@77qingliu
2018-05-17T15:24:29.000000Z
字数 4479
阅读 2663
评分卡刻度和实施
信用评分
标准评分卡采用的格式是评分卡的每一个变量都遵循一系列IF-THEN法则。数据记录中每一个变量的值都适用此法则的结果决定了该特定变量所分配的分值。总分就是评分卡中所有变量的贡献的和。下变是一个示例:

标准评分卡的简单形式具有如下几方面的优势。
- 由于各变量得分相加得到最终得分,每个变量对最终得分的影响都清楚明了。
- 每个评分卡变量分别取最高和最低贡献,可以很容易地计算出可能的最高得分和最低得分。
- 分值分配是根据比率的概念,随着分值的降低,违约的比率将提高一倍。例如,一个评分卡可以设计为评分降低20分,违约的比率将提高一倍。
- 因为每一个得分都对应特定的违约比率,所以用评分系统可以很容易的设定信贷政策。因此,信贷提供者可以很容易地控制预期的违约账户比例及其对应的成本。
评分卡刻度
将估计的违约概率表示为p,则估计的正常概率为1-p。可以得到
评分卡设定的刻度值可以通过将分值表示为比率对数的线性表达式来定义。如下:
其中,A和B是常数。方程中的符号可以使得违约概率越低,得分越高。
logistic回归模型计算比率如下:
常数A和B的值可以通过将两个已知或假设的分值代入公式得到。通常,需要两个假设:
- 在某个特定的比率设定特定的预期分值。
- 指定比率翻番的分数(PDO)
首先,设定比率为的特定点的分值为。然后,比率为的点的分值为,代入上述得分公式可以得到如下两个等式:
解上述两个方程中的常数A和B,可以得到:
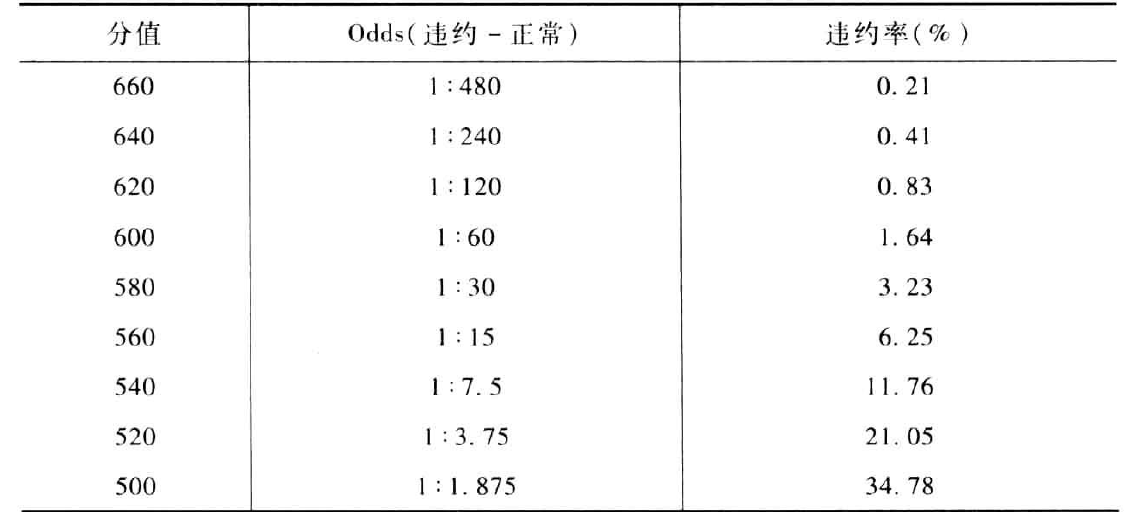
例如,假设想要设定评分卡刻度使得比率为{1:60}(违约比正常)时的分值为600分,PDO=20。然后,给定B=28.85,A=481.86。则可以计算分值为:
通常A被称为补偿,B被称为刻度。
评分卡刻度A和B确定以后,就可以用公式计算比率和违约概率,以及对应的分值。
分值分配
