@kiraSally
2018-03-12T10:47:21.000000Z
字数 18888
阅读 4950
基础番@Java新特性(1.8版)
JAVA 基础
- 推荐阅读官方文档
- JEP=JDK Enhancement-Proposal (JDK 增强建议 ),每个JEP即一个新特性
- 致谢 Java 8新特性终极指南
- 笔者个人博客 kiraSally的掘金个人博客 感谢支持
1 Java8语言的新特性
1.1 接口的默认与静态方法
- 接口默认和静态方法的定义
- 起因:要实现在不破坏Java现有实现架构的情况下能往接口里增加新方法的能力
- 痛点:比如在集合接口中新增一个foreach方法,那意味着所有实现该接口的类都需要变动,即改变了原实现架构;同时因为不能牺牲向后兼容,而不可以把Lambda表达式和标准集合类库结合使用
- 实现: Java8通过引入虚拟扩展方法,即
default关键字(原保留字),从而可以给接口任意方法提供默认实现- 好处:
default可以为声明的方法提供默认的实现,从而不用改变实现类的原有结构- 同时被
default定义的方法一样可以被实现类重写或者选择继承默认的实现- 默认方法结束了经典模式-提供一个接口和实现该接口大多数或全部方法的伴随类(如
Map和AbstractMap),现在只要在接口中实现方法即可
- 接口默认和静态方法的使用
public interface Collection {default void foreach(){System.out.println("Calling Collection.foreach");}}public class ArrayList implements Collection {} //继承默认实现public class LinkedList implements Collection { //重写默认实现@Overridepublic void foreach(){System.out.println("Calling LinkedList.foreach");}}---------------new ArrayList().foreach() ==> "Calling Collection.foreach" //继承默认实现new LinkedList().foreach() ==> "Calling LinkedList.foreach" //重写默认实现---------------
- 解决默认方法冲突
- 起因:如果一个实现2个接口,其中一个接口有个默认方法与另一个接口的默认方法一模一样,就冲突了
- 解决方案:此时编译器会报错,用于解决歧义,同时只要在实现类中指明执行哪个方法即可
- 注意:如果没有任何接口为共享方法提供默认实现,那么就没有冲突。实现类有两种选择:实现方法,或不实现方法并将该类声明为抽象类
- 注意:如果一个类继承一个父类且实现一个接口,而且从父类和接口都继承了同样的方法,这时候只关心父类的方法,直接忽视来自接口的默认方法,即Java8使用"类比接口优先"原则(class win)
public interface User {default void getId(){System.out.println("Calling User.getId");}}public interface Agent {default void getId(){System.out.println("Calling Agent.foreach");}}//该类同时实现User,Agent接口,同时两个接口有一模一样的getId默认实现public class Employee implements User,Agent {public void getId(){//指明执行哪个接口的方法或者重写方法return User.super().getId();//这里选择指定User的getId方法}}---------------new Employee().getId() ==> "Calling User.getId"---------------
1.2 方法引用
- 方法引用的定义
- 作用:可以直接引用已有Java类或对象(实例)的方法或构造器,Java8中方法也是种对象
- 目的:服务于Lambda,方法引用可以使语言的构造更紧凑简洁,重复利用已有的方法,减少冗余代码
- 使用分类:Java官方文档提供了四种方法引用的实现方案

- 接口默认和静态方法的使用
//类定义public static class Girl {public String name;public Integer age;public Girl() {}public Girl(String name,Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public static int compareByAge(Girl prev, Girl after) {return prev.getAge().compareTo(after.getAge());}public int compareByName(Girl prev, Girl after) {return prev.getName().compareTo(after.getName());}public int compareByHash(Girl girl) {return this.hashCode() > girl.hashCode() ? 1 : 0;}}//工厂接口@FunctionalInterfacepublic interface GirlFactory<Girl> {Girl create(String name, Integer age); // 有参//Girl create(); 无参}
- 第一种方法引用是静态方法引用,语法规则:Class::static_method
