@gzm1997
2018-11-05T03:42:37.000000Z
字数 1354
阅读 2062
cayley原理一(获取查询结果)
cayley
其实下面就是cayley使用go的interface实现泛型编程的思想 go没有泛型参数的说法 那时候我没意识到这个 下面说了一通
查询结果的获取
首先我们假定cayley已将我们的查询语句path转化为mongodb的查询语句 现在我们分析cayley是如何从mongodb里面获取查询结果 并且返回给上层的
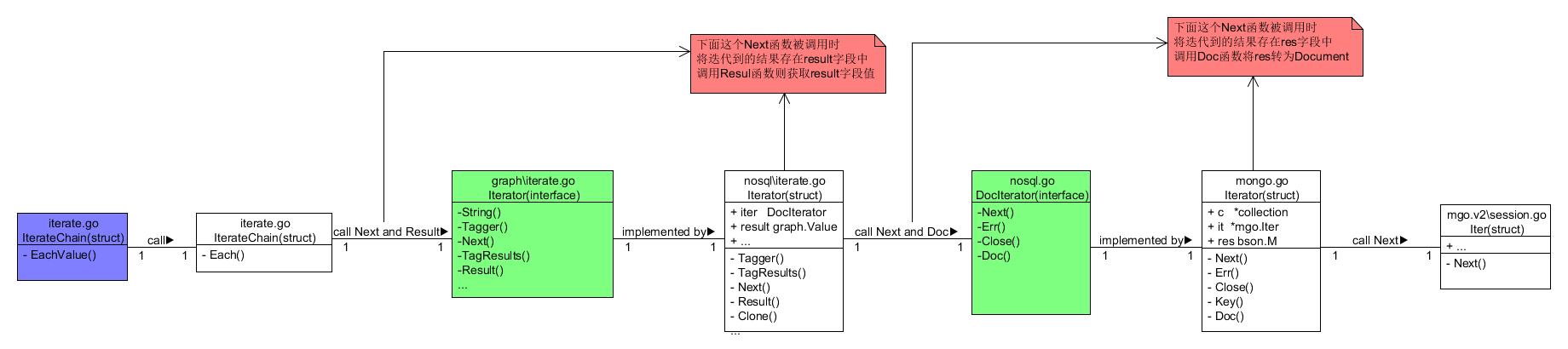
总体的结构如下(只包含从mongodb中获取查询结果 不包含解析为mongodb查询语句)
由cayley官方提供的hello world的查询方式如下
if err := p.Iterate(nil).EachValue(nil, func(value quad.Value) {// ignore}); err != nil {panic(err)}
可以看见是调用了EachValue这个函数 这个函数是属于一个叫做IterateChain结构体的一个方法 如上提最左边的类 上图最左边是我们的顶层调用 越往右是底层调用
为了直观 我们从右边到左边 从底层到高层的调用如下
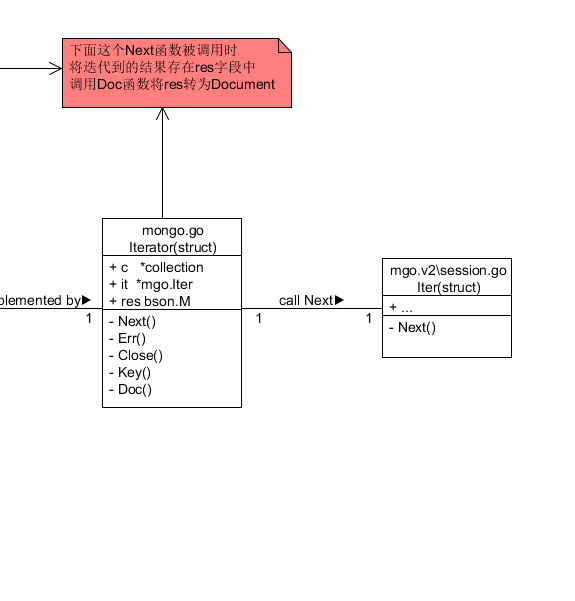
1.mongo.go中的Iterator结构体(称为迭代器1)中调用Next()函数 这个Next()再调用mgo.v2\session.go中Iter结构体中的Next()函数 从而将从mgo中迭代的结果保存在迭代器1中的res字段中 这个字段类型是bson.M(实质上是一个map[string]interface{}类型) 然后迭代器1调用Doc()方法 将res类型转为Document(实质上为map[string]graph.Value)