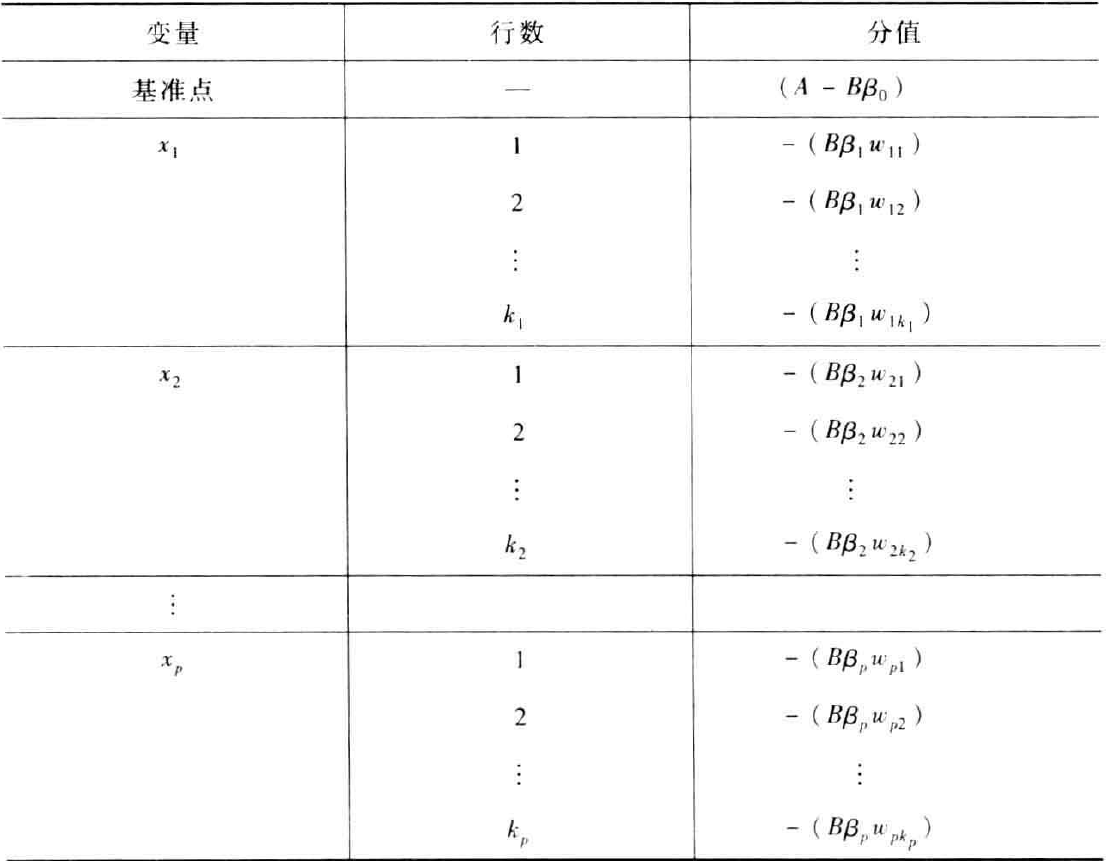
合并公式,可以将评分卡的分值写成一下形式:
由于所有变量都进行了WOE转换,将转换后的变量代入上式,得到:
上式便是最终评分卡的公式。整理成下表:
SAS实施
创建评分卡的基本过程可以总结为以下几个步骤。
- 最终评分卡确定将被纳入模型的变量
- 使用WOE值和模型参数,为不同变量的每一类或每一段相应的分配分值。模型的截距项用于计算评分卡的基准点。
- 每个变量类别或分段分配的分值都根据对应的变量取值范围制成表格。
- 为了便于实施,经常要将评分卡表现为某种程序的形式。如SAS,SQL,C。
下图概括了用SAS实施生成最终评分卡所要采取的步骤。
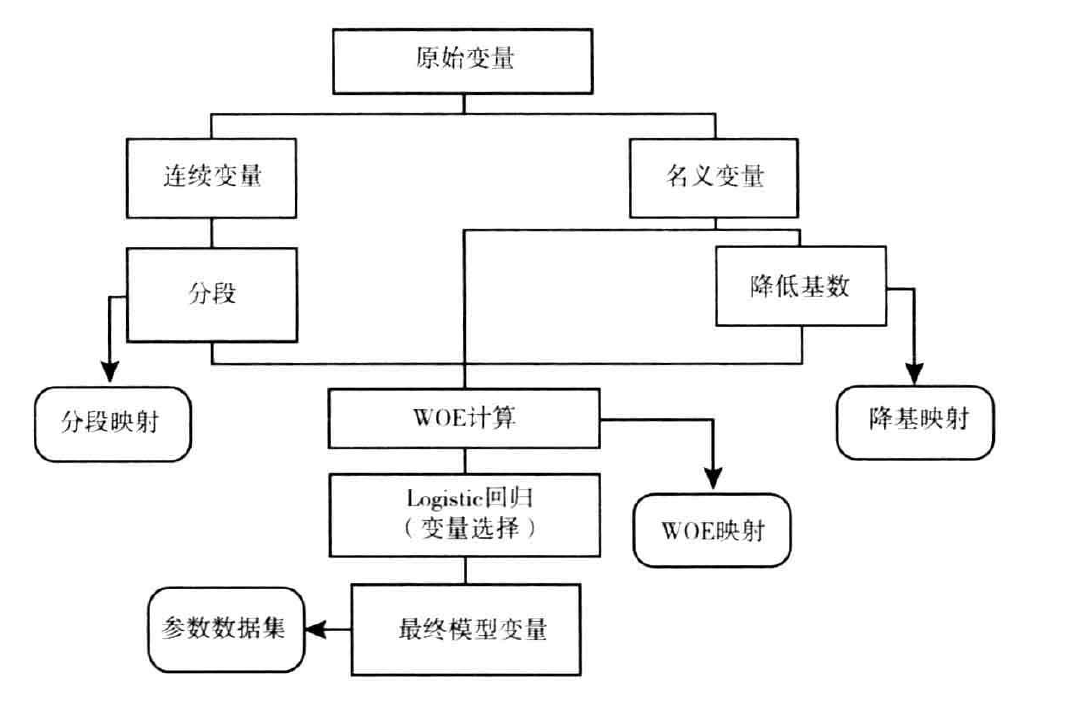
对于字符串和数值型变量,可以分布用宏%DummyGrps和%DummyGrpn进行虚拟变量降基。这两个宏的参数相同,宏的参数如下:

宏%GenSCDS用来生成包含评分卡得分的中间数据集。该数据集将以SAS或者SQL的形式生成不同的评分卡代码,该宏的参数如下:

然后,可以用数据集SCDS重新生成几种形式的评分卡。这里有四个宏,可以生成SAS,SQL和C,以及CSV文件的形式评分代码的评分卡。

下表给出了宏%SCSSasCode的参数:

以下的例子,演示生成创建评分卡代码的全过程:
%EqWBinn(CreditCard, CustAge , 5,CustAge_b , temp , cc.CustAge_Map);%EqWBinn(temp , TmAtAddress, 5,TmAtAddress_b, temp1, cc.TmAtAddress_Map);%EqWBinn(temp1 , CustIncome , 5,CustIncome_b , temp , cc.CustIncome_Map);%EqWBinn(temp , TmWBank , 5,TmWBank_b , temp1, cc.TmWBank_Map);%EqWBinn(temp1 , AmBalance , 5,AmBalance_b , temp , cc.AmBalance_Map);%EqWBinn(temp , UtilRate , 5,UtilRate_b , temp1, cc.UtilRate_Map);/* dummy grouping of nominal variables */%dummyGrps(temp1,ResStatus,temp , cc.ResStatus_map);%dummyGrps(temp ,empStatus,temp1, cc.empStatus_Map);%dummyGrpn(temp1,OtherCC ,temp , cc.OtherCC_Map);/* Calculate the WOE for all independent variables */%CalcWOE(temp , CustAge_b , Status, cc.CustAge_WOE , CustAge_WOE , temp1);%CalcWOE(temp1, TmAtAddress_b, Status, cc.TmAtAddress_WOE, TmAtAddress_WOE, temp );%CalcWOE(temp , CustIncome_b, Status, cc.CustIncome_WOE , CustIncome_WOE , temp1);%CalcWOE(temp1, TmWBank_b , Status, cc.TmWBank_WOE , TmWBank_WOE , temp );%CalcWOE(temp , AmBalance_b , Status, cc.AmBalance_WOE , AmBalance_WOE , temp1);%CalcWOE(temp1, UtilRate_b , Status, cc.UtilRate_WOE , UtilRate_WOE , temp );%CalcWOE(temp , ResStatus_b , Status, cc.ResStatus_WOE , ResStatus_WOE , temp1);%CalcWOE(temp1, EmpStatus_b , Status, cc.EmpStatus_WOE , EmpStatus_WOE , temp );%CalcWOE(temp , OtherCC_b , Status, cc.OtherCC_WOE , OtherCC_WOE , cc.CreditCard_WOE);/***********************************************************//* develop a stepwise logistic regression model with thewoe variables and store the model parameters in a dataset */%let VarList=CustAge_WOE TmAtAddress_WOE CustIncome_WOETmWBank_WOE AmBalance_WOE UtilRate_WOEResStatus_WOE EmpStatus_WOE OtherCC_WOE;proc logistic data=cc.CreditCard_WOEOUTEST=cc.Model_Params ;model Status (event='1')=&VarList /selection =stepwise sls=0.05 sle=0.05;run;/* Generate the Scorecard Points dataset */%let ModelDS=cc.Model_Params;%let DVName=Status;%let Lib=cc;%let BasePoints=600;%let BaseOdds=60;%let PDO=20;%let SCDSName=SCDS;%GenSCDS(&MOdelDS,&Lib, &DVName, &BasePoints, &BaseOdds, &PDO, &SCDSName);/* Use the scorecard points dataset to generate SAS code */%let BasePoints=600;%let BaseOdds=60;%let PDO=20;%let File=C:\Users\chase\Documents\GitHub\data_mining_self_learn\credit scoring\ScorecardDev\Examples;%SCSasCode(SCDS,&BasePoints, &BaseOdds, &PDO, 1,&File);
生成的SAS评分代码的一部分:

设定临界值水平
生成评分卡及其实施代码之后,需要决定如何用其对记录进行筛选和分类。有几种方案,从设定简单的严格临界值到复杂得多阶分类。通常,这被称为评分策略。
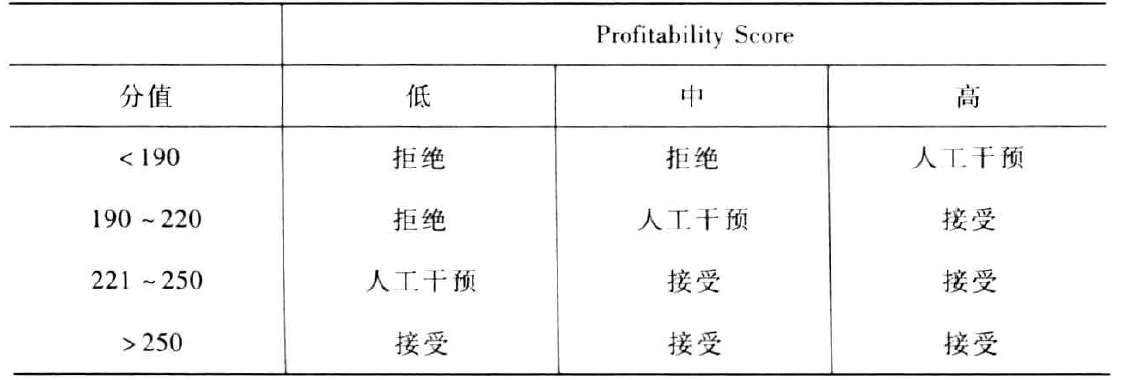
评分策略的复杂程度取决于实施该策略的业务流程。例如,某一信用产品的申请可以根据得分划分为三类,如下表:

这种情况下,必须有相应的业务流程支持中间决策“人工干预”。该流程可能需要申请人提供收入正面或就业状况的正面,该业务还需要有一个流程去审查这些文件并做出合适的决策。
实施信贷策略的业务流程的灵活性决定了通常设定临界值的方案有三种。
- 严格的临界值,如上表的例子所示。通常,临界值的取值是根据在此范围内的预期违约率及其相应成本。其限额可以调整,以适应基于均衡市场份额和可接受的违约水平的特定业务策略。
- 宽松的临界值。这种临界值的设定方法与严格的临界值相似。但是,评分之后,可以用其他没有出现在评分卡中的变量为客户增加额外的分值。
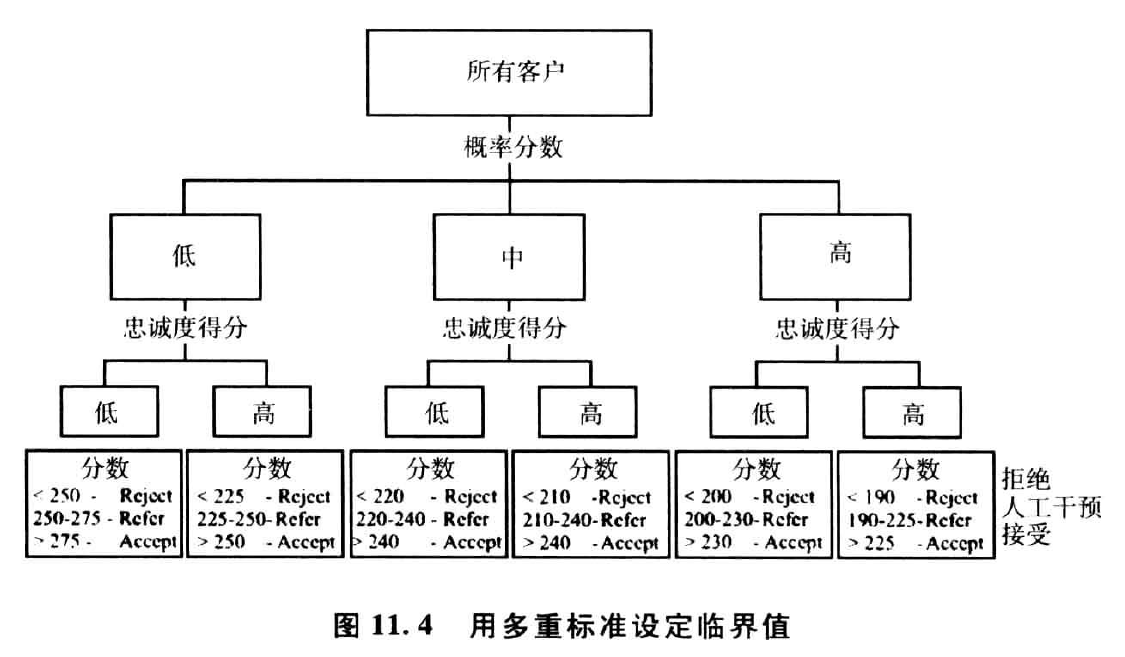
- 多重标准临界值,也被称为矩阵策略。这种情况下,可以用一个或多个没有出现在评分卡中的变量建立一个临界层。这个临界层可以表现为一个简答的表或决策树,如下表所示: