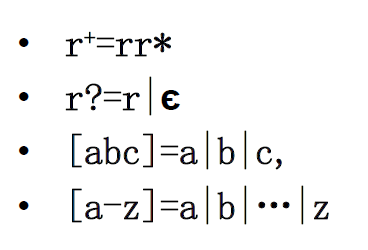@gzm1997
2017-09-15T13:52:38.000000Z
字数 1280
阅读 1590
编译原理第1次课笔记
编译原理笔记
编译型语言和非编译型语言
- 编译型语言(就是需要编译才可以运行的)
对 C 语言或者其他编译型语言来说,编译生成了目标文件,而这个目标文件是针对特定的 CPU 体系的,为 ARM 生成的目标文件,不能被用于 MIPS 的 CPU
- 非编译型语言(例如python和java,他们也可能需要一些编译,但是需要解释为cpu指令)
对于各种非编译型语言(例如python/java)来说,同样也可能存在某种编译过程,但他们编译生成的通常是一种『平台无关』的中间代码,这种代码一般不是针对特定的 CPU 平台,他们是在运行过程中才被翻译成目标 CPU 指令的,因而,在 ARM CPU 上能执行,换到 MIPS 也能执行,换到 X86 也能执行,不需要重新对源代码进行编译
也许上述就是python这些语言可以在不同平台上运行的原因,因为他们是编译后生成某种平台无关的中间代码,然后再运行的时候再翻译为指令
编译型语言在编译过程中生成目标平台的指令,解释型语言在运行过程中才生成目标平台的指令。
语言处理系统
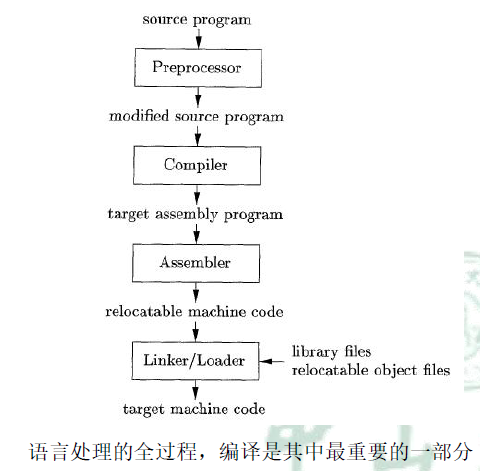
在语言处理全过程中,编译时其中最重要一部分
compiler 编译器
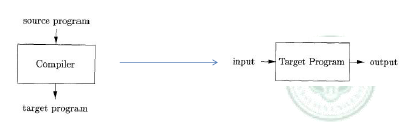
编译器是一个计算机程序,用来把用高级语言编写的源代码转为另一种计算机语言
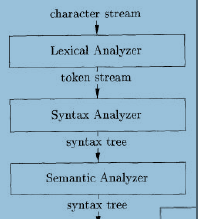
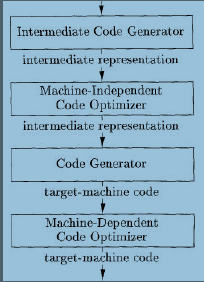
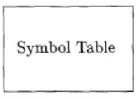
symbol table符号表,分析analysis部分把程序分为多个组成要素,并在这些要素之上加上语法结构,然后使用这个结构来创建改程序的中间表示。分析部分还会收集有关程序的信息,并存在一个成为符号表的的数据结构中。
语法分析
发生在编译步骤中的lexical analyzer此法分析器中
词法单元token:符号表中队与源程序词的解释,格式:
例子:position = initial + rate * 60
position是一个词素,被映射为
+ id表示标识符identifier
+ 1指向符号表的中position对应的条目
"="映射为<=>
一次类推,最终语法单元序列为:
<id, 1> <=> <id, 2> <+> <id, 3> <*> <60>
interpreter 解释器
解释器是另一种常用语言language processor处理器
编译器和解释器相结合
编译器和解释器结合这种情况可能在python,java这种非编译型语言的编译解释过程中存在
- translator是编译器的部分,把源代码编译为平台无关的源代码
- 在virtual machine虚拟机中发生解释,把中间代码转为平台相关的cpu指令
字符串和语言
字母表
符号的任意集合
语言
字母表Σ上的语言,是由Σ中字符组成
的字符串的集合
例如:
Σ={0, 1}
则{001, 100100},{},{1, 11, 111, 1111, …}都是定义
在字母表Σ的语言
语言的运算
语言是一种集合。所以集合的运算也适合语言的运算
语言的基本运算:
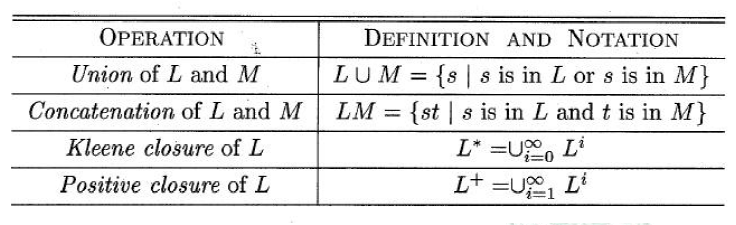
- union并集
- concatenation连接
- kleene closure克林尼闭包
一个语言L的克林尼闭包L*就是L的各次幂(包括0次幂)的并集
- positive closure正闭包
一个语言L的正闭包L*就是L的正次幂(不包括0次幂)的并集
正则语言regular language
正则表达式的递归定义

正则表达式的等价原则

例子