@gzm1997
2018-10-10T02:18:13.000000Z
字数 3642
阅读 4989
dgraph图数据库
dgraph database
schema
dgraph的节点分为两类
- node节点
- value字面量
例如:
- a b是两个人
- a friend b
- a age 12
那么a b是两个节点 12是字面量 那么friend跟age都是谓语 friend指向b b是一个node age指向12 12是一个字面量 那么谓语所处的边为什么有时候指向一个node 有时候指向一个字面量呢 这就是由模式所定义的 或者说模式就是边的定义或者说模式就是谓语的定义
1.添加模式
当我们项添加数据到已有的模式中 我们可以直接添加 但是我们需要添加新数据到还没有存在模式中的时候 可以有两种方式
- 直接添加数据 让Dgraph自己找出其中的模式
- 先添加一个新的模式 然后添加数据
在模式中我们需要定义索引 因为dgraph的函数跟filter过滤器都是只可以应用于添加了索引的谓语 不在模式中添加索引的话 那么各种查询进行不了
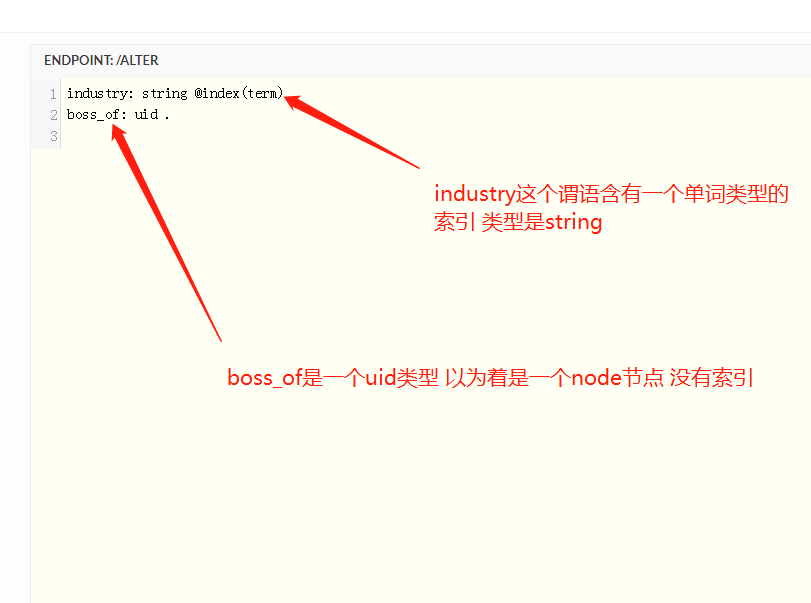
2.查询模式
schema(pred: [name, age, friend, owns_pet]) {typeindex}
输出 很显然下面的输出都是按照谓语一个一个输出这个谓语指向的那个的类型(是node还是字面量) 以及是否具有索引 如果为false就不输出
