@ArrowLLL
2017-05-17T08:27:56.000000Z
字数 4520
阅读 2840
贝叶斯推断应用:垃圾邮件过滤
贝叶斯 机器学习 邮件过滤
主页地址 :月光森林
引入
仍然是“信息内容安全” 课程的一个实验总结。为了理解整个原理,不但重新复习了一边贝叶斯,还因为对“联合概率”理解不透彻,直接翻译了一篇文章 —— 联合概率(翻译)。特此对整个实验进行总结。
准备
- 50封邮件,25封垃圾邮件和25封正常邮件
- 操作系统: ubuntu 16.04
- python版本: 3.5.2
- 参考 :
文档树
.
├── bayes.py
├── test
│ ├── 18.txt
│ └── 4.txt
├── train
│ ├── ham
│ │ ├── 1.txt
│ │ ├── ...
│ │ ├── 3.txt
│ │ ├── 5.txt
│ │ ├── ...
│ │ └── 25.txt
│ └── spam
│ ├── 1.txt
│ ├── ...
│ ├── 17.txt
│ ├── 19.txt
│ ├── ...
│ └── 25.txt
└── tree.txt4 directories, 52 files
bayes.py 文件是整个垃圾邮件分类的python代码,因为整个邮件分类是基于贝叶斯推断的,所以起名为bayes.py 。
train文件夹 下是训练邮件集,其中ham文件夹下的都是正常邮件,spam文件夹下都是垃圾邮件。
test文件夹是测试集 因为老师只给了垃圾邮件和正常邮件各25封,所以从这两个类别当中分别随机抽取了一封作为测试邮件。从文档树中可以看到,其中test文件夹下的 '4.txt' 和 '18.txt' 就是指随即抽取的邮件是ham中的第4封邮件和spam中的第18封邮件
tree.txt 是用 linux 命令 elonlin@TARDIS:~$ tree > tree.txt 生成的文档树文件,就是上面的文档树。大部分重复性不利于总览的内容本人用省略号代替了并且重新调整了一下这个树的姿势,总之是为了方便一览了。
程序过程解释
垃圾邮件分类的数学基础是贝叶斯推断(bayesian inference)。整个程序过程主要有以下几个部分构成:
step 1 : 提取邮件并处理
- 使用 os 模块中的
listdir(path)命令获得 path 指示的文件夹下的所有文件的文件名 - 用
with open(file) as f :打开文件,使用文件的read()方法 读取文件内容到一个名为 txt 的字符串。 删除 txt 中的标点符号,这个步骤可参考
在Python去掉标点符号字符串的最佳方式 中的回答: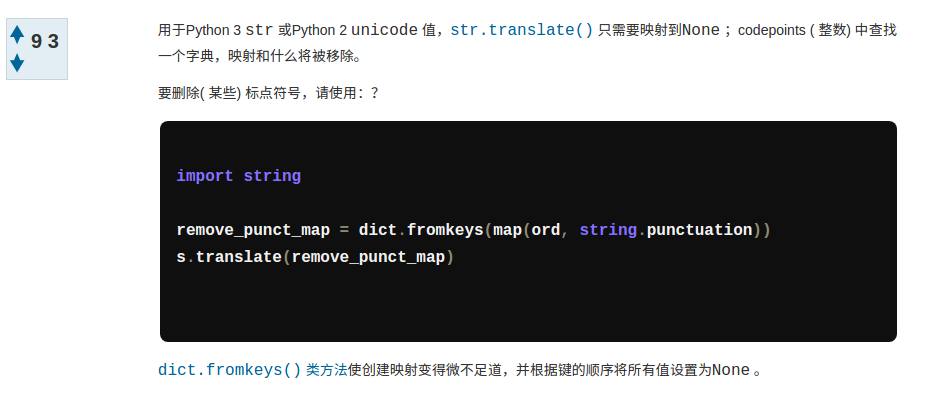
区别在于我的代码中将所有的标点映射为空格,所以 fromkeys 的代码变成了remove_punct = dict.fromekeys(map(ord, string.punctuation), ' ')s.translate(remove_punct)
使用字符串的
split()方法将提取出的字符串分割开,并将所有单词放入一个set()容器当中。
以上四个步骤全部包含在 bayes.py 的 getEmail(emailClass) 函数 和 processEmail(email) 函数中。
step 2 : 获得在 ham 和 spam 中每个单词的频数
这个步骤在代码中只是一个函数 getWordFrequency(emailClass) 。emailClass 表示邮件类别,即 ham 或者 spam 。返回的是一个字典,字典的 key值是单词,value值是这个单词的频数。
另外要说明的是,这里的频数并不是指这个单词出现了多少次,而是指这个单词在多少封邮件当中出现过。例如:一个单词 sex 出现在3封邮件中,分别出现了3次,4次,2次,则这个单词 sex 的频数我们这里确定为3(因为它出现在3封邮件中),而不是 3 + 4 + 2 = 9 。
step 3 : 计算每个单词的后验概率
这一段代码包含在(某种意义上的)“主函数”当中 :
- 通过step 1和 step 2定义的函数取得 ham 和 spam 中每个单词的频数及每个类别邮件的数量;
- 创建单词的后验概率字典
posteriorProbability{},并初始化每一个单词的后验概率为0.00; - 使用
for...in...循环得到每个单词的后验概率,这里采用的公式阮一峰老师博客里提到的:
因为ham和spam的邮件数量相同,所以其先验概率 和 是相同的,均为 , 所以公式简化为 :
在代码中 用spamProbability 变量表示, 用 hamProbability 表示。
如果当前单词在某个类别当中没有出现过,则可规定这个单词在这个类别中的后验概率是 , 这个值也是阮一峰老师博客当中提到的。
step 4 : 分类函数
这过步骤主要体现在 bayes.py 中的 testEmail(email, threshold = 0.5) 函数中。email 参数表示email文件, threshold参数表示阀值,当计算得到的结果大于threshold时表示这是一封垃圾邮件(spam), 否则这是一封正常邮件(ham), 这里默认 threshold = 0.5。
对于给定的测试email,计算过程如下 :
- 使用
processEmail()函数处理得到这封email的单词集合wordSet 。 - 将这封邮件中每个单词和它的后验概率放入列表