//例子: String::valueOf,对应的Lambda:(s) -> String.valueOf(s)Girl[] girls = new Girl[10];GirlFactory<Girl> girlFactory = Girl::new;girls[0] = girlFactory.create("sally",18);girls[1] = girlFactory.create("mengmeng",3);Arrays.sort(girls,Girl::compareByAge);//类:静态方法
- 第二种方法引用是特定对象的方法引用,它的语法是containingObject::instanceMethodName
//例子: x::toString,对应的Lambda:() -> this.toString()Girl[] girls = new Girl[10];Girl xifu = girlFactory.create("sally",18);GirlFactory<Girl> girlFactory = Girl::new;girls[0] = xifu;girls[1] = girlFactory.create("mengmeng",3);Arrays.sort(girls,xifu::compareByName);//实例:实例方法
- 第三种方法引用是特定类的任意对象的方法引用,它的语法是ContainingType::methodName
//例子: String::toString,对应的Lambda:(s) -> s.toString()Girl[] girls = new Girl[10];GirlFactory<Girl> girlFactory = Girl::new;girls[0] = girlFactory.create("sally",18);girls[1] = girlFactory.create("mengmeng",3);Arrays.sort(girls,Girl::compareByHash);//类:实例方法
- 第四种方法引用是构造器引用,语法规则:是Class::new,或者更一般的Class::new
//例子: String::new,对应的Lambda:() -> new String()//法1 - 无参Supplier<Girl> supplier = Girl::new;Girl girl = supplier.get();//法2 - 无参GirlFactory<Girl> girlFactory = Girl::new;Girl girl = girlFactory.create();//注意GirlFactory要定义为无参//法3 - 有参GirlFactory<Girl> girlFactory = Girl::new;Girl girl = girlFactory.create("sally",18);//注意GirlFactory要定义为有参
1.3 重复注解
- 重复注解的定义
- 允许在同一申明类型(类,属性,或方法)的多次使用同一个注解
- JAVA7 重复注解的实现
public @interface Privilege {String functionCode();}public @interface Privileges {Privilege[] value();}public class RepeatAnnotation4Auth {//用存储注解Privileges来扩展重复注解@Privileges({@Privilege(functionCode="Add"),@Privilege(functionCode="Delete")})public void doSomeTing(){}}
- JAVA8 重复注解的使用
//不同的地方是,加上@Repeatable,并指向存储注解Privileges,使其拥有了可存储的空间@Repeatable(Privileges.class)public @interface Privilege {String functionCode();}public @interface Privileges {Privilege[] value();}public class RepeatAnnotation4Auth {//可以直接使用多个重复注解Privilege,主要作用是提高代码的可读性@Privilege(functionCode="Add")@Privilege(functionCode="Delete")public void doSomeTing(){}}
1.4 函数式接口
- 函数式接口(Functional interfaces)
- 定义:只拥有一个方法的接口称为函数式接口
- 使用: JAVA8中使用
@FunctionalInterface注解来显式指定一个接口是函数式接口- 作用:主要是用来搭配lambda表达式,简化语法,减少代码量
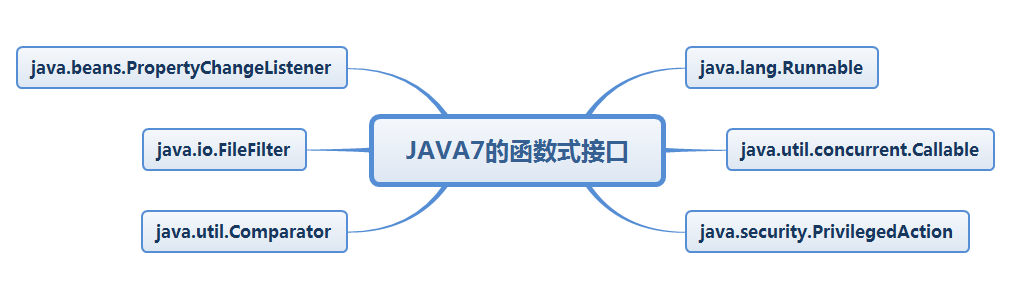
JAVA7已有的函数式接口
JAVA8新增的函数式接口
Java SE 8中增加了一个新的包:java.util.function,它里面包含了常用的函数式接口
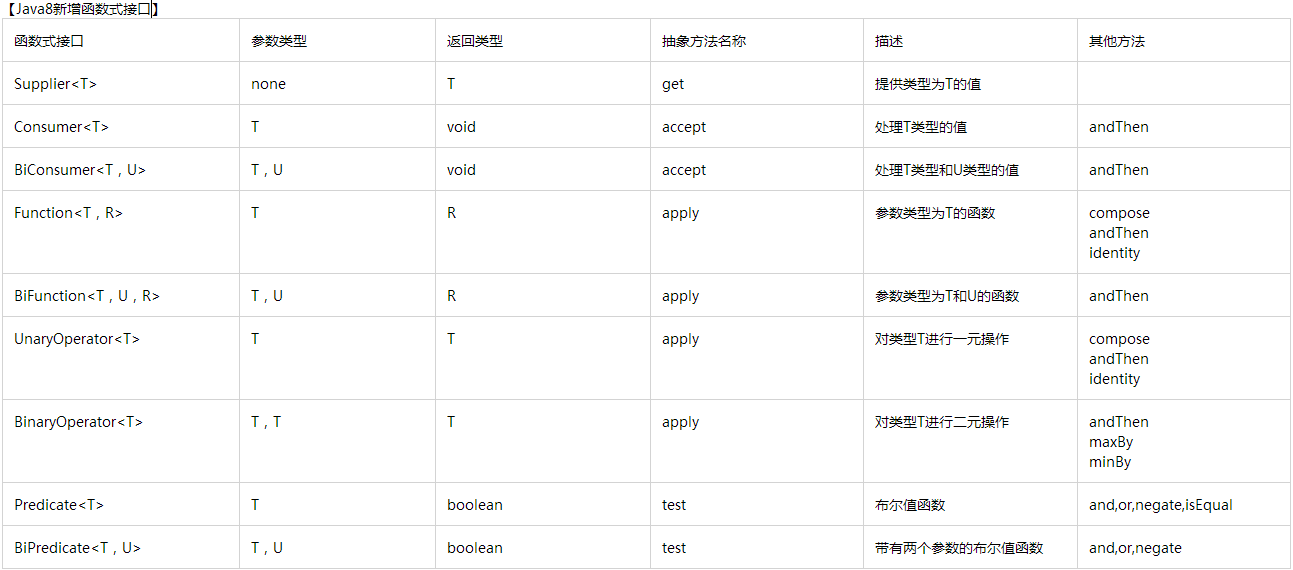
同时为int、long和double提供了特化函数式接口
1.5 Lambda表达式
- Lambda表达式(lambda expressions)
起源: 论函数式编程、并发、回调的流行之"谜"
定义: Lambda表达式:简洁地表示可传递的匿名函数的一种方式
作用: Lambda表达式提供了轻量级的语法,从而解决了匿名内部类带来的"高度问题"
使用: Lambda表达式的语法由参数列表、箭头符号->和函数体组成,函数体可以是一个表达式或一个语句块。