{"data": {"schema": [{"predicate": "age","type": "int","index": true},{"predicate": "friend","type": "uid"},{"predicate": "name","type": "string","index": true},{"predicate": "owns_pet","type": "uid"}]},"extensions": {"server_latency": {"encoding_ns": 1000000},"txn": {"start_ts": 20,"lin_read": {}}}}
dgraph支持的数据类型
- int 有符号64位整数
- float 双精度浮点数
- string 字符串
- bool 布尔值
- id id是以字符串的形式进行存储的
- dateTime 时间
- geo 几何体
编码
dgraph是使用utf-8进行编码的 一些谓语也是使用字符串来存储的 可以在加上语言标签来定义是什么语言
节点加上语言标签进行声明
"Amit"@en
Amit这个名字是英文
多个语言匹配
@lang1:...:langN
上面这个语法的特点
- 最多只有一个结果返回
- 如果有结果出现在这个语言列表中 那么最左边那部分的匹配结果都会被返回
- 如果没有结果匹配就没有返回 但是如果最后时以.为结尾的话例外 .以为着什么语言都行 匹配上了就可以返回
使用语言pipei匹配来查询一个人的朋友他的朋友名字各种语言都有
{language_support(func: allofterms(name@hi, "अमित")) {name@bn:hi:enagefriend {name@ko:ru:.age}}}
输出
{"data": {"language_support": [{"name@bn:hi:en": "অমিত","age": 35,"friend": [{"name@ko:ru:.": "Michael","age": 39},{"name@ko:ru:.": "상현","age": 24},{"name@ko:ru:.": "Артём","age": 35}]}]},"extensions": {"server_latency": {"encoding_ns": 1000000},"txn": {"start_ts": 58,"lin_read": {"ids": {"1": 6}}}}}
查询格式
其实上面的查询语句一直都是有规矩可循的 但是一直没有注意到
之前我们说到dgraph有两种节点
- node节点
- value字面量
常见的两种形式
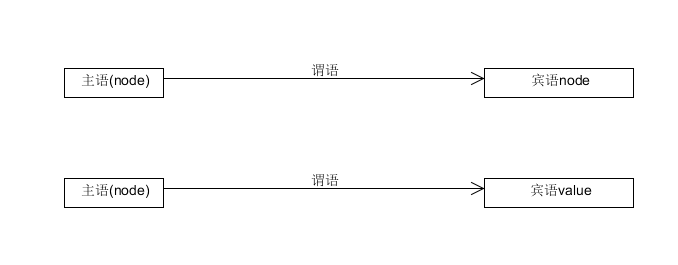
谓语不属于节点
在查询上
- 字面量的查询只需要把字面量的名称写入即可
