@kiraSally
2018-03-12T10:35:09.000000Z
字数 7625
阅读 4323
集合番@LinkedHashMap一文通(1.7版)
JAVA COLLECTIONS 源码 1.7版本
- 笔者个人博客 kiraSally的掘金个人博客 感谢支持
1.LinkedHashMap的定义
- 底层使用哈希表与双向链表来实现迭代有序,非同步的HashMap
- 新增双向链表维护所有元素的有序性(因此非遍历操作性能可能低于HashMap)
- 包含两种排序方式:访问顺序和插入顺序(默认)
- 访问顺序有利于实现LRU(最近最少访问)
- 遍历速度只与元素总量(size)有关,与容量(capacity)无关
- 此版本为JDK1.7
2.LinkedHashMap的数据结构
2.1 类定义
/*** 充分利用 `多态`,和HashMap操作数据的方法完全一样*/public class LinkedHashMap<K,V>extends HashMap<K,V>implements Map<K,V>
2.2 重要全局变量
/*** The head of the doubly linked list.* 新增一个双向链表维护所有元素,用于排序(header为链表表头);Entry为LinkedHashMap的私有静态内部类实现* header相当于一个串联器,header.before为尾元素,header.after为首元素*/private transient Entry<K,V> header;/*** The iteration ordering method for this linked hash map: <tt>true</tt>* for access-order, <tt>false</tt> for insertion-order.* 该值为true:访问顺序(最近访问元素移至链表尾部)* 该值为false:插入顺序 (先入在前,依次往后)*/private final boolean accessOrder;
2.3 构造器
/*** 1.直接复用HashMap构造器* 2.排序方式默认插入顺序(先入在前,依次往后)*/public LinkedHashMap(int initialCapacity, float loadFactor) {super(initialCapacity, loadFactor);accessOrder = false;}/*** @Param accessOrder false:插入顺序 ; true:访问顺序(最近访问元素移至链表尾部)*/public LinkedHashMap(int initialCapacity, float loadFactor,boolean accessOrder) {super(initialCapacity, loadFactor);this.accessOrder = accessOrder;}
2.4 init方法
/*** Called by superclass constructors and pseudoconstructors (clone,readObject)* before any entries are inserted into the map. Initializes the chain.* 该方法采用模板方法模式,在 HashMap 的实现中并无意义,只是提供给子类实现相关的初始化调用* LinkedHashMap会对header初始化*/@Overridevoid init() {header = new Entry<>(-1, null, null, null);header.before = header.after = header;}
- 假设header地址为0x00000000,那么init之后的header如图所示:

2.5 Entry
/*** LinkedHashMap entry.*/private static class Entry<K,V> extends HashMap.Entry<K,V> {// These fields comprise the doubly linked list used for iteration.//before指向上一个entry,after指向下一个entry,从而形成双向链表,进而实现有序性//迭代时直接沿双向链表遍历,因此迭代速度只与元素总量(size)有关,与容量(capacity)无关Entry<K,V> before, after;Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {super(hash, key, value, next);}/*** Removes this entry from the linked list.*/private void remove() {before.after = after;after.before = before;}/*** Inserts this entry before the specified existing entry in the list.* 新entry插入到双向链表头引用header的前面,这样新entry就成为双向链表中的最后一个元素*/private void addBefore(Entry<K,V> existingEntry) {//需要注意的是existingEntry=headerafter = existingEntry;before = existingEntry.before;before.after = this;after.before = this;}/*** This method is invoked by the superclass whenever the value* of a pre-existing entry is read by Map.get or modified by Map.set.* If the enclosing Map is access-ordered, it moves the entry* to the end of the list; otherwise, it does nothing.*/void recordAccess(HashMap<K,V> m) {LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;if (lm.accessOrder) {lm.modCount++;remove();addBefore(lm.header);}}//模板方法void recordRemoval(HashMap<K,V> m) {remove();}}