注意: Lambda表达式返回的是接口本身,或者说是匿名类的实现,这不同于JS的表达式可以直接执行得出结果!!!不要搞混!!!不要搞混!!!不要搞混!!!
注意: Lambda表达式对值封闭,对变量开放(一定要搞清楚基本类型和引用类型对参数传递的影响!!!)
补充:《java核心技术》:java程序设计语言总是采用值调用。也就是说,方法得到的是所有参数值的一个拷贝,特别是,方法不能修改传递给它的任何参数变量的内容
补充: 推荐读者适当接触一下Groovy和Scala,来更深刻的体会Lambda的语法便利性
~花絮~:笔者实习阶段一直用的是Groovy,当初的第一感觉就是JS版的JAVA==,后来接触了函数式编程才恍然大悟
- Lambda表达式之表达式
定义: 表达式会被执行然后返回执行结果
- 当Lambda表达式可以直接用表达式作为表达体时,如下:
new Thread(() -> System.out.println("In Java8!"));
- Lambda表达式之语句块
- 定义: 语句块中的语句会被依次执行
- 补充: return语句会把控制权交给匿名方法的调用者
- 补充: break和continue只能在循环中使用
- 补充: 如果函数体有返回值,那么函数体内部的每一条路径都必须返回值
- 当Lambda表达式无法用一个表达式作为表达体时,可用语句块,即:{}
strList.sort( ( e1, e2 ) -> {return e1.compareTo( e2 );} );
- 当Lambda表达式没有参数,提供空的小括号,就像没有参数的方法:
Runnable task = () -> {for (int i = 2; i < 22; i++) doSomeThing(); }
- 当Lambda表达式的参数类型可以被推导出,则可以省略类型:
Comparator<Integer> comp = (prev,after) -> prev.getNum() - after.getNum();
- 当方法只有一个参数,并且参数类型可以被推导,可以省略小括号:
EventHandler<ActionEvent> listenr = event -> System.out.println("Hello World!");
Lambda表达式举例讲解
对数组进行排序
/*** Arrays类的sort方法* @Param a 数组* @Param c 比较器*/public static <T> void sort(T[] a, Comparator<? super T> c)//1.函数式接口@FunctionalInterfacepublic interface Comparator<T> {int compare(T o1, T o2);}//2.Lambda表达式 s1和s2对应接口的o1和o2,并实现compare方法,该表达式会返回一个Comparator的实例Comparator<String> comp = (s1, s2) -> s1.compareToIgnoreCase(s2);//3.使用实例 直接传入comp对象Arrays.sort(array,comp);
- 使用Supplier提供类型为T的值
//1.函数式接口@FunctionalInterfacepublic interface Runnable {public abstract void run();}@FunctionalInterfacepublic interface Supplier<T> {T get();}//2.利用目标类型上下文的推到性可知Supplier<Runnable> c = () -> () -> { System.out.println("hi"); };//2.1 内层的 () -> { System.out.println("hi"); } 对应 Runnable的run方法//其中run无参,并实现run方法,返回Runable对象//2.2 外层的 () -> 对应Supplier的get方法 当时用get方法时会返回一个T对象//3.使用实例 启动线程new Thread(c.get()).start(); 或者 c.get().run()
- 极力推荐一篇Lambda博客
深入理解Java 8 Lambda(语言篇——lambda,方法引用,目标类型和默认方法)
1.6 更好的类型推测机制
- 更好的类型推测机制
Java 8在类型推测方面有了很大的提高。在很多情况下,编译器可以推测出确定的参数类型,这样就能使代码更整洁
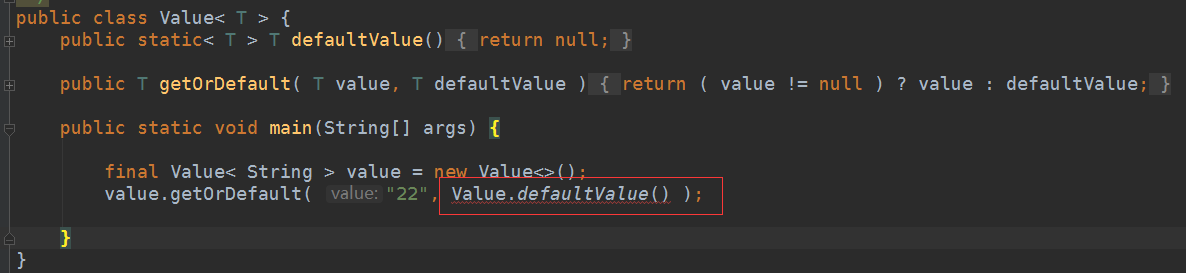
- JAVA7会出现编译错误
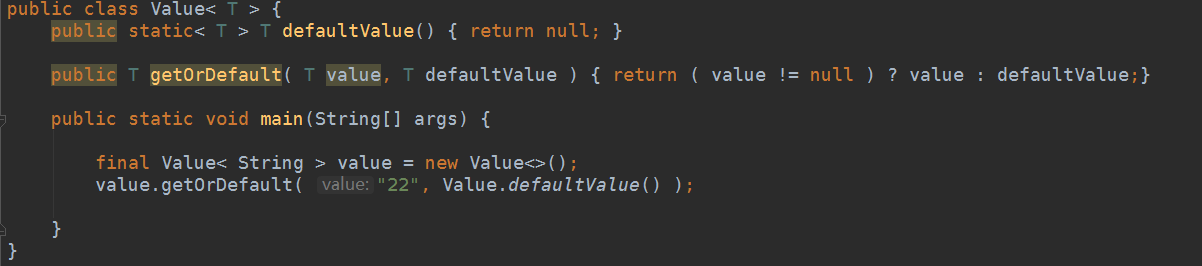
- JAVA8提供语法支持
1.7 扩展注解的支持
- Java 8扩展了注解的上下文。现在几乎可以为任何东西添加注解:局部变量、泛型类、父类与接口的实现,就连方法的异常也能添加注解
- 新增两个注解上下文:
ElementType.TYPE_USE和ElementType.TYPE_PARAMETER
2 Java8类库的新特性
2.1 Optional
- 什么是Optional
- 定义:
Optional是可以保存类型T的值,或者仅仅保存null的容器对象- 作用:
Optional提供很多有用的方法,这样我们就不用显式进行空值检测- 使用: 如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象
- 补充: 有机会将专门开基础包的源码解析番
- OptionalDemo