- node节点的查询需要把指向它的谓语和它的名称一起写入
如下 查询Michael的字面量: name age (这些都是他指向的字面量) 以及他的朋友(他的朋友就是他指向的节点)

所以我们要进一步查询Michael的朋友的宠物 只要在上面的查询语句稍加修改即可
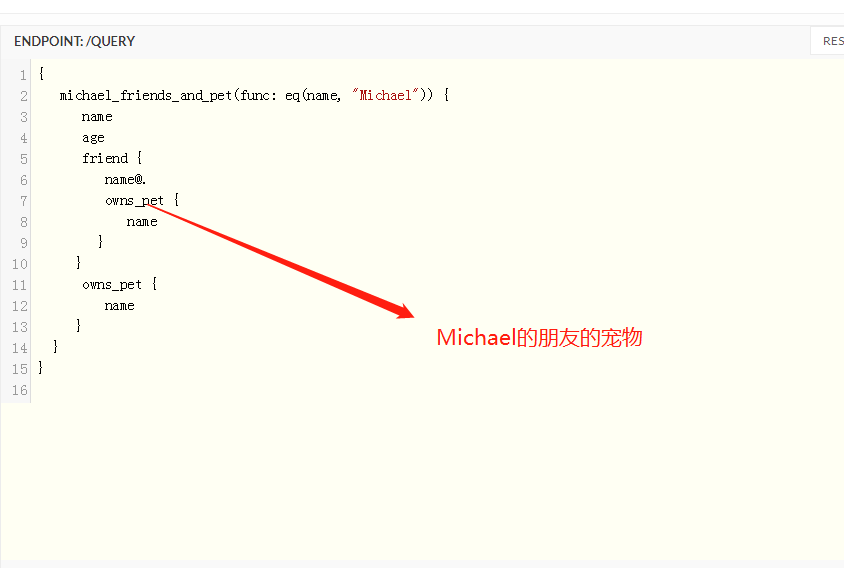
过滤器
常见过滤器
1.节点上的过滤器
allOfTerms(node_name, "term1 ... termN")
节点的名字含有给出的所有单词
anyOfTerms(node_name, "term1 ... termN")
节点的名字函数给出的单词列表中的任意一个单词
2.边上的过滤器
边上的过滤器可以应用到int float string date类型的边上
- eq(edge_name, value) 等于
- ge(edge_name, value) 大于等于
- le(edge_name, value) 小于等于
- gt(edge_name, value) 大于
- lt(edge_name, value) 小于等于

过滤器上可以使用逻辑AND OR NOT将过滤条件联合起来
{michael_friends_and(func: allofterms(name, "Michael")) {nameagefriend @filter(ge(age, 27) AND le(age, 48)) {name@.age}}}