3.LinkedHashMap的迭代排序
在研究之前下先直观感受一下两种排序的区别:
3.1 插入排序
LinkedHashMap<Integer,String> linkedHashMap = new LinkedHashMap<Integer,String>();linkedHashMap.put(1,"新恒结衣");linkedHashMap.put(2,"长泽雅美");linkedHashMap.put(3,"佐佐木希");linkedHashMap.put(4,"石原里美");linkedHashMap.put(5,"堀北真希");Iterator iterator = linkedHashMap.entrySet().iterator();while (iterator.hasNext()) {Map.Entry entry = (Map.Entry) iterator.next();System.out.println(entry.getKey() + "=" + entry.getValue());}
如图所示,按照插入顺序(先入在前,依次往后)
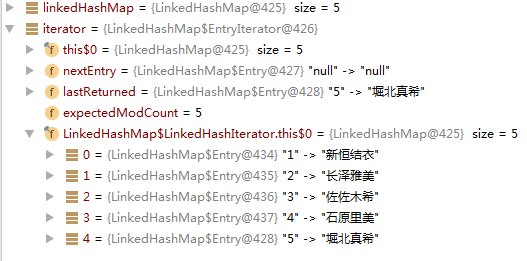
注意:header的key-value永远为null,但before和after已发生变更(双向链表生效)
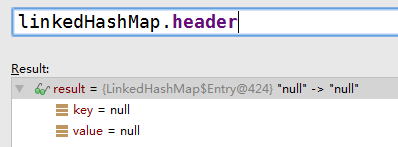
header的before指向链尾元素(结合after从而形成双向环路)
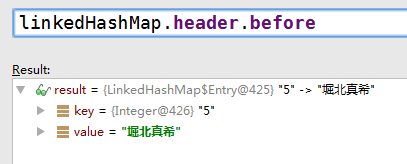
header的after指向链首元素(除去header)
3.2 访问顺序
//注意:访问排序生效需要 accessOrder = trueLinkedHashMap<Integer,String> linkedHashMap = new LinkedHashMap<Integer,String>(16,0.75f,true);linkedHashMap.put(1,"新恒结衣");linkedHashMap.put(2,"长泽雅美");linkedHashMap.put(3,"佐佐木希");linkedHashMap.put(4,"石原里美");linkedHashMap.put(5,"堀北真希");//访问开始linkedHashMap.get(3);linkedHashMap.get(1);Iterator iterator = linkedHashMap.entrySet().iterator();while (iterator.hasNext()) {Map.Entry entry = (Map.Entry) iterator.next();System.out.println(entry.getKey() + "=" + entry.getValue());}
- 如图所示,按照访问顺序(最近访问元素移至链表尾部)
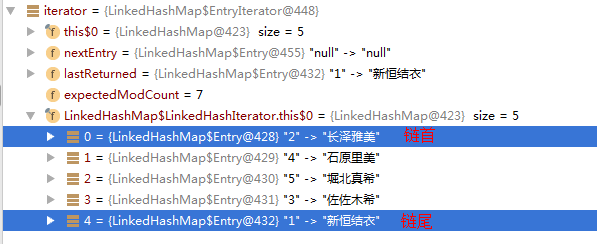
- header的before指向链尾元素
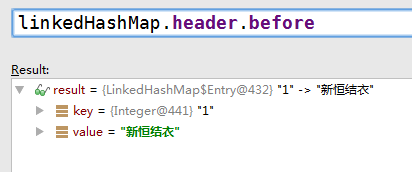
- header的after指向链首元素
4.LinkedHashMap的重要方法
4.1 插入混淆澄清
- 在分析之前有一个重要且易混淆的点需要强调(有助于更好的理解LinkedList和HashMap结合的意义):
-
从table的角度看: 新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部
-
从header的角度看: 新的entry需要插入到双向链表的尾部(
3.排序实例使用该角度描述);而使用双向链表主要是服务于快速有序迭代
4.2 put方法
/*** LinkedHashMap并未重写父类`HashMap`的put方法(因此不要惊讶找不到LinkedHashMap的put方法)* 但重写了父类 HashMap 的 put 方法调用的子方法,以增加双向链表的实现* 重写以下子方法 : recordAccess() 、addEntry()、createEntry()*/public V put(K key, V value) {if (key == null)return putForNullKey(value);int hash = hash(key);int i = indexFor(hash, table.length);for (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;//LinkedHashMap的Entry重写父类recordAccess方法e.recordAccess(this);return oldValue;}}modCount++;//LinkedHashMap重写父类recordAccess方法addEntry(hash, key, value, i);return null;}
4.3 recordAccess方法
/*** 记录访问顺序*/void recordAccess(HashMap<K,V> m) {LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;// 如果定义了LinkedHashMap的迭代顺序为访问顺序,// 则删除以前位置上的元素,并将最新访问的元素添加到链表表头if (lm.accessOrder) {//注意:结构性变动会使得modCount计数+1,用于fail-fast机制lm.modCount++;//变更链表的前后引用,保证有序性remove();//将最新访问的元素添加到链表表头addBefore(lm.header);}}