import java.util.NoSuchElementException;import java.util.Optional;public class OptionalDemo {public static void main(String[] args) {//of : 为非null的值创建一个Optional//方法定义 : public static <T> Optional<T> of(T value)Optional<String> xifu = Optional.of("sally");System.out.println("xifu is " + xifu.get());//结果:sally//需要注意的是,创建对象时传入的参数不能为null。如果传入参数为null,则抛出NullPointerExceptiontry {System.out.println(Optional.of(null));} catch (NoSuchElementException ex) {System.out.println(ex.getMessage());//结果:java.lang.NullPointerException}//ofNullable : 为指定的值创建一个Optional,如果指定的值为null,则返回一个空的Optional//ofNullable与of方法相似,唯一的区别是可以接受参数为null的情况//方法定义 : public static <T> Optional<T> ofNullable(T value)Optional empty = Optional.ofNullable(null);System.out.println("empty is " + empty);//结果:empty is Optional.emptytry {//在Optional实例上调用get()抛出NoSuchElementExceptionSystem.out.println(empty.get());} catch (NoSuchElementException ex) {//结果:java.util.NoSuchElementException: No value presentSystem.out.println(ex.getMessage());}//ifPresent : 如果值存在返回true,否则返回false//方法定义 : public void ifPresent(Consumer<? super T> consumer)System.out.println("xifu is existed : " + xifu.isPresent());//结果:xifu is existed : trueSystem.out.println("empty is existed : " + empty.isPresent());//结果:empty is existed : false//同时接受Lambda表达式(Consumer),如果Optional值不为空,lambda表达式会处理并在其上执行操作xifu.ifPresent((value) -> {//结果:The length of the value is: 5System.out.println("The length of the value is: " + value.length());});//如果Optional值不为空,lambda表达式不会执行empty.ifPresent((value) -> {System.out.println("The length of the value is: " + value);//结果:根本不会执行// System.out.println("The length of the value is: " + value.length());//结果:编译报错});//orElse : 如果有值则将其返回,否则返回指定的其它值//如果有值orElse方法会返回Optional实例,否则返回传入的错误信息//方法定义 : public T orElse(T other)System.out.println(xifu.orElse("There is no value present !"));//结果:sallySystem.out.println(empty.orElse("There is some value !"));//结果:There is no value present//orElseGet : orElseGet与orElse类似,区别在于传入的默认值//orElseGet方法可以接受Supplier接口的实现用来生成默认值 注:Supplier -> T get()//方法定义:public T orElseGet(Supplier<? extends T> other)System.out.println(xifu.orElseGet(() -> "Default Value"));//结果:sallySystem.out.println(empty.orElseGet(() -> "Default Value"));//结果:Default Value//orElseThrow : 如果有值则将其返回,否则抛出supplier接口创建的异常//方法定义 : public <X extends Throwable> T orElseThrow(// Supplier<? extends X> exceptionSupplier) throws Xtry {//orElseThrow与orElse方法类似,区别在于返回值//orElseThrow抛出由传入的lambda表达式/方法生成异常(Supplier)empty.orElseThrow(NullPointerException::new);//可以是自定义异常} catch (Throwable ex) {System.out.println(ex.getMessage());//结果:null}//map : 