@cww97
2017-11-27T17:29:43.000000Z
字数 5086
阅读 1291
分布式系统
分布式系统
Consistent Hashing
1.1 Meta-discussion
consistent is not a clear algorithm in the book, it is an idea, a tool. Maybe later I can understand this better, mark.
Consistent hashing gave birth to Akamai, before this I do not know Akamai, one of the largest distrubuted computing platform in the world. Its clients include Apple, Facebook, MS, etc. Oh, this is brilliant. BT, which we download movies by, is related to our topic. And the author said cool kids use this kind of hashing for storage. Pretty cool, huh? I am not a kid, and in this way, I am not cool neither.
1.2 Web Caching
Original motivation of consistent Hashing is Web Caching. Firstly, the author tell us how Web Caching works. Store a local copy for rencent visised web pages. When we need to resquest a website over and over again, this is pretty fast and convenient.
After making sure this is a grammatic mistake(see the end). Let us learn more about Web Cache. Web Caching can be shared by many users. If my PC has no Cache for the page which I want, but some one nearby has, then I can use theirs.
The first idea of where cache is supposed to go is each end user's device. However, if tons of users near-by share their Cache, it will be cool: their cache together will be large so we need less request to the server, faster. The auther said this is a daydream.
What we do is to make our dreams come true. It is not easy: the caches are in different machines and we may have some problem on manage the big, slow data on one single machine.
1.3 A Simple Solution Using Hashing
Hash function should have two properties:
easy to calculate: O(1) is the best. The simplest Hash function is just 'mod' a const MOD where MOD is the size of the hash table.
random. Two url should not share the same hash value, which is called 'conflict'. Just like below.

The author did not talk a lot about how to design h(x). In ACM contests, we have many solutions for string hashing(url can be saw as a string). Let me tell a simple one: first we have a prime number P, and each char has its acsii num. Then we get this code:
int h(string s){int ans = 0;for (int i = 0; i < s.size(); i++){ans += power(P, s[i] * i); // P: a prime numberans %= MOD; // MOD: the size of hash table}return ans;}
Using power to make the num large, sometimes ans may be greater than INT_LIMITS(2^31-1). Never mind, after mod operation, it will be in the hash table. Sometimes we do not use mod, C++ STL has a library called 'map', sometimes if we are lazy and the problem is not so strict we may use this to replace the h(s) above. To avoid conflicts, sometimes we have H(h(s)) where H() is the second Hash function for the first Hash funtion's result. That's can strongly avoid the conflicts.
1.4 Consistent Hashing
Consistent Hashing not only hashing urls, but also hashing servers.
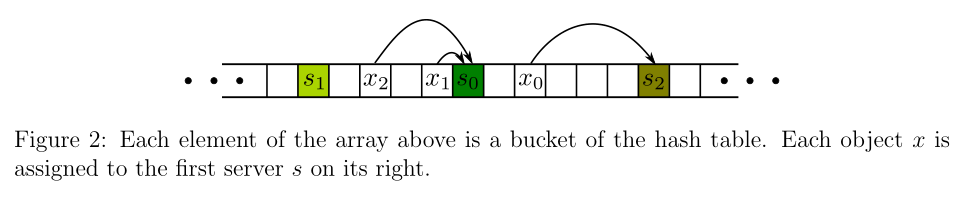
Let us see the graph above, is the i-th server and is the j-th url(both of them has been hashed). One url belongs to one server which first appear on its right.
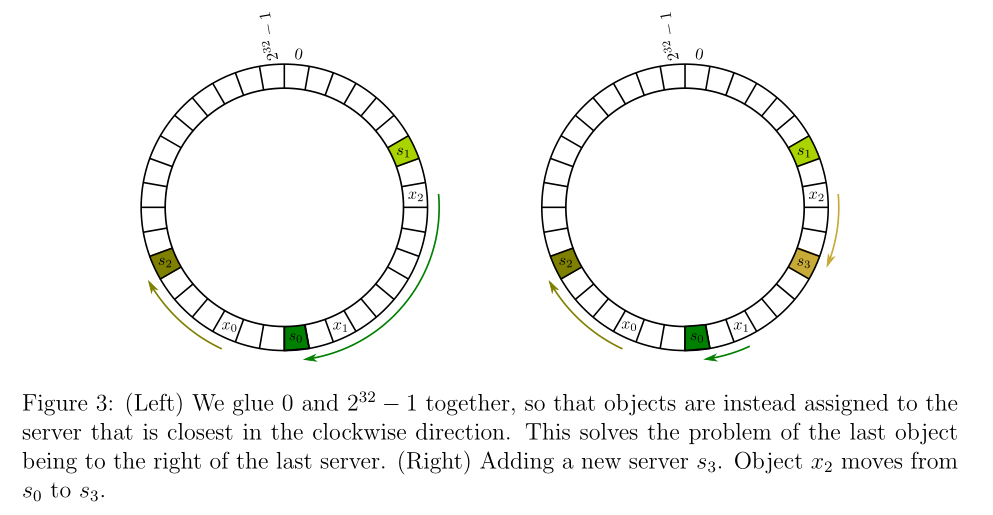
fig3: Let the fig2's array be a circle, then the 'right' turns to 'clockwise'.