4.4 addEntry方法
void addEntry(int hash, K key, V value, int bucketIndex) {// 调用create方法,将新元素以双向链表的的形式加入到映射中createEntry(hash, key, value, bucketIndex);// 删除最近最少使用元素的策略定义Entry<K,V> eldest = header.after;//该方法默认返回false,也就意味着LinkedHashMap不会主动删除"过期"元素if (removeEldestEntry(eldest)) {//直接调用父类HashMap的removeEntryForKey()removeEntryForKey(eldest.key);} else {//超过阈值执行resizeif (size >= threshold)//直接调用父类HashMap的resize方法,容量翻倍resize(2 * table.length);}}
4.5 createEntry方法
void createEntry(int hash, K key, V value, int bucketIndex) {HashMap.Entry<K,V> old = table[bucketIndex];Entry<K,V> e = new Entry<K,V>(hash, key, value, old);table[bucketIndex] = e;//将元素加入到哈希、双向链表e.addBefore(header);size++;}
4.6 get方法
/*** 记录访问顺序,将最新访问的元素添加到双向链表的表头,并从原来的位置删除* 链表的增加、删除操作是常量级*/public V get(Object key) {// 调用父类HashMap的getEntry()方法,取得要查找的元素Entry<K,V> e = (Entry<K,V>)getEntry(key);if (e == null)return null;// 记录访问顺序e.recordAccess(this);return e.value;}
4.7 removeEntryForKey方法
/*** LinkedHashMap没有重写removeEntryForKey,而是使用模板方法模式巧妙的实现该方法* 以下为HashMap的removeEntryForKey方法实现*/final Entry<K,V> removeEntryForKey(Object key) {int hash = (key == null) ? 0 : hash(key);int i = indexFor(hash, table.length);// hash&(table.length-1)Entry<K,V> prev = table[i];// 得到冲突链表Entry<K,V> e = prev;while (e != null) {// 遍历冲突链表Entry<K,V> next = e.next;Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entrymodCount++; size--;// 1. 将e从对应bucket的冲突链表中删除if (prev == e) table[i] = next;else prev.next = next;// 2. 将e从双向链表中删除 HashMap中的实际实现为 e.recordRemoval(this)//等用于 before.after = after; after.before = before;e.recordRemoval(this);return e;}prev = e; e = next;}return e;}/*** LinkedHashMap的删除实现*/void recordRemoval(HashMap<K,V> m) {remove();}/*** entry内部执行remove操作时,通过变更链表前后指向删除以前位置上的元素,保证迭代有序性*/private void remove() {before.after = after;after.before = before;}
4.8 remove方法
- 从table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用
- 从header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用
4.9 clear方法
public void clear() {super.clear();//header的所有引用重新指向自己,等同于位置resetheader.before = header.after = header;}
5.LRU实现
5.1 LRU与LinkedHashMap
- LRU算法:将最近一次使用时间离现在时间最远的数据删除掉
- 由于LinkedHashMap的removeEldestEntry默认为false,直接使用LinkedHashMap无法直接实现LRU(没真正删除)
- 但可以通过继承LinkedHashMap的方式,重写removeEldestEntry即可
5.2 removeEldestEntry方法
/*** 默认返回false,不会直接删除元素*/protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return false;}
5.2 重写removeEldestEntry方法
/*** 超过某个常量即可触发删除功能(真正的删除操作JDK已提供实现,只要加判断即可)* 这里只提供核心伪代码实现*/protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return size() > 给定的缓存最大容量;}
集合番@LinkedHashMap一文通(1.7版) 由 黄志鹏kira 创作,采用 知识共享 署名-非商业性使用 4.0 国际 许可协议 进行许可。
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。
