@ArrowLLL
2018-01-24T15:48:14.000000Z
字数 8630
阅读 9890
Study-Note : Social LSTM - Human Trajectory Prediction in Crowded Spaces
Study-Note OPTIMAL
中文理解
作为RNN的一种变体,LSTM模型主要用于sequence generation/prediction tasks,用于和时间有关的预测和序列生成等任务,如语音识别,场景分析等。相比于RNN,LSTM有效地解决了梯度爆炸和梯度消失的问题。
Social LSTM则用于处理多个预测任务之间的交互影响。
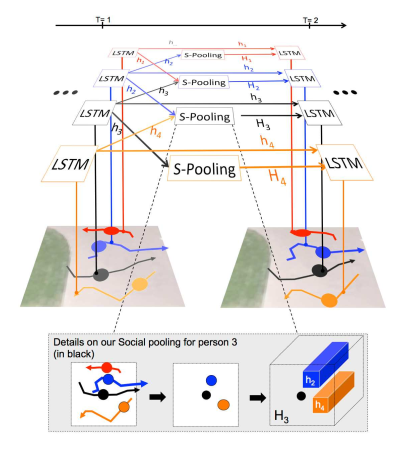
在行人路径预测当中分为两部分, 一是对相邻LSTM的隐藏状态的汇聚,二是位置估计
隐藏状态汇聚
在行人行为分析当中,为每一个行人建立一个LSTM模型,在t与t+1时刻之间加入一个 Social Pooling层,根据空间信息汇聚其他LSTM的state信息后得到一个3维的tensor(两个维度是平面坐标,第三个维度是t时刻的LSTM输出的state向量),输入下一个时刻。以此来汇聚其他LSTM的信息影响当前行人的运动轨迹。
- LSTM模型的隐藏状态 捕获到第 i 个人在第 t 时刻的隐藏状态信息;
通过建立隐藏状态张量 和邻居分享隐藏状态信息 :
给定隐藏状态维度为 以及相邻区域边界大小,对于第 个轨迹我们建立一个代销为 的张量 :
- 表示第 j 个人在第 t-1 时刻从LSTM获得的隐藏状态
- 是一个 indictor函数,检查(x, y) 是否在(m, n) 表示的方格内部(在则返回1,不在返回0);
- 表示第i个人邻界区域内的人员集合
将汇聚得到的张量映射到一个向量,将坐标映射到一个向量
- 是映射函数,使用ReLU增加非线性
- 和 是映射的权重
- LSTM的参数用 表示
位置估计
对于位置预测,则是通过将S-LSTM的输出编码成为二维高斯分布(bivariate Gaussian distribution)的参数,预测得到的新的坐标通过 给出。
t 时刻的隐藏状态用于预测 t+1 时刻的轨迹位置 分布。假定一个二元高斯分布的参数如下 :
- 期望
- 标准差
- 相关系数
这些参数通过一个带有大小的矩阵 的线性层预测得到
在时刻 t 预测的位置坐标 ,通过以下方式得到 :
LSTM模型的参数通过最小化最小化负对数似然损失函数(表示第个轨迹)获得 :
在训练集的所有轨迹中通过最小化损失来训练模型。
模型实现的细节
- 将空间坐标信息转化为64维度的向量再输入LSTM模型;
- 空间汇聚尺度 设置为32,每一个小格使用 的汇聚窗口
- 固定LSTM隐藏层输出状态维度为 128
- 在汇聚LSTM隐藏状态之前将隐藏状态信息使用一个带有ReLU的embedding层转化一下(具体维度多少论文没有说明,猜想还是128,单纯地加一个ReLU即可
- 超参数用交叉验证的方式获得
- 使用均方误差以及0.003的学习率训练模型
- 论文的实验使用Theano + 单个GPU训练
Abstract
- Problem of trajecory prediction can be viewed as a sequence generation task, where we are interested in predicting the feture trajectory of people based on their positions.
- We propose an LSTM model which can learn general human movement and predict their future trajectories.
- Our model outperforms state-of-art methods on some of these datasets.
- Analyzing the trajectories predicted by our model to demonstrate the motion behaviour learned by our model.
Introduction
Most of works are limited by the following two assumptions :
- The use hand-crafted functions to model "interactions" for specific settings rather than inferring them in a data-driven fashion.
- They focus on modeling interactions among people in close proximity to each other, however they do not anticipate interactions that could occur in the more distant future.
In this work, we proposed an approach that can address both challenges through a novel data-driven architecture for predicting human trajectiries in future instants.
We address this issue through a novel architecture which connects the LSTMs corresponding to nearby sequences. In particular, we introduce a "Social" pooling layer which allows the LSTMs of spatially proximal sequences to share their hidden-states with each other.This architecture, which we refer to as the “Social-LSTM”, can automatically learn typical interactions that take place among trajectories which coincide in time.