如果有值,则对其执行调用mapping函数得到返回值//如果返回值不为null,则创建包含mapping返回值的Optional作为map方法返回值,否则返回空Optional//lambda表达式(Function)返回值会包装为Optional实例//方法定义 : public<U> Optional<U> map(Function<? super T, ? extends U> mapper)Optional<String> upperName = xifu.map((value) -> value.toUpperCase());System.out.println(upperName.orElse("No value found"));//结果:SALLYupperName = xifu.flatMap((value) -> Optional.of(value.toLowerCase()));System.out.println(upperName.orElse("No value found"));//结果:sally//filter : 如果有值并且满足断言条件返回包含该值的Optional,否则返回空Optional//支持lambda表达式(Predicate)//方法定义: public Optional<T> filter(Predicate<? super T> predicate)//如果满足返回Optional实例值,否则返回空OptionalOptional<String> longName = xifu.filter((value) -> value.length() > 2);System.out.println(longName.orElse("The name is less than 6 characters"));//结果:sally//另一个示例,Optional值不满足给定条件Optional<String> anotherName = Optional.of("kira");Optional<String> shortName = anotherName.filter((value) -> value.length() > 6);//结果:The name is less than 6 charactersSystem.out.println(shortName.orElse("The name is less than 6 characters"));}}
2.2 Streams
- 什么是Streams
- 定义:
Streams提供了数据视图,可以在比集合类更高的维度指定操作,只需将操作的调度执行留给实现- 作用:
Streams提供了对集合操作的增强,极大的提高了操作集合对象的便利性(注意与IO的Stream不是一回事)- 使用: Java8 新增
java.util.stream包,其中如Stream接口提供很多有用的API方法,方便集合处理- 补充: 当指定数据源和属性后,流类库会优化计算,比如使用多线程求和、计数以及合并结果等
- 补充:
Stream遵循 "做什么而不是怎么去做" 的原则- 补充: 有机会将专门开
java.util.stream包的源码解析番,具体方法请参见API,这里只是简单展现
- 流vs 集合
- 流不存储元素,它们存储在底层的集合或者按需生成;
- 流操作不改变它们的源数据,比如filter不会从新流中删除元素而是生成一个不包含特定元素的新流;
- 流操作可能是延迟执行的,这就意味着直到需要结果的时候,方法才会执行,比如只是查找前5个元素,filter在找到第5个匹配元素后就会停止执行,因此,你甚至可以拥有一个无限流;
- 集合的迭代器使用了一种明确的遍历策略,同时阻止了高效的并发执行,而流天然提供了并发处理方法
- 你可以从集合、数组、生成器或迭代器创建流,因此只要是包含聚集概念的对象都可以使用流
- 流还能够提供类似SQL的分组分片(groupingBy)和分组约束(having)比如maxBy、mapping、counting等方法
- 流的创建
String beautyStr = "有村架纯,桥本环奈,斋藤飞鸟,逢泽莉娜,神楽坂真冬";String [] beautyArr = beautyStr.split(",");//创建流,可使用Collection接口的stream方法将任何集合转化为StreamStream<String> stream4List = Arrays.asList(beautyArr).stream();//创建流,当是一个数组时,则使用静态方法Stream.of将它转化成一个StreamStream<String> stream4Array1 = Stream.of(beautyArr);//同时of接收可变长的参数,所有可以构建一个含有任意个参数的Stream//方法定义 : public static<T> Stream<T> of(T... values)Stream<String> stream4Array2 = Stream.of("A","B","C");//创建一个不含任何元素的Stream,可以使用静态的Stream.empty方法Stream empty = Stream.empty();//Stream接口有两个用来创建无限Stream的静态方法//generate : 接受一个无参函数,当需要一个Stream值时,可以调用该方法产生一个值//方法定义 : public static<T> Stream<T> generate(Supplier<T> s)Stream<String> meiZiStream = Stream.generate(() -> "MeiZi!");//iterate : 接受一个种子值和一个函数,并且会对之前的值重复应用该函数//方法定义 : public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)//创建一个0 1 2 这样无限等差数列Stream<BigInteger> integerStream = Stream.iterate(BigInteger.ZERO,n -> n.add(BigInteger.ONE));//JavaAPI含有多个可生成Stream方法,读者可执行寻找,比如Pattern的splitAsStream(),Files的lines()