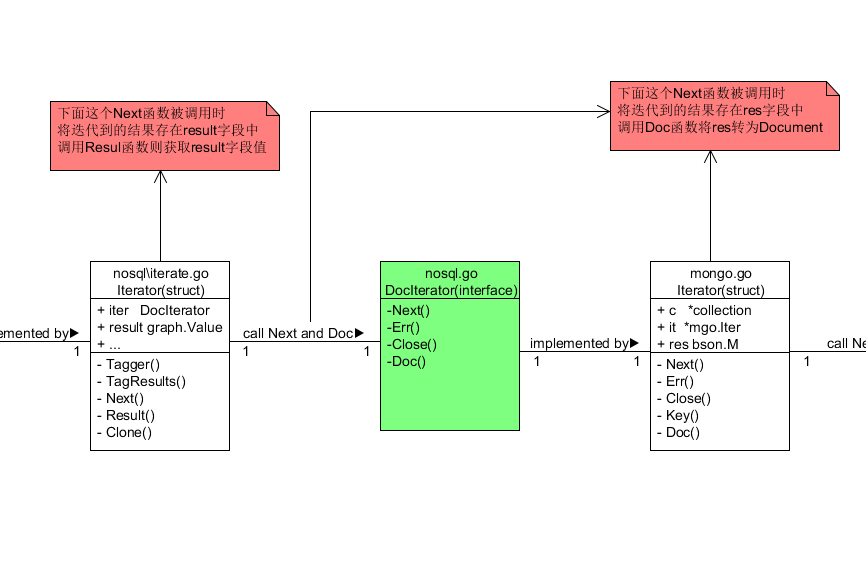
2.nosql\iterate.go中Iterator结构体(称为迭代器2)调用自己的Next()函数 进而调用步骤1中的迭代器1的Next()和Doc()函数完成步骤1的操作 并且转化为Document的结果存进迭代器2中的result字段中 类型是graph.Value
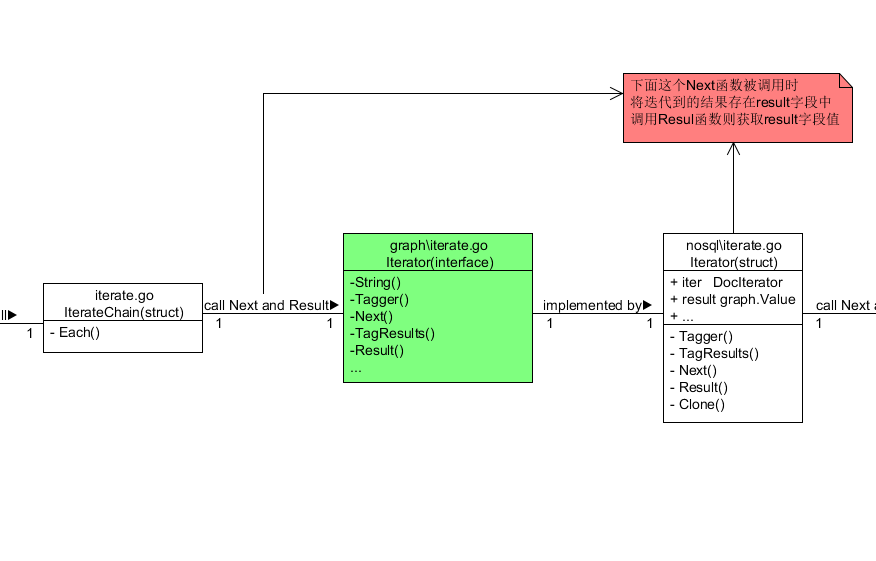
3.iterate.go中的IterateChain结构体(称为迭代链)调用自己的Each()方法 进而 调用步骤2中的迭代器2中的Next()函数完成步骤2中的操作 并且使用迭代器2的Result()函数获取这个保存在迭代器2的Result字段中的结果
使用接口实现多种实现方案
上面图中的两部分绿色非常关键 两部分都是定义了很多方法的接口 我们称最右边的接口为接口1 另一个称为接口2
对于接口1来说
这些包含了若干方法的接口是声明在nosql.go中的DocIterator这个接口中的 并且被nosql\iterate.go中进行调用 在接口的具体实现上我们上面的方案是使用了mongo.go文件中的Iterator结构体实现方式
试想一下:当我们实现另一个新的Iterator迭代器 并且都实现接口1的方法 但是在这些方法的定义上使用其他的nosql数据库进行底层存储 那么我就可以添加一种新的底层存储可选方案了
其实cayley可以使用mysql 还是mongodb bolt redis甚至内存等多种存储方式作为底层存储的原因就是:
其实cayley在sql还是nosql类型方案的选择上就是通过接口2的实现方式不一样来实现的 而nosql方式的底层存储数据库到底选择何种nosql数据库也是通过接口1的实现方式不一样来实现的 sql具体数据库的选择也是类似