排序
可以使用下面两个关键字进行排序
- orderasc 从小到大排序
- orderdesc 从大到小排序
注意 排序只是在返回的json对象上有效果 在UI的可视化上是没效果的

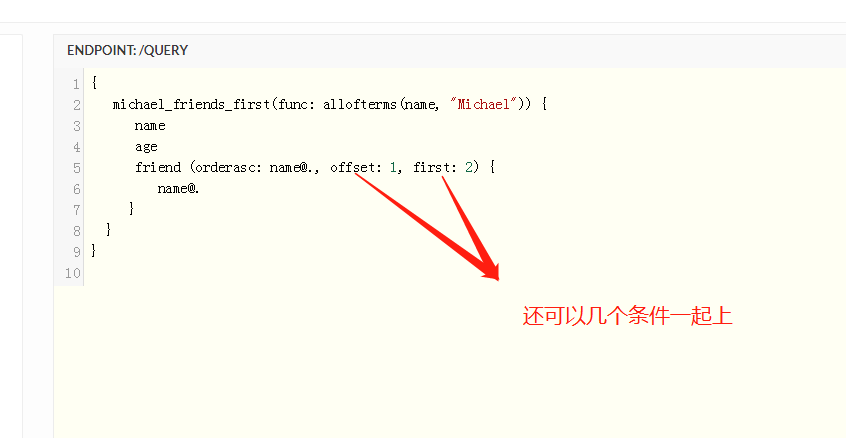
分页
- first: N 只返回前N个结果
- offset: N 跳过前N个结果
- after: uid 返回在这个uid后面的结果
count
dgraph的count用起来挺方便
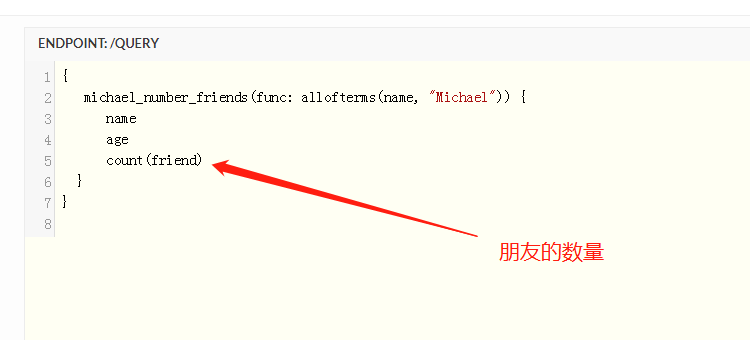
根节点
因为有时候dgraph的图非常大 那么从所有节点开始搜索是很低效的 那么根节点的概念就出现了 从根节点开始搜索
在根节点处 我们是使用func:和一个函数来找到一个初始化的节点集合
但是root节点的那个函数func是不可以接受and or not那些逻辑操作的 所以如果需要在根节点处加上这些逻辑操作需要在后面自己加一个filter过滤器
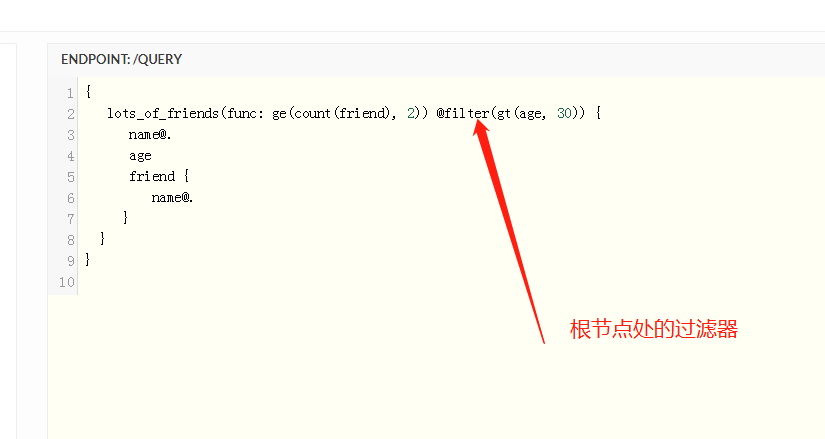
根据谓语(边)查询
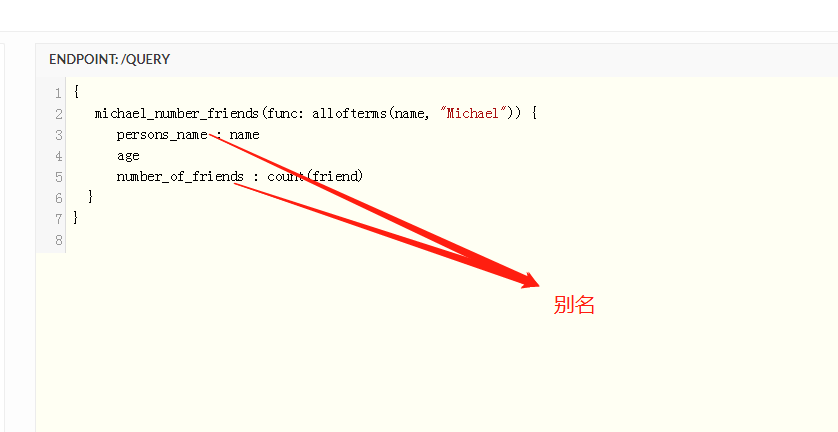
alias别名
别名可以用于设置返回的json对象中key的名字 改成自己想要设置成的别名
级联cascade指令
级联的概念开始真的是有点难以理解 举个例子就容易多了