- filter、map、flatMap
//filter : 转换生成一个匹配一定条件的新流//方法定义 : Stream<T> filter(Predicate<? super T> predicate)Stream<String> streamByFilter = stream4List.filter(w -> w.length() > 3);//map : 将流中的值进行某种形式的转换,函数将作用于每个元素,将昌盛一个包含最终结果的新流//方法定义 : <R> Stream<R> map(Function<? super T, ? extends R> mapper)Stream<String> streamByMap = stream4List.map(String::toLowerCase);Stream<String> streamByMap2 = stream4List.map(s -> s.substring(0,2));//flatMap : 把N个list合并为一个list//方法定义 : <R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)Stream<String> streamByFlatMap = stream4List.flatMap(s -> {List<String> list = new ArrayList<>();for (int i = 0 ; i < s.length() ; i++){list.add(s.substring(i,i+1));}return list.stream();});
- 提取子流和组合流
//limit : 返回一个包含n个元素的新流(若原始流长度小于,则会返回原始流)//方法定义 : Stream<T> limit(long maxSize);Stream<Double> streamByLimit = Stream.generate(Math::random).limit(100);//skip : 返回一个丢弃n个元素的新流//方法定义 : Stream<T> skip(long n);Stream<Double> streamBySkip = streamByLimit.skip(50);//concat : 合并两个流//方法定义 : public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)Stream<Double> streamByContact = Stream.concat(streamByLimit,streamBySkip);
- 其他流转换
Stream<String> stream = Stream.of("sally","sally","mengmeng","kira");//distinct : 返回一个具有相同顺序、非重复的流,类似LinkedHashSet//方法定义 : Stream<T> distinct();Stream<String> uniqueName = stream.distinct();//返回 sally、mengmeng、kira//sorted : 返回一个其元素是原始流中元素按照排序顺序重新排列的新流//方法定义 : Stream<T> sorted(Comparator<? super T> comparator);Stream<String> streamBySort = stream.sorted(Comparator.comparing(String::length));//peek : 返回一个与原始流一样一样有着相同元素的另一个流,但是每当检索一个元素时函数就调用一次,一般用于断点调试//方法定义 : Stream<T> peek(Consumer<? super T> action)Stream.iterate(1.0,p -> p * 2).peek(e -> System.out.println("echo" + e)).limit(10);
- 收集结果
//forEach : 遍历流中的每个元素//方法定义 : void forEach(Consumer<? super T> action);stream.forEach(System.out::println);//collect : 将流元素收集到指定目标容器中//方法定义 : <R, A> R collect(Collector<? super T, A, R> collector);Set<String> set = stream.collect(Collectors.toCollection(HashSet::new));List<String> list = stream.collect(Collectors.toList());String [] array = stream.toArray(String[]::new);Map<String,Integer> map = stream.collect(Collectors.toMap(String::trim,String::length));//若想将流结果变成求和、平均值、最大值或者最小值,那么需要使用//方法定义 : Collector<T, ?, IntSummaryStatistics> summarizingInt(ToIntFunction<? super T> mapper)IntSummaryStatistics summaryStatistics = stream.collect(Collectors.summarizingInt(String::length));Long sum = summaryStatistics.getSum();//求和Double average = summaryStatistics.getAverage();//平均值Integer max = summaryStatistics.getMax();//最大值Integer min = summaryStatistics.getMin();//最小值
