有迭代器的remove方法中实现了变更时于modCount的同步工作
expectedModCount = modCount;
12.如果是遍历过程中增加或修改数据呢?
- 增加或修改数据只能通过Map的put方法实现,在遍历过程中修改数据可以,但如果增加新key就会在下次循环时抛异常,因为在添加新key时modCount也会自增(迭代器只实现了remove方法也是原因之一)
集合番@HashMap一文通(1.7版) 由 黄志鹏kira 创作,采用 知识共享 署名-非商业性使用 4.0 国际 许可协议 进行许可。
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。