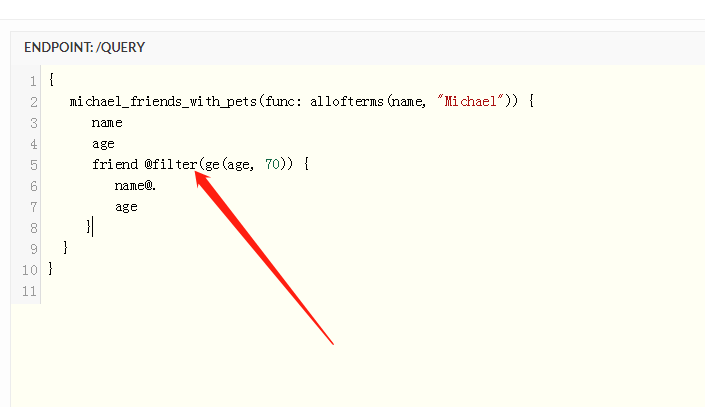
上面的查询是查询Michael年纪大于等于70的朋友 Michael有年纪大于等于70的朋友就直接返回在friend的列表里 如果没有那么friend一项就直接为空
但是加上@cascade之后效果就不一样了
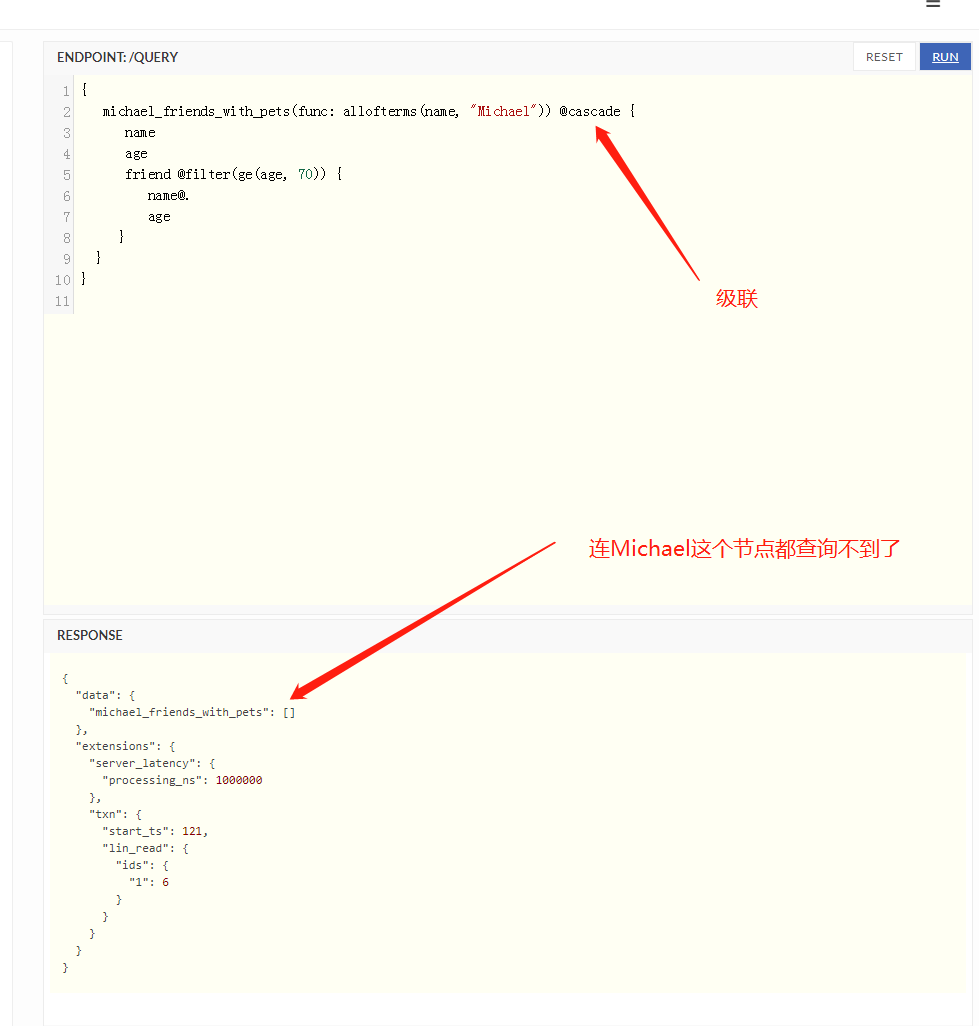
上面加上了@cascade之后 如果Michael如果有年纪大于鞥与70的朋友那么Michael跟她的朋友一起在返回的结果里面 但是如果没有 那么连Michael也不返回
因为级联就相当于强行的逻辑与如果后面的节点不满足要求 那么前面已经满足匹配的节点也不会被返回
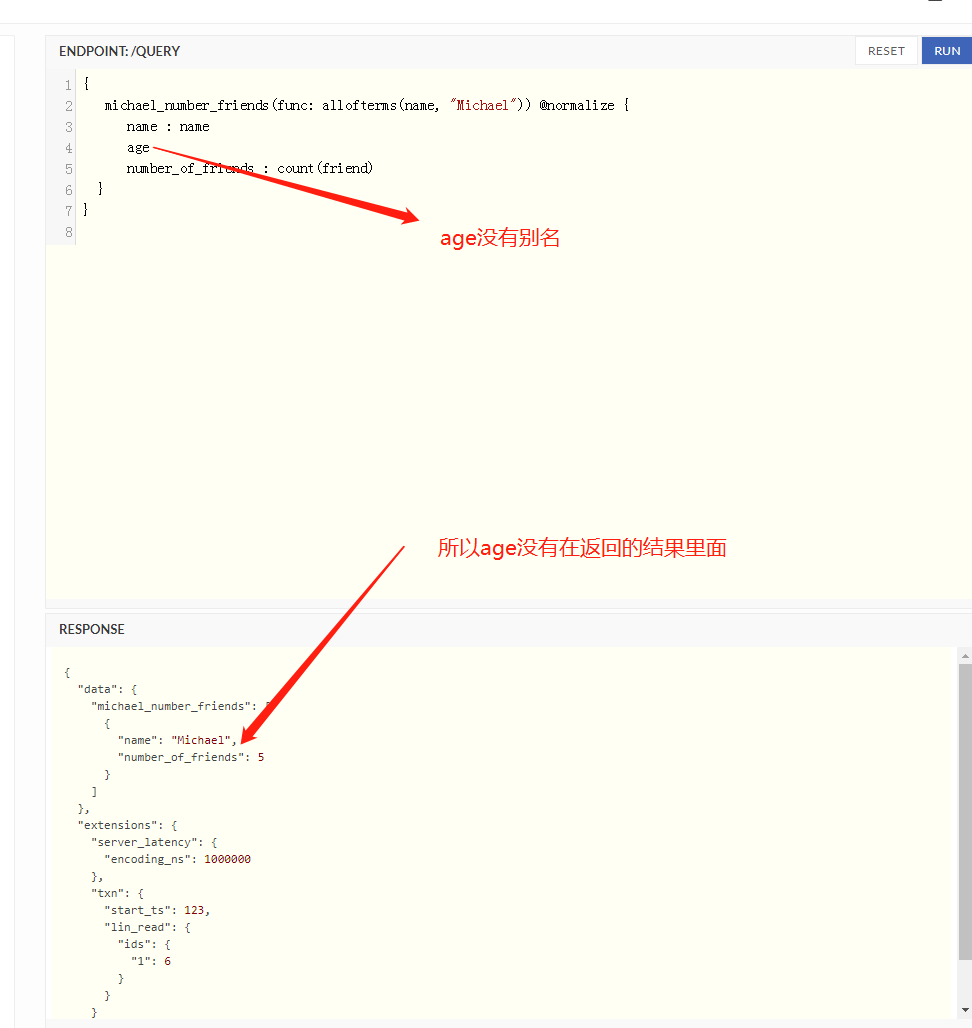
normal指令
@normalize指令
- 只返回带有别名的节点
- 把结果扁平化 去除嵌套
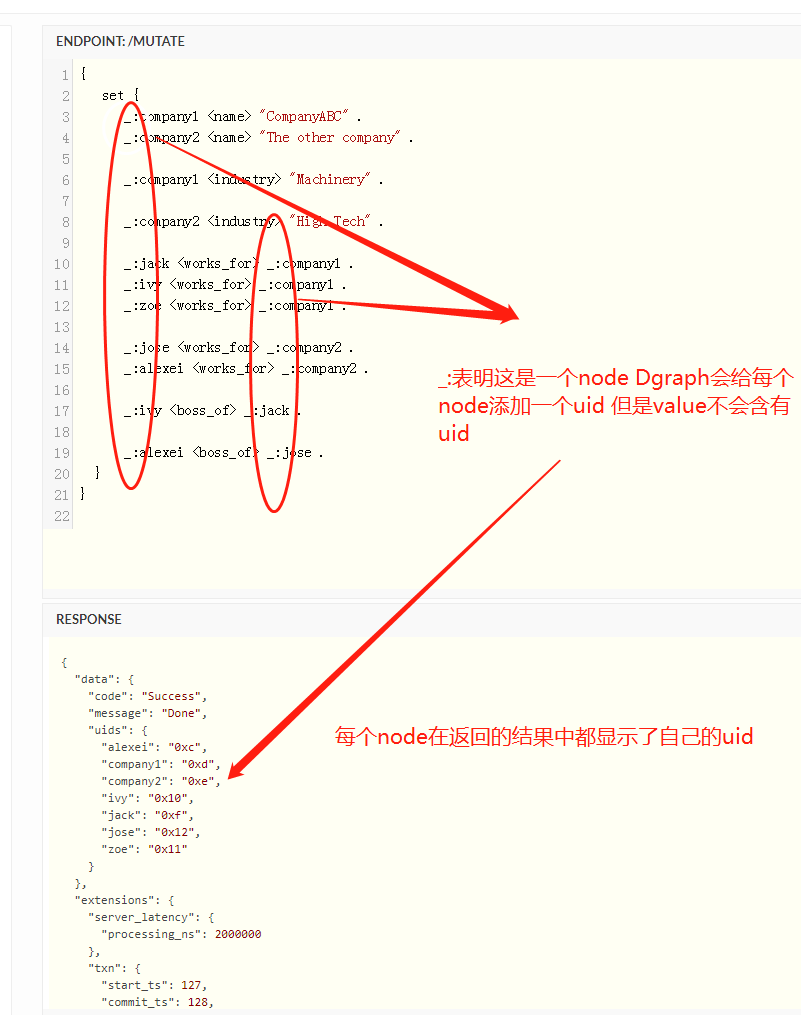
数据突变
数据突变就是修改存储在Dgraph中的图结构
External Identifiers外部标识符
Dgraph是不支持为node设置外部标记符的 所以如果开发人员希望为节点添加一个外部标记符 那么需要自己添加一条边作为外部标记符
语言支持
这个语言标记上面已经减了很多次了 其中中文的标志使用以下来标志
_:myID <an_edge> "某物"@zh-Hans .