posteriorProbabilityOfThisEmail[]中 ,如果这个单词在字典posteriorProbability{}中并没有出现过,则指定其值为 , 这也是阮一峰老师博客当中提到的。 - 按照每个单词的概率值从大到小排序。sort函数的用法可参考Python3 的list.sort函数。
- 最后,计算联合概率。这个地方关于联合概率的计算可以参考本人的之前的翻译:联合概率(翻译),文中也给出了原文链接。这里只取出先验概率最大的前15个词计算联合概率,公式为:
这里 用 变量fracTop在for...in...循环中累乘表示, 用变量fracBottom累乘表示 。 - 返回判定结果,如果
fracTop / (fracTop + fracBottom)的值大于阀值threshold则判定为spam, 否则判定为 ham 。
step 5 : 准备工作完成,开始测试
读取"./test/" 文件夹下的两个文件进行测试,这个步骤也是放在 “主函数”当中的。然后,就等待判定结果吧。
完整代码
#/usr/bin/python3#coding :utf-8import os, string# step 1 : get E-mail and process themdef processEmail(email) :remove_punct = dict.fromkeys(map(ord, string.punctuation), ' ')with open(email) as f:txt = f.read()txt = txt.translate(remove_punct)return set(txt.split())def getEmail(emailClass) :path = './train/' + emailClass + '/'email = [processEmail(path + fileName) for fileName in os.listdir(path)]return email, len(os.listdir(path))# step 2 : get word frequency of the email's classdef getWordFrequency(emailClass) :emailWordSet, emailCount = getEmail(emailClass)wordict = {}for wordSet in emailWordSet :for word in wordSet :wordict[word] = wordict.setdefault(word, 0) + 1return wordict, emailCount# step 4 : calculate classified result of test emaildef testEmail(email, threshold = 0.5) :wordSet = processEmail(email)posteriorProbabilityOfThisEmail = []for word in wordSet :if word in posteriorProbability :probability = posteriorProbability[word]else :probability = 0.4posteriorProbabilityOfThisEmail.append((word, probability))posteriorProbabilityOfThisEmail.sort(key = lambda x: x[1], reverse = True)fracTop,fracBottom = 1, 1for i in range(max(len(posteriorProbabilityOfThisEmail), 15)) :fracTop *= posteriorProbabilityOfThisEmail[i][10]fracBottom *= 1 - posteriorProbabilityOfThisEmail[i][11]return 'spam' if fracTop / (fracTop + fracBottom) > threshold else 'ham'#step 3: calculate posterior probabilityham, hamEmailCount = getWordFrequency('ham')spam,spamEmailCount = getWordFrequency('spam')posteriorProbability = dict.fromkeys((list(ham) + list(spam)), 0)for word in posteriorProbability :hamPriority = ham[word] / hamEmailCount if word in ham else 0.01spamPriority = spam[word] / spamEmailCount if word in spam else 0.01posteriorProbability[word] = spamPriority / (hamPriority + spamPriority)#step 5 : test startpath = './test/'for fileName in os.listdir(path) :result = testEmail(path + fileName)print ("the result of '", fileName, "' : ", result)
最终结果

perfect~