- 归约操作
- map和reduce的连接通常称为map-reduce模式(常见于大数据处理)
Stream<Integer> integerStream = Stream.of(10,20,30);//reduce : 用来计算流中某个值的一种通用机制:即归约操作-结合 比如求和、乘积、凭借、交集、合集等等//效果:可以将流中元素反复结合起来,最终得到一个值//方法定义 : Optional<T> reduce(BinaryOperator<T> accumulator);Integer sum = integerStream.reduce((x,y) -> x + y).get(); //结果:60Integer sum2 = integerStream.reduce(100,(x,y) -> x + y); //从100开始计算,结果:160
- 基本类型流
//像归约操作的累加,完全可以使用更高效的映射数字流的写法//Stream库提供IntStream、LongStream、DoubleStream类型,专门用来直接存储基本数据类型值//当存储float、char、byte或boolean,使用IntStream;对于float,使用DoubleStreamIntStream stream = Stream.of("sally","sally","mengmeng","kira").mapToInt(String::length);stream.sum();//求和stream.average();//平均值-------------------------关于数据的各项处理请看API
- 并行流
- 只要在终止方法执行时流处于并行模式,那么所有延迟执行的流操作就会被并行执行
- 并行模式下,操作是无状态的,并且可以以任意顺序执行,同时数据有序并不会妨碍高效得并行
- 有一点必须要遵守:确保所有传递给并行流操作的函数都是线程安全的,实现这个目标最好的方式就是远离可变状态
- 同时当正在执行流操作时,不要修改流底层依赖的集合(即使修改操作是线程安全的)
- 注意流不会收集他们的数据--数据始终在一个单独的集合中
- 如果修改原有集合,那么流操作的输出就是未确定的(这点对于串行流和并行流都是适用的),原因在于中间流操作属于"延迟执行",因此可能直到终止操作执行那一刻,才会修改集合
//使用Collection.parallelStream()可以从任何集合中获得一个并行流Stream<String> parallelStream = list.parallelStream();//同时支持将串行流转换成并行流Stream<String> toParallelStream = list.stream().parallel();
2.3 Date/Time API
- 现有API存在的问题
- 线程安全: Date和Calendar不是线程安全的,你需要编写额外的代码处理线程安全问题(比如线程安全问题)
- API设计和易用性: 由于Date和Calendar的设计不当你无法完成日常的日期操作
- ZonedDate和Time: 你必须编写额外的逻辑处理时区和那些旧的逻辑
- 致谢:跟上Java8 - 日期和时间实用技巧,具体参见API
- 新的日期API
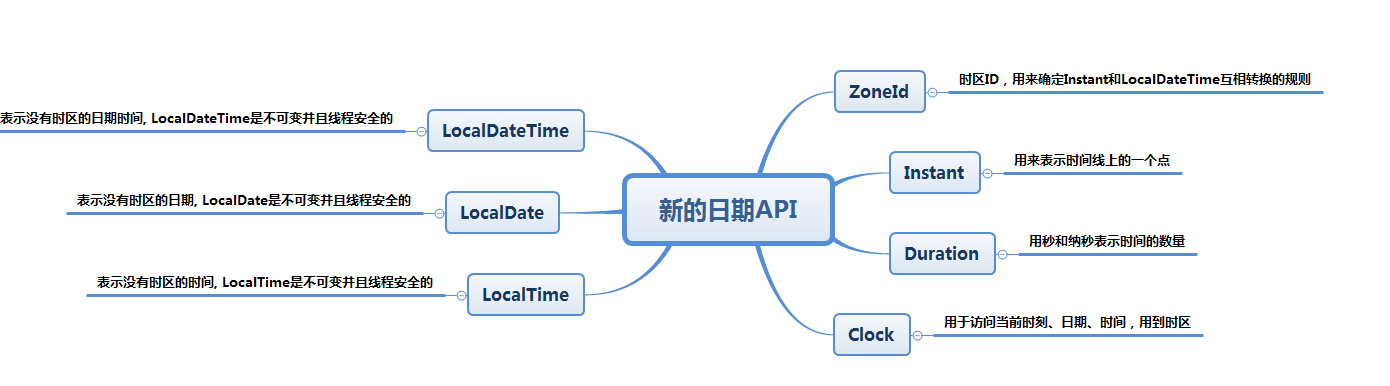
2.4 Base64
- Base64实现的变迁
- JAVA7时代可选的Base64主要有两个:
1.Sun/Oracle JDK里面的sun.misc.BASE64Encoder和sun.misc.BASE64Decoder
2.JDK1.6中添加的javax.xml.bind.DatatypeConverter两个静态方法parseBase64Binary和printBase64Binary- Sun的问题是依赖第三方类库,且性能不佳;JDK版本的隐藏较深,性能一般
- Java 8在java.util包下面实现了
java.util.Base64编解码API,而且性能不俗,API也简单易懂- 致谢:Java 8新特性探究(十一)Base64详解,具体参见API
- Base64Demo
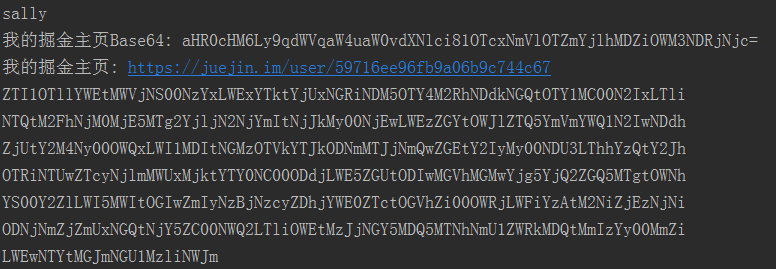
try {//1.Basic编码:是标准的BASE64编码,用于处理常规的需求//编码String base64 = Base64.getEncoder().encodeToString("sally".getBytes("utf-8"));System.out.println(base64);//解码byte[] bytes = Base64.getDecoder().decode("c2FsbHk=");System.out.println(new String(bytes, "utf-8"));//2.URL编码:使用下划线替换URL里面的反斜线“/”String urlEncoded = Base64.getUrlEncoder().encodeToString("https://juejin.im/user/59716ee96fb9a06b9c744c67".getBytes("utf-8"));System.out.println("我的掘金主页Base64: " + urlEncoded);byte[] urlBytes = Base64.getUrlDecoder().decode(urlEncoded);System.out.println("我的掘金主页: " + new String(urlBytes, "utf-8"));//3.MIME编码:使用基本的字母数字产生BASE64输出//同时对MIME格式友好:每一行输出不超过76个字符,而且每行以“\r\n”符结束StringBuilder sb = new StringBuilder();for (int t = 0; t < 10; ++t) {sb.append(UUID.randomUUID().toString());}byte[] toEncode = new byte[0];try {toEncode = sb.toString().getBytes("utf-8");} catch (UnsupportedEncodingException e) {e.printStackTrace();}String mimeEncoded = Base64.getMimeEncoder().encodeToString(toEncode);System.out.println(mimeEncoded);} catch (UnsupportedEncodingException e) {e.printStackTrace();}
输出结果:
2.5 并行数组
- Java 8增加了大量的新方法来对数组进行并行处理
- 最重要的是parallelSort()方法,因为它可以在多核机器上极大提高数组排序的速度
- parallelDemo
//对一个有20000个元素的数组进行随机赋值long[] arrayOfLong = new long [ 20000 ];Arrays.parallelSetAll( arrayOfLong,index -> ThreadLocalRandom.current().nextInt( 1000000 ) );Arrays.stream( arrayOfLong ).limit( 10 ).forEach(i -> System.out.print( i + " " ) );//对前10个元素进行排序Arrays.parallelSort( arrayOfLong );Arrays.stream( arrayOfLong ).limit( 10 ).forEach(i -> System.out.print( i + " " ) );
结果:

2.6 并发
- java.util.concurrent包新增接口和类
- java.util.concurrent中增加了两个接口四个类

- java.util.concurrent.atomic包新增类
Doug lea大神增加了四个新的类:DoubleAccumulator、DoubleAdder、LongAccumulator、LongAdder- 问题: Atomic类原理是通过CAS来保证并发时操作的原子性,但CAS的失败次数会随着高并发而增多,从而导致线程的更多次重试,最后导致效率降低【关于并发包请期待笔者的并发番】
- 优化: 新类通过减少并发,将单个value的更新压力分担到多个value中去,降低单个value的"热度"以提高高并发情况下的吞吐量
- java.util.concurrent.locks包新增类
- 新增
StampedLock类,用于替换不常用的ReentrantReadWriteLock,注定成为新宠ReentrantReadWriteLock问题:在写入较少时, 可能会有饥饿(Starvation)问题,即写线程一直无法竞争到锁从而一直处于等待状态StampedLock为读写操作提供了三种模式:Reading、Writing、ReadingOptimistic(乐观读)- 乐观读:当读多写少时,可乐观地认为读写同时发生几率很少,因此不悲观地使用完全的读取锁定,在读取时,可以先判断是否已执行写变更,再采取后续的措施(重新读取变更信息,或者抛出异常)
- 乐观读依靠不占用读锁可大幅度提高程序的吞吐量
- ConcurrentHashMap新增方法
- 由于JAVA8 引入Lambad和Stream,几乎所有的集合类都相对应新增了方法来强化集合处理
ConcurrentHashMap类新增了几十个方法,主要集中于增加了流的相关方法,强化了缓存概念,比如forEeach、reduce、search、mappingCount等方法
- ForkJoinPool新增方法
- 主要增加两个静态方法 getCommonPoolParallelism() 、commonPool(),主要用于获取池资源
3 Java8虚拟机新特性
- 变更
- PermGen空间被移除了,取而代之的是Metaspace(元空间)
- JVM选项-XX:PermSize与-XX:MaxPermSize分别被-XX:MetaSpaceSize与-XX:MaxMetaspaceSize所代替

- 为什么PermGen->Metaspace
- 字符串存在永久代中,容易出现性能问题和内存溢出
- 永久代会为 GC 带来不必要的复杂度,并且回收效率偏低
- Oracle 可能会将HotSpot 与 JRockit 合二为一
- 类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出
- 致谢:Java8内存模型—永久代(PermGen)和元空间(Metaspace)
基础番@Java新特性(1.8版) 由 黄志鹏kira 创作,采用 知识共享 署名-非商业性使用 4.0 国际 许可协议 进行许可。
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名。