Model
Problem formulation
- At any time-instant , the person in the scene is represented by his/her xy-coordinates .
- We observe the positions of all the people from time to , and predict their positions of all the people from time to .
Social LSTM
Long Short-Term Memory (LSTM) networks have been shown to successfully learn and generalize the properties of isolated sequence. We have one LSTM for each person in a scene, then connect neighboring LSTMs through a new pooling strategy to share weights across all the sequences.
Social pooling of hidden states
At every time-step, the LSTM cell reveives pooled hidden-state information from LSTM cells of neighbors.
The hidden state of the LSTM at time captures the latent representation of the person in the scene at that instant.
Sharing this representation with neighbors by building a "Social" hidden-state tensor .
Given a hidden-state dimension D and neighborhood size , we construct a tensor for the trajectory :
- is th hidden state of LSTM corresponding to the person at
- is an indictor function to check if is in the cell of the grid
- is the set of neighbors corresponding to person
Embedding the pooled social hidden-stae tensor into a vector and the co-ordinates into
- is an embedding function with ReLU nolinearlity
- and are embedding weights.
- The LSTM weights are denoted by
Position estimation
The hidden-state at time is used to predicted the distribution of the trajectory position at the next time-step . Assuming a bivariate Gaussian distribution parametrized by
- the mean
- standard deviation
- correlation coefficient
These parameters are predicted by alinear layer with a weight matrix .
The predicted coordinates at time are given by
The parameters of the LSTM model are learned by minimizing the negative log-Likelihood loss( for the trajectory) :
Training the model by minimizing this loss for all the trajectories in a training dataset.
Occupancy map pooling
As a simplification, we also eperiment with a model which only pools the co-ordinates of the neighbors(referred to as O-LSTM).
for a person , we modify the definition of the tensor , as a matrix at time centered at the person's position, and call it the occupancy map . The positions of all the neighbors are pooled in this map The element of the map is simply given by :
The vectorized occupancy map is used in place of in last section while learning this simpler model.
Inference for path prediction
Use the predicted position from the previous Social-LSTM cell in place of the true coordinates , the predicted positions are also used to replace the actual coordinates while constructing the Social hidden-state tensor or the occupancy map .
Implementation details
- use an embedding dimension of 64 for the spatial coordinates before using as input to the LSTM
- set the spatial pooling size
- sum pooling window size without overlaps
- fixed hidden-state dimension of 128 for all the LSTM models.
- using an embedding layer with ReLU on top of the pooled hidden-state features, before using them for calculting the hidden state tensor
- hyper-parameters were chosed on cross-validation on a synthetic dataset
- This synthetic was generated using a simulation that implemented the social forces model, containing trajectories for hundreds of scenes with an average crowd density of 30 per frame.
- learning rate = 0.003 and RMS-prop for training the model
- Trained on a single GPU with Theano implementation
Experiments
Human-trajectory datasets
ETH and UCY
Report the prediction error with threedifferent metrics
- Average displacement error - The mean square error(MSE) over all estimated points of a trajectory and the true points.
- Final displacement error - The distance between the predicted final destination and the true final distination and the true final destination at the end of the prediction period
- Average non-linear displacement error - This is the MSE at the non-linear regions of a trajectory.
Leave-one-out approach
Train and validate this model on 4 sets and test on the remaining set. Repeat this for all the 5 sets.
Test
Observe a trajectory for and predict their paths for the next .
At a frame rate of 0.4, this corresponds to observe 8 frames and predicting for the next 12 frames.Comparation
- Linear model
- Collision avoidance
- Social force
- Iterative Gaussian Process
- Our vanilla LSTM
- our LSTM with occupancy maps
Vanilla LSTM outperforms this linear basline since it can extrapolate non-linear cuives. However, this simple LSTM is noticeably worse than the Social Force and IGP models which explicitly model human-human interactions.
Social pooling based LSTM and O-LSTM outperfor the heavily engineered Social Force and IGP models in almost all datasets.
THe IGP model which knows the true final destination during testing achieves lower errors in parts of this dataset.
Social-LSTM ouperforms O-LSTM in the more crowed UCY datasets which shows the advantage of pooling the entire hidden state to capture complex interactions in dense crowds.
Conclusions
Use one LSTM for each trajectory and share the information between the LSTMs through the introduction of a new Social pooling layer. We refer to the resulting model as the "Social" LSTM.
In addition, human-space interaction can be modeled in our framework by including the local static-scene image as an additional input to the LSTM. This could allow jointly modeling of human-human and human-space interactions in the same framework.