Thus n servers partition the circle into n segments, with each server responsible for all objects in one of these segments. If the hash function is good and the data is big enough, each server will hold of the whole.
However, the hash table changes every second. It is simple to image that a new server is added to the local network. the best location it belongs to is the middle point of the longest segment. Then each server's number of url will be more closer to average. In another way, the variance becomes small.
Let us think about the cost of Query and Insert. Query is simple: find which server the url belong and then ask for the server for cache. Inserting an url is still simple: find which server the url belong and then storge the cache into the server. However, inserting a server is not simple as before. See the fig3(right): we insert between and , then half urls which at first belongs to need to change their locations. In anther way, these data need to move from to . This operator is costly.
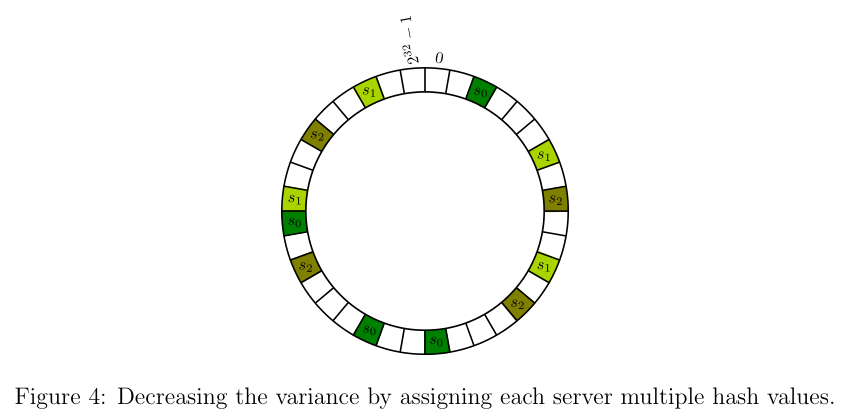
We need to reduce the cost. The author gives us a simple solution: cut the whole hash table into more segments. To realize that, we make one server into k servers, not really, but in hash table, just like the graph above. As an example, k == 4, one server splits into 4. First each segment's length is , now it is , genrally . then the cost of insert operation will reduce k times because the cache we need to transfer become less. The Auther did not give us a strict proof, My math is poor I cannot do it, too. We can see it easily. Last but not least, too much split make it maybe slower, only when a server has too much cache then it need to be splited(orginal saying: make the number of virtual copies).
Summary
The core algorithm of consistant hashing is about distribution. One segment is too big, so we split it into many ones. Cache storged on this server is a lot, but when we cut its segment, we did not its whole, but the . Then the insert become not so costly.
A simple way to reduce cost. At the same time it is brilliant which dig a hole in my head. Great and Good night.
Others
The rest infomation of this paper talk a lot about the course, the history, which do not have much use of understanding the distributed system. So I did not pay much attention.
A Grammatic Mistake
Let us turn to 1.2 Web Caching, there is something which makes me confused. First, let us have a look at paragraph 2:
Caching is good. The most obvious benefit is that the end user experiences a much faster
response time. But caches also improve the Internet as a whole: fewer requests to far away
servers means less network traffic, less congestion in the queues at network switches and Web
servers, fewer dropped packets, etc.
In the second sentence, the author used, 'But also'.I cannot find 'Not only' before, so grammatically speaking, this 'but also' should mean 'but', which means there maybe some disadvantages of Web Cache follow. At last, however, the whole paragraph is talking about the benefit of Web Cache. So, this 'but also' does not mean anything, and I think that this is a mistake.