反向边
边是有向的一个查询是不可以反向遍历的 有两种方式可以双向进行查询
- 添加反向边到模式中 添加所有的反向边数据
在模式中使用@reverse关键字告诉Dgraph告诉Dgraph总是存储反向边
boss_of: uid @reverse .
整合已有数据
当我们第一批次向数据库中导入了一系列的人物关系数据 第二批次的时候导入了一系列的公司数据 那么问题在于我们怎么把这些人物和公司关联起来呢?
答案肯定是添加新的模式 但是添加新的模式要注意 因为我们肯定不能在新的模式中使用下面
_:sarah <works_for> _:company1 .
因为这样的话会为z这个sarah新建一个uid 而不是我们之前的那个sarah 这是一个新的sarah 正确的做法应该是
<uid-for-sarah> <works_for> <uid-for-company1> .
找到sarah和company的uid根据uid定义这些已存在节点之间的新模式
例子
{set {<0x2> <boss_of> <0xd> .}}
删除数据
删除数据有三种
方式
- /"value" . 根据宾语的node的uid或者宾语中的字面量的值删除一个三元组
- * . 根据给定的一条边删除所有的三元组
- * * . 根据给定的一个node 删除所有的三元组
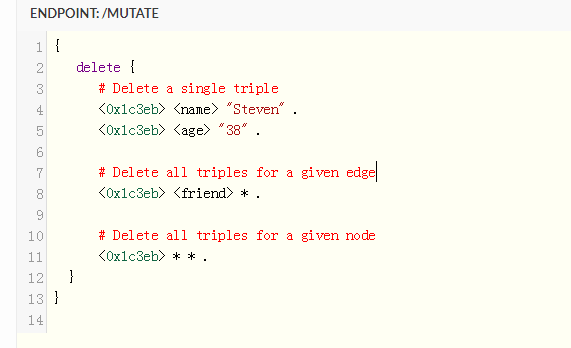
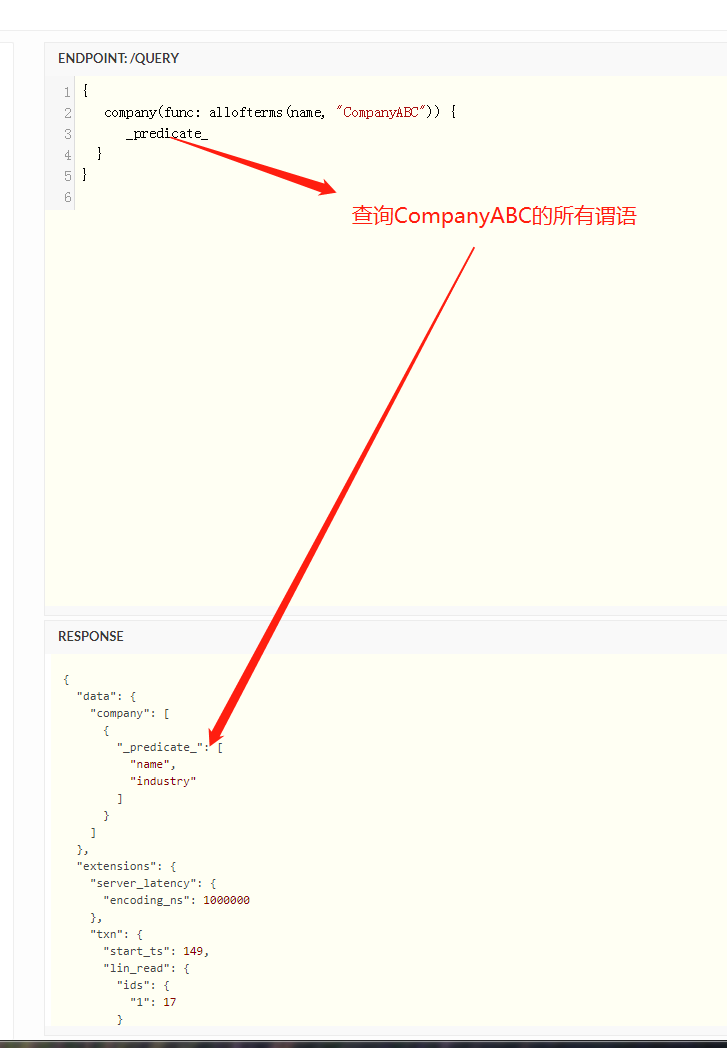
谓语查询
可以根据一个node节点查询这个节点所有的谓语
使用
_predicate_
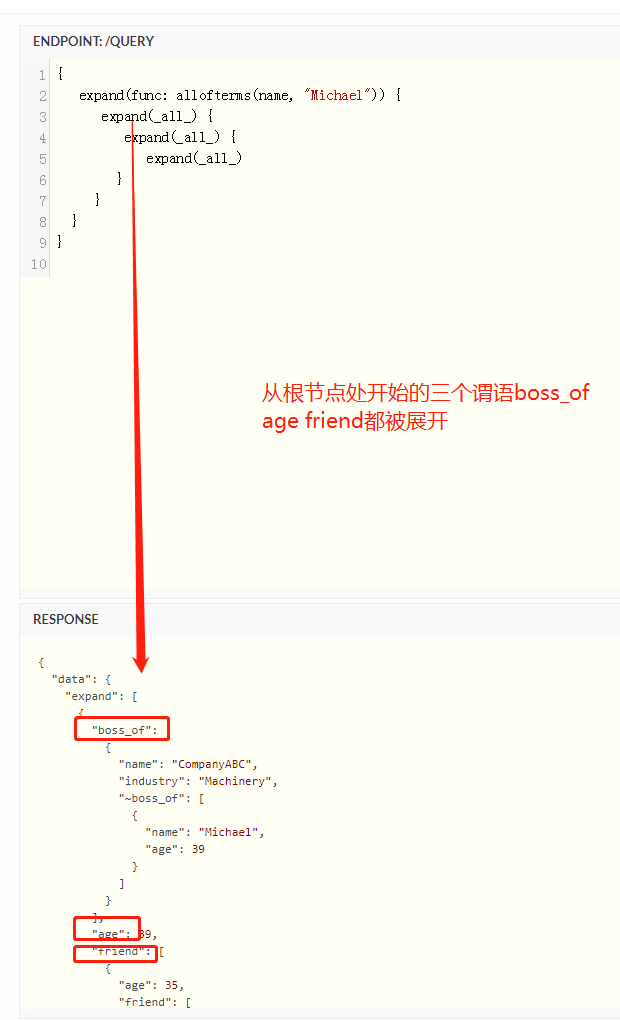
拓展谓语
expand(_all_)
上面是查询所有的谓语 拓展谓语是根据给定的谓语进行深入查询 而不是单纯在返回结果中列出他们
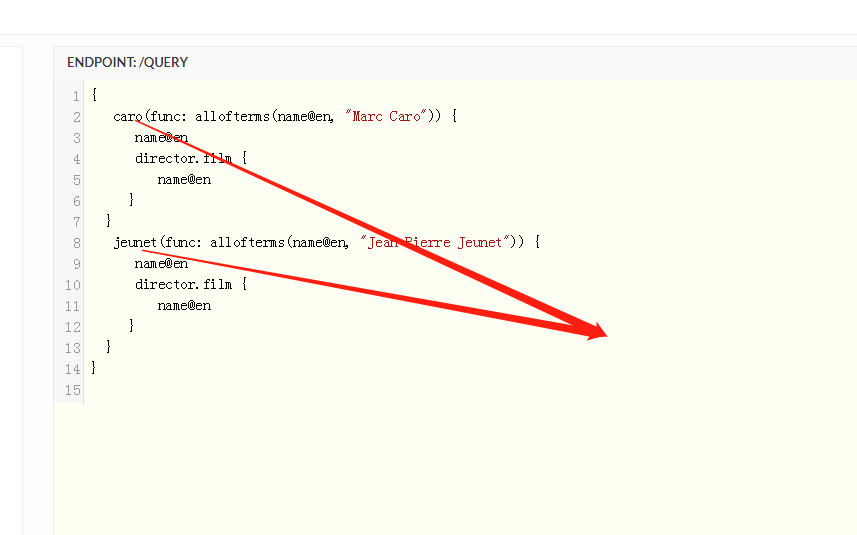
多个查询块
没什么区别 就是多几个查询根节点而已
查询变量
结果可以被存在变量里面 可以在查询的任意一个位置被使用
